
”爬虫程序实例“ 的搜索结果
如今代码圈很多做网络爬虫的例子,今天小编给大家分享的是如何用C#做网络爬虫。注意这次的分享只是分享思路,并不是一整个例子,因为如果要讲解一整个例子的话,牵扯的东西太多。 1、新建一个控制台程序,这个相信...
此程序是爬虫实