一OneHotEncoder独热编码 1.1 OneHotEncoder独热编码原理 2.1. 为什么要独热编码OneHotEncoder? 2.3 独热编码优缺点 2.4什么情况下(不)用独热编码? 2.5 什么情况下(不)需要归一化? 二 Label Encoder标签...
”独热编码“ 的搜索结果
数据科学家Rakshith Vasudev简要解释了one hot编码这一机器学习中极为常见的技术。 你可能在有关机器学习的很多文档、文章、论文中接触到“one hot编码”这一术语。本文将科普这一概念,介绍one hot编码到底是...
One-Hot编码(独热编码)
独热编码是指将分类变量转换为二进制向量的过程。它适用于那些没有自然顺序的分类变量,如颜色、国家、产品类别等。独热编码通过创建一个新的二进制特征来表示原始变量的每个可能取值,其中只有一个特征为1,其余...
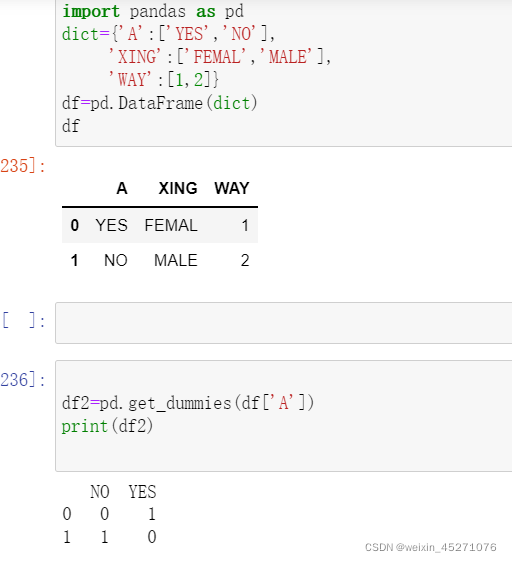
该列中包含了标签中的所有类别: from sklearn.preprocessing import OneHotEncoder enc = OneHotEncoder(sparse = False) result = enc.fit_transform(data[[41]]) #41指的是列标为41的那一列数据 ...
在上一篇博客中介绍了数值型数据的预处理但是真实世界的数据集通常都含有分类型变量(categorical value)的特征。当我们讨论分类型数据时,我们不区分其取值是否有序。比如T恤尺寸是有序的,因为XL>...
One-Hot编码,又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。 One-Hot编码是分类变量作为二进制向量的表示。这首先要求将分类值...
python使用sklearn中的MultiLabelBinarizer函数将多标签的分类变量进行独热编码(One-Hot Encode Features With Multiple Labels)
scatter_(input, dim, index, src)将src中数据根据index中的索引...用于将数据转换为 one hot 独热编码时,代码如下 def to_one_hot(mask, n_class): """ Transform a mask to one hot change a mask to n * h*...
One-Hot编码,又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效,One-Hot编码是分类变量作为二进制向量的表示。这首先要求将分类值映射...
对于独热编码的使用,有一点是额外需要注意的,那就是对于二分类离散变量来说,独热编码往往是没有实际作用的。不过需要注意的是,对于sklearn的独热编码转化器来说,尽管其使用过程会更加方便,但却无法自动创建...
函数声明: to_categorical(y, num_classes=None, dtype=‘float32’) 作用:将整型标签转为onehot。y为int数组,num_classes为标签类别总数,大于max(y)(标签从0开始的)。 返回:如果num_classes=None,返回len(y...
独热编码便是解决这个问题,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。 如自然编码为:0,1 独热编码为:10,01 可以理解为对有m
比如 sex:[“male”, “female”] country: [‘china’,’USA’,’Japan’] 正常数字量化后: “male”, “female”用0,1表示; ‘china’,’USA’,’Japan’用0,1,2表示。 现在有3个样本: ...
山鸢尾变色鸢尾维吉尼亚鸢尾001最终向量为0 0 1 表示种类是维吉尼亚鸢尾为什么要使用独热编码,原因如下独热编码可以很好的表示分类数据的,而许多机器学习与深度学习的任务就是实现各种回归模型分类任务,而且独热...
dummiesNewData = pandas.get_dummies( newData, columns=[‘症状’], prefix=[‘症状’], prefix_sep=’_’ ) # 注意陷阱哇 在给新的观测数据进行转换时,一定要加上下面的代码 newData[‘症状’] = newData[‘症状...
一、独热编码 当我们在机器学习做特征工程时,如果某个categorical特征具有多个符号值,则不可能对具有这种特征的数据进行训练,而独热编码是解决这个问题的一种方法。比如我们有一个特征是protocol_type有三个值...
独热编码是指将离散型的特征数据映射到一个高维空间中,每个可能的取值都对应于高维空间的一个点,在这些点上取值为1,其余均为0,因此独热编码也被称为“一位有效编码”或“One-of-K encoding”。回到一开始的例子...
通常需要处理的数值都是稀疏而又散乱地分布在空间中,然而,我们并不需要存储这些大数值,这时可以用独热编码。 例如:我们需要处理4维向量空间,当给一个特征向量的第n个特征进行编码时,编码器会遍历每个特征向量...
这里针对的是处理二维矩阵: # -*- coding: utf-8 -*- import numpy as np from keras.utils import to_categorical def _OneHot_encode(): data = np.array([[0, 1, 2], [3, 4, 5], ...
今天开始刷牛客上的python题目,遇到一道题。 import numpy as np a = np.repeat(np.arange(5).reshape([1,-1]),10,axis = 0)+10.0 b = np.random.randint(5, size= a.shape) c = np.argmin(a*b, axis=1) ...

