[C/C++ -STL]vector底层实现机制刨析-程序员宅基地
技术标签: c++ 1024程序员节 链表 STL 数据结构
一、vector底层实现机制刨析
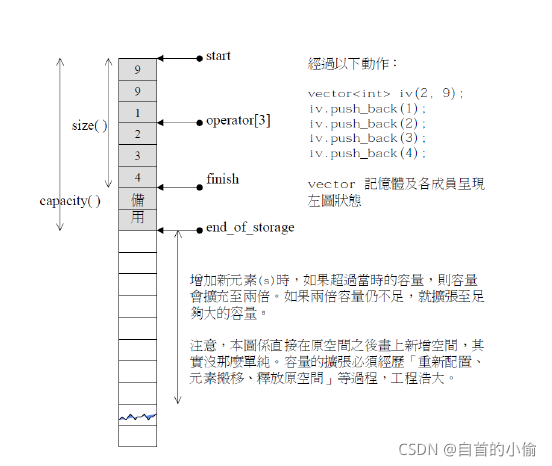
通过分析 vector 容器的源代码不难发现,它就是使用 3 个迭代器(可以理解成指针)来表示的:
其中statrt指向vector 容器对象的起始字节位置;
finish指向当前最后一个元素的末尾字节
end_of指向整个 vector 容器所占用内存空间的末尾字节。
如图 演示了以上这 3 个迭代器分别指向的位置
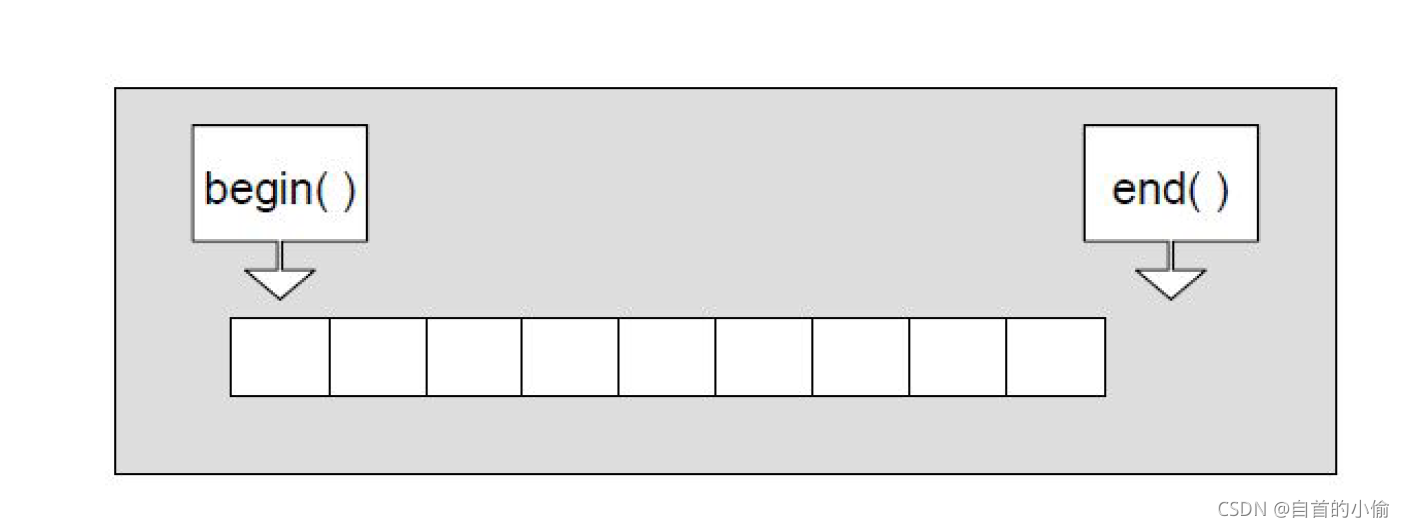
如图 演示了以上这 2个迭代器分别指向的位置
在此基础上,将 3 个迭代器两两结合,还可以表达不同的含义,例如:
start 和 finish 可以用来表示 vector 容器中目前已被使用的内存空间;
finish 和 end_of可以用来表示 vector 容器目前空闲的内存空间;
start和 end_of可以用表示 vector 容器的容量。
二、vector的核心框架接口的模拟实现
1.vector的迭代器实现
typedef T* Iteratot;
typedef T* const_Iteratot;
Iteratot cend()const {
return final_end;
}
Iteratot cbegin()const {
return start;
}
Iteratot end() {
return final_end;
}
Iteratot begin() {
return start;
}
vector的迭代器是一个原生指针,他的迭代器和String相同都是操作指针来遍历数据:
- begin()返回的是vector 容器对象的起始字节位置;
- end()返回的是当前最后一个元素的末尾字节;
2.reserve()扩容
void reserve(size_t n) {
if (n > capacity()) {
T* temp = new T [n];
//把statrt中的数据拷贝到temp中
size_t size1 = size();
memcpy(temp, start, sizeof(T*) * size());
start = temp;
final_end = start + size1;
finally = start + n;
}
}
当 vector 的大小和容量相等(size==capacity)也就是满载时,如果再向其添加元素,那么 vector 就需要扩容。vector 容器扩容的过程需要经历以下 3 步:
- 完全弃用现有的内存空间,重新申请更大的内存空间;
- 将旧内存空间中的数据,按原有顺序移动到新的内存空间中;
- 最后将旧的内存空间释放。
这也就解释了,为什么 vector 容器在进行扩容后,与其相关的指针、引用以及迭代器可能会失效的原因。
