用Python写网络爬虫,从最基础到精通
”python爬虫“ 的搜索结果
python爬虫学习笔记-scrapy框架(1) python scrapy 爬虫 python爬虫学习笔记-scrapy框架(1) python scrapy 爬虫 python爬虫学习笔记-scrapy框架(1) python scrapy 爬虫 python爬虫学习笔记-scrapy框架(1) python ...
主要介绍了python爬虫如何爬取网页数据并解析数据,帮助大家更好的利用爬虫分析网页,感兴趣的朋友可以了解下
选择一个主题,用Python语言编写一个网络爬虫程序,将文字和图像等信息抓取到MySQL中保存,(如果有图片数据,图片数据可以只在数据库存放路径,图片资源存储到文件夹)。

可以直接下载整站的图片 代码中使用多线程进行批量下载 代码中相关的内容已经加了注释 下载的同学应该可以自行修改里面的代码了
爬取企查查网站上公司的工商信息,路径大家根据自己情况自行修改,然后再在工程路径下创建个company.txt,里面输入想要爬取的公司名,就会生成该公司的工商信息网页。
打开cmd输入以下命令即可,如果python的环境在C盘的目录,会提示权限不够,只需以管理员方式运行cmd窗口。因为目录关系,在D盘建立了一个叫做爬虫的文件夹,然后保存信息,注意文件...python爬虫入门基础代码实例如下。
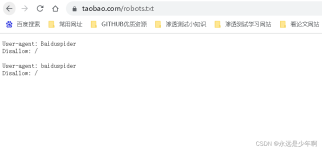
python爬虫_python爬虫详解_python爬虫_


python 爬虫入门ppt
标签: python
很好的资源,适合想入门 python 爬虫的同学,讲解很细,重点突出。
利用Python来实现的爬虫,高效且可靠。
使用python 写爬虫,简单的一些爬虫脚本
python爬虫学习 scrapy框架 爬虫学习 scrapy python爬虫学习 scrapy框架 爬虫学习 scrapy python爬虫学习 scrapy框架 爬虫学习 scrapypython爬虫学习 scrapy框架 爬虫学习python爬虫学习 scrapy框架 爬虫学习python...
python爬虫入门教程(非常详细),全网最细的Python爬虫教程
python网络爬虫【Python+人工智能+大数据分析】 python网络爬虫,用python写网络爬虫,达内智能网络编程,0基础学习,学习智能课,简单好学
详细内容Cookie,指某些网站为了辨别用户身份、进行session跟踪而...在python中它为我们提供了cookiejar模块,它位于http包中,用于对Cookie的支持。通过它我们能捕获cookie并在后续连接请求时重新发送,比如可以实...
爬虫简介安装及配置
如果你在使用 Python 爬虫时遇到了 HTTP 状态码 403,这意味着你的爬虫被服务器拒绝了。有很多原因可能会导致这种情况,例如: 服务器的安全设置禁止了你的 IP 地址访问 服务器需要你提供身份验证凭据(例如用户名和...


爬虫就是一个自动化数据采集工作,你只需要告诉它需要采取哪些数据,给它一个url,就可以自动的抓取数据。其背后的基本原理就是爬虫模拟浏览器向目标服务器发送http请求,然后目标服务器返回响应结果,爬虫客户端...
今天我们要向大家详细解说python爬虫原理,什么是python爬虫,python爬虫工作的基本流程是什么等内容,希望对这正在进行python爬虫学习的同学有所帮助! 前言 简单来说互联网是由一个个站点和网络设备组成的大网,...


python爬虫,比较基础,适合初学者,Main.py里的初始URL可以更换成你想要挖掘的网站
python爬虫文件
标签: 爬虫
python爬虫-第一阶
推荐文章
- 手写一个SpringMVC框架(有助于理解springMVC) 侵立删_springmvc可以用来写安卓后端吗-程序员宅基地
- 线性判别分析LDA((公式推导+举例应用))_lda推导-程序员宅基地
- C# 结构体(Struct)精讲_c# struct-程序员宅基地
- 支付宝Wap支付你了解多少?_阿里wap支付-程序员宅基地
- Java计算器编写,实现循环输入_java简易计算器可使用户多次输入-程序员宅基地
- 【多维Dij+DP】牛客小白月赛75 D-程序员宅基地
- Android之内存优化与OOM-程序员宅基地
- Azure Machine Learning - 视频AI技术_azure ai 視頻索引器-程序员宅基地
- 个人知识管理软件使用感受-程序员宅基地
- WWDC2019 ------深入理解App启动_wwdc app启动-程序员宅基地