学习sklearn和kagggle时遇到的问题,什么是独热编码?为什么要用独热编码?什么情况下可以用独热编码?以及和其他几种编码方式的区别。 首先了解机器学习中的特征类别:连续型特征和离散型特征 拿到获取的原始...
直接上代码: v=torch.Tensor([[1],[2],[3]]) >>> v tensor([[1.], [2.], [3.]]) >>> v.size(0) 3 >>> n=v.size(0) >>> one_hot = torch.zeros(n,10).long() ...>...
#对于数值变量:使用均值或中位数进行插补。 #对于分类变量:使用常见众数进行插补,这里主要使用众数进行插补空值 df['Gender'].fillna(df['Gender'].value_counts().idxmax(),inplace=True) df['Gender'].value_...

数据处理时有时需要将离散特征进行独热编码或者哑变量编码。两者的区别如下所示 上述图片引用自 https://www.cnblogs.com/lianyingteng/p/7792693.html 两者区别似乎不是很大。 LabelBinarizer 将标签矩阵二值化 ...

1.处理文本数据 神经网络不会接收原始的文本作为输入,它只能处理数值型张量。...由于大多数场景中单独对字符进行编码就会失去文本字符之间本来的关系,所以大多时候对单词编码较多。 2.单词级的one-hot编码
推荐文章
- Pytorch Dataloader 模块源码分析(二):Sampler / Fetcher 组件及 Dataloader 核心代码-程序员宅基地
- Asp类型判断及数组打印-程序员宅基地
- Adroid Studio 2022.3.1 版本配置greendao提示无法找到_plugin with id 'org.greenrobot.greendao' not found-程序员宅基地
- esxi查看许可过期_解决Vsphere Client 60天过期问题-程序员宅基地
- CMake_cmake_module_path-程序员宅基地
- 生产者消费者模型-程序员宅基地
- Adaptive AUTOSAR 解决方案 INTEWORK-EAS-AP_autosar的eas-程序员宅基地
- 穿山甲SDK错误码40025_穿山甲sdk错误码4025-程序员宅基地
- css firefox下的兼容问题_css 只用于firefox-程序员宅基地
- 【Python】对大数质因数分解的算法问题_python分解多个质因数代码-程序员宅基地