由此可见,vector 扩容是非常耗时的。为了降低再次分配内存空间时的成本,每次扩容时 vector 都会申请比用户需求量更多的内存空间(这也就是 vector 容量的由来,即 capacity>=size),以便后期使用。
vector 容器扩容时,不同的编译器申请更多内存空间的量是不同的。以 VS 为例,它会扩容现有容器容量的 50%。
使用memcpy拷贝问题
reserve扩容就是开辟新空间用memcpy将老空间的数据拷贝到新开空间中。
假设模拟实现的vector中的reserve接口中,使用memcpy进行的拷贝,以下代码会发生什么问题?
int main()
{
bite::vector<bite::string> v;
v.push_back("1111");
v.push_back("2222");
v.push_back("3333");
return 0;
}
问题分析:
- memcpy是内存的二进制格式拷贝,将一段内存空间中内容原封不动的拷贝到另外一段内存空间中
- 如果拷贝的是自定义类型的元素,memcpy即高效又不会出错,但如果拷贝的是自定义类型元素,并且
自定义类型元素中涉及到资源管理时,就会出错,因为memcpy的拷贝实际是浅拷贝。
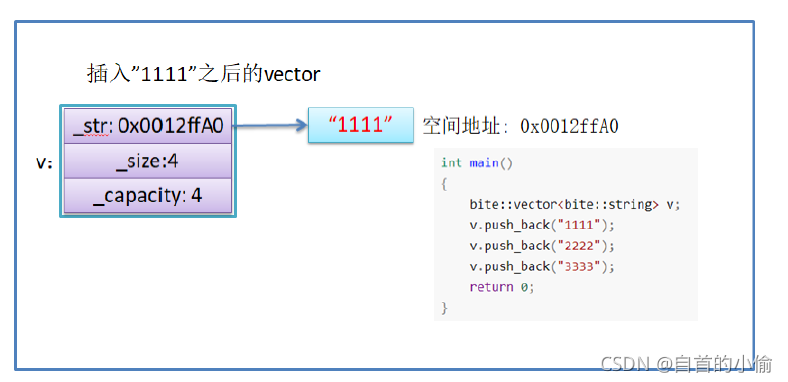
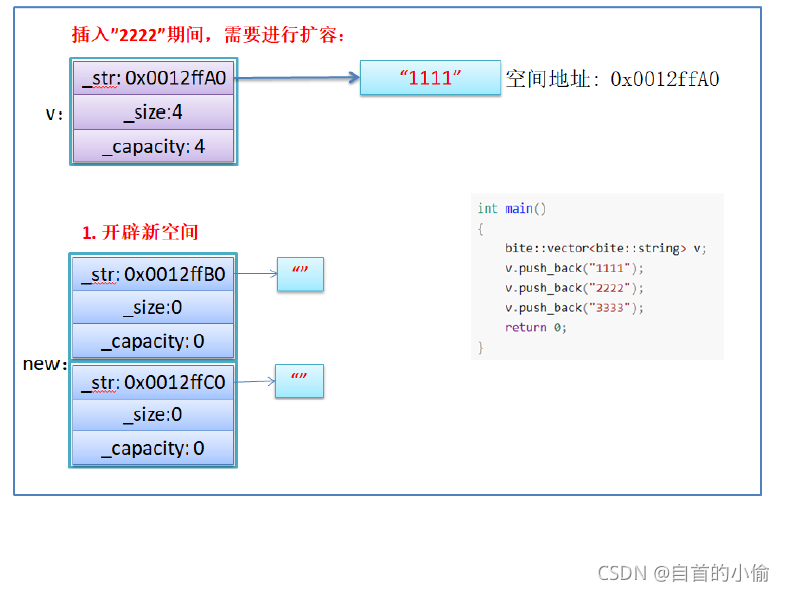
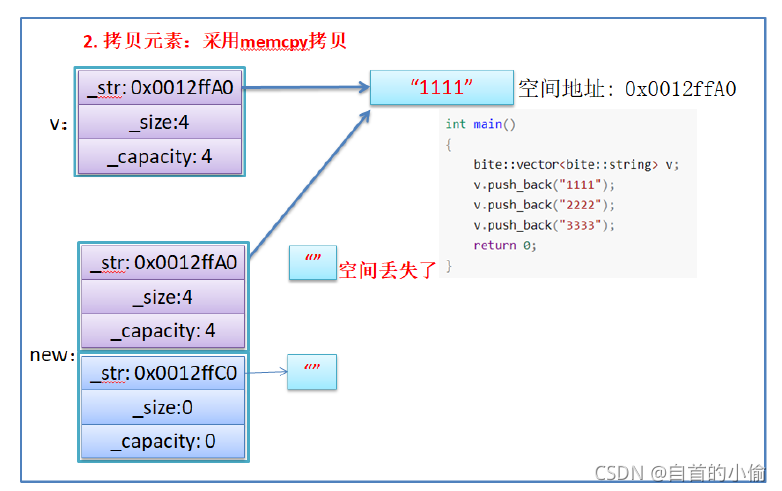
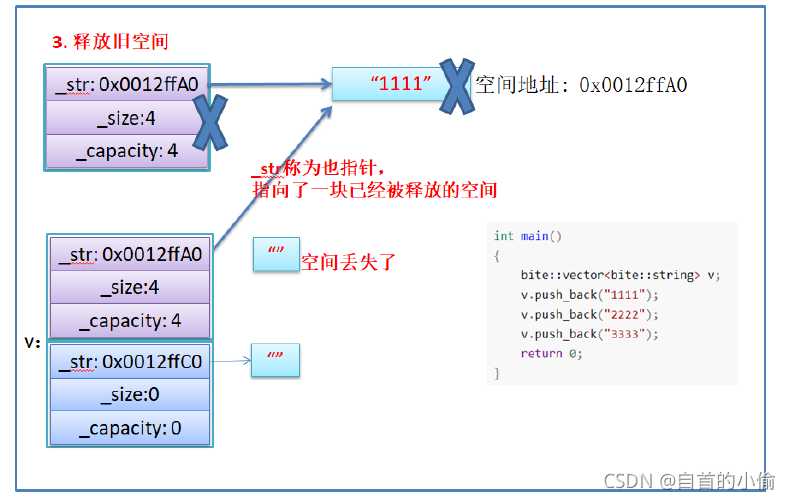
结论:如果对象中涉及到资源管理时,千万不能使用memcpy进行对象之间的拷贝,因为memcpy是浅拷贝,否则可能会引起内存泄漏甚至程序崩溃。
3.尾插尾删(push_back(),pop_back())
void push_back(const T&var) {
if (final_end ==finally) {
size_t newcode = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcode);
}
*final_end = var;
++final_end;
void pop_back() {
final_end--;
}
插入问题一般先要判断空间是否含有闲置空间,如果没有,就要开辟空间。我们final_end==finally来判断是否含有闲置空间。如果容器含没有空间先开辟4字节空间,当满了后开2capacoity()空间。在final_end部插入数据就行了。对final_end加以操作。
4.对insert()插入时迭代器失效刨析
Iteratot insert(Iteratot iterator,const T&var) {
assert(iterator <= final_end && iterator >= start);
size_t pos = iterator - start;
if (final_end == finally) {
size_t newcode = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcode);
}
//插入操作
auto it = final_end;
while (it >= start+pos) {
*(it+1)=*it;
it--;
}
*iterator = var;
final_end++;
return iterator;
}
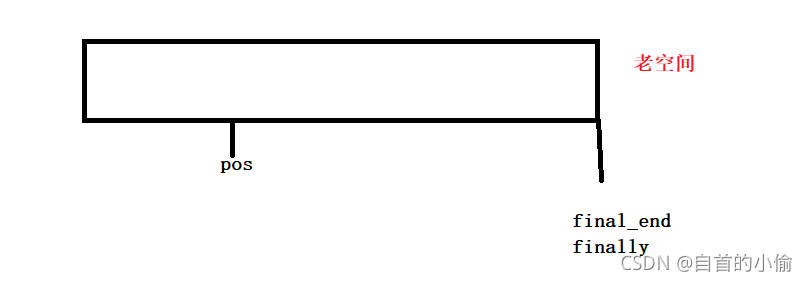
假设这是一段vector空间要在pos插入数据,但是刚刚好final_end和final在同一位置,这个容器满了,要对这这个容器做扩容操作。首先对开辟和这个空间的2呗大小的空间

接着把老空间数据拷贝到新空间中释放老空间。

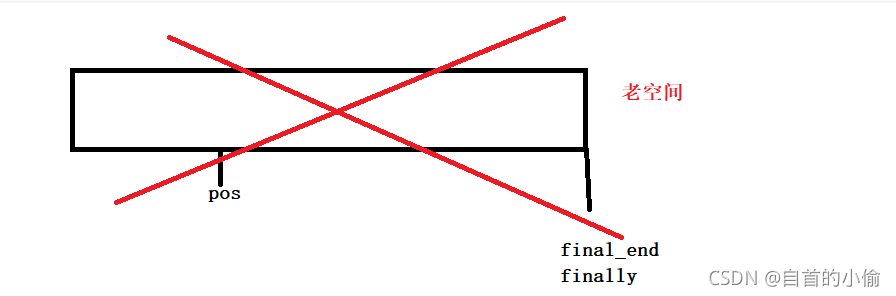
由于老空间释放了pos指向的内存不见了。pos指针就成了野指针。
这如何解决呢就是在老空间解决之间保存这个指针,接着让他重新指向新空间的原来位置。
而insert()函数返回了这个位置迭代器这为迭代器失效提供了方法,这个方法就是重新赋值。让这个指针重新指向该指向的位置。
5.对erase()数据删除时迭代器失效刨析
Iteratot erase(Iteratot iterator) {
assert(iterator <= final_end && iterator >= start);
auto it = iterator;
while (it <final_end) {
*it = *(it+1);
it++;
}
final_end--;
return iterator;
}
vector使用erase删除元素,其返回值指向下一个元素,但是由于vector本身的性质(存在一块连续的内存上),删掉一个元素后,其后的元素都会向前移动,所以此时指向下一个元素的迭代器其实跟刚刚被删除元素的迭代器是一样的。
以下为解决迭代器失效方案:
#include <vector>
#include <iostream>
using namespace std;
int main()
{
int a[] = {
1, 4, 3, 7, 9, 3, 6, 8, 3, 3, 5, 2, 3, 7};
vector<int> vector_int(a, a + sizeof(a)/sizeof(int));
/*方案一*/
// for(int i = 0; i < vector_int.size(); i++)
// {
// if(vector_int[i] == 3)
// {
// vector_int.erase(vector_int.begin() + i);
// i--;
// }
// }
/*方案二*/
// for(vector<int>::iterator itor = vector_int.begin(); itor != vector_int.end(); ++itor)
// {
// if (*itor == 3)
// {
// vector_int.erase(itor);
// --itor;
// }
// }
/*方案三*/
vector<int>::iterator v = vector_int.begin();
while(v != vector_int.end())
{
if(*v == 3)
{
v = vector_int.erase(v);
cout << *v << endl;
}
else{
v++;
}
}
/*方案四*/
// vector<int>::iterator v = vector_int.begin();
// while(v != vector_int.end())
// {
// if(*v == 3)
// {
// vector_int.erase(v);
// }
// else{
// v++;
// }
// }
for(vector<int>::iterator itor = vector_int.begin(); itor != vector_int.end(); itor++)
{
cout << * itor << " ";
}
cout << endl;
return 0;
}
一共有四种方案。
方案一表明vector可以用下标访问元素,显示出其随机访问的强大。并且由于vector的连续性,且for循环中有迭代器的自加,所以在删除一个元素后,迭代器需要减1。
方案二与方案一在迭代器的处理上是类似的,不过对元素的访问采用了迭代器的方法。
方案三与方案四基本一致,只是方案三利用了erase()函数的返回值是指向下一个元素的性质,又由于vector的性质(连续的内存块),所以方案四在erase后并不需要对迭代器做加法。
智能推荐
LSM-Tree 与 RocksDB_rocksdb 和lsmtree的区别-程序员宅基地
文章浏览阅读1.3k次。冥冥之中,接触到了不同于关系数据库的NoSQL Key-Value存储引擎RocksDB,懵懵懂懂、充满好奇,google一点,满眼皆是LSM-Tree,头晕眼花、若即若离,便有了这篇文章,一起与大家分享这趟探险之旅。LSM-Tree(Log-Structured-Merge-Tree)LSM从命名上看,容易望文生义成一个具体的数据结构,一个tree。但LSM并不是一个具体的数据结构,也不是一..._rocksdb 和lsmtree的区别
计算机专业毕设java选题参考_软件工程专业与算法结合的毕业设计题目计算机视觉方向java-程序员宅基地
文章浏览阅读3.9k次。人员管理、彩票管理、业务人员管理、银行管理、地区管理、系统备份、交接班管理、申购管理、出票管理、退票管理、兑奖管理、彩票盘点(自动生成数据,根据A生成B的数据)、现金盘点、流水账信息、多账号登录。人员管理、图书类别管理、图书管理、库存管理、ISBN查询(Http接口、JSON)、采购管理(流程)、出库管理(流程)、入库管理(流程)、销售管理、退货管理、财务明细。枸杞树管理、减枝管理、温度管理、施肥管理、器具管理、弄务工管理、晾晒管理、用户信息、包装库存、出库、入库、预订信息、留言信息、前台。_软件工程专业与算法结合的毕业设计题目计算机视觉方向java
JSTL 标签大全详解_jstl标签-程序员宅基地
文章浏览阅读10w+次,点赞124次,收藏539次。(尊重劳动成果,转载请注明出处:http://blog.csdn.net/qq_25827845/article/details/53311722 冷血之心的博客)关注微信公众号(文强的技术小屋),学习更多技术知识,一起遨游知识海洋~目录一、JSTL标签介绍1、什么是JSTL?2、JSTL标签库:3、使用taglib指令导入标签库:4、core标签库常用标签:..._jstl标签
Java调用shell脚本及参数传递_java给shell传数组变量-程序员宅基地
文章浏览阅读2.3k次。Java调用shell脚本及参数传递需求脚本示例执行代码封装工具类最后需求项目需求:由于Python没有提供Http请求的接口,而是以脚本的方式调用,Java需要调用pyhon脚本得到结果返回写入文件,然后Java再读取写入的文件,拿到结果页面展示。坑:这种方式适合单线程模式,不是个多个请求并发,写入的文件是固定的,并发情况下,第一的请求如果读取的是第二次请求的结果,就会有问题。脚本示例Java代码不是直接调用python脚本,而是先调用shell脚本,shell脚本再调用python脚本,Ja_java给shell传数组变量
【R语言(一)】R 和 RStudio的安装与初步使用-程序员宅基地
文章浏览阅读7.9k次,点赞10次,收藏69次。R是一种流行的统计软件和编程语言,用于数据分析和可视化。它是一个开源的软件,拥有庞大的社区支持和丰富的扩展包,可运行在各种操作系统上,如Windows、Mac和Linux。R被广泛应用于数据科学、统计学、机器学习和其他相关领域的研究和实践中。以下是R的一些主要特点:数据分析和可视化:R可以轻松地导入、整理和分析数据,然后将结果以各种方式可视化,如绘制图表、创建热图等。R还提供了许多常见的统计分析方法,如线性回归、ANOVA、聚类分析等。编程语言:R是一种完整的编程语言,具有各种编程结构和数据类型。_rstudio
VB6-该部件的许可证信息没有找到的解决方法_vb licenses-程序员宅基地
文章浏览阅读9.2k次。VB6添加控件时提示 该部件的许可证信息没有找到,将以下文件保存为注册表文件并导入Windows Registry Editor Version 5.00[HKEY_LOCAL_MACHINE\SOFTWARE\Classes\Licenses] @="Licensing: Copying the keys may be a violation of established copyrights._vb licenses
随便推点
Linux系统部署可视化数据多维表格APITable并实现无公网IP远程协同办公-程序员宅基地
文章浏览阅读7.9k次,点赞105次,收藏108次。Linux系统部署可视化数据多维表格APITable并实现无公网IP远程协同办公
FFMPEG 最简滤镜filter使用实例(实现视频缩放,裁剪,水印等)_filters_descr-程序员宅基地
文章浏览阅读1w次,点赞3次,收藏20次。FFMPEG官网给出了FFMPEG 滤镜使用的实例,它是将视频中的像素点替换成字符,然后从终端输出。我在该实例的基础上稍微的做了修改,使它能够保存滤镜处理过后的文件。在上代码之前先明白几个概念: Filter:代表单个filter FilterPad:代表一个filter的输入或输出端口,每个filter都可以有多个输入和多个输出,只有输出pad的filter称为source_filters_descr
C++ vector容器的常用用法_c++ vector修改数据可以直接赋值吗-程序员宅基地
文章浏览阅读7.6k次,点赞23次,收藏93次。vector可以说是一个动态数组,它可以存储任何类型的数据,包括类!使用vector需包含头文件#include< vector >.定义一、不带参数// 定义了一个int类型的容器vector<int> v1;// 定义了一个double类型的容器vector<double> v2;注意事项:容器可以使用数组方式获取它的值 和 给它赋..._c++ vector修改数据可以直接赋值吗
万字长文,深度解析SpringMVC 源码,让你醍醐灌顶!!-程序员宅基地
文章浏览阅读4.1k次,点赞11次,收藏92次。文末可以领取所有系列高清 pdf。大家好,我是路人,这是 SpringMVC 系列第 16 篇。本文将通过阅读源码的方式带大家了解 springmvc 处理请求的完整流程,干货满满。目录1..._springmvc源码分析
kdump核心崩溃信息存储到SSH服务器-程序员宅基地
文章浏览阅读752次。1、配置测试机和SSH服务器之间的免密钥登录:测试机生成密钥#ssh-keygen -t rsa将/root/.ssh/id_rsa.pub中的内容拷贝到SSH服务器的/root/.ssh/authorized_keys文件中,并修改文件权限为600;2.、编辑测试机的/etc/kdump.conf,注释其他内容,并在文件末尾添加:ssh [email protected] sshkey /root/.ssh/id_rsa path /sshkdump core_collect_核心崩溃信息存储到ssh服务器
java财务对账系统设计_对账系统设计-程序员宅基地
文章浏览阅读1.4k次。更多支付内容请移步个人站:YKBLog.top对账整体设计从整体来看,按照时序维度的先后,系统对账主要分为三阶段的工作。分别是数据准备、数据核对和差错处理。数据准备细分一下,又分为文件获取、文件解析、数据清洗。在对账专业概念中,数据核对和差错处理又叫轧账和平账。具体设计脑图如下:check-arch.png对账各个模块设计数据准备数据准备,顾名思义,我们需要把对账所需的全部数据,接入到我们的对账系..._java 对账实战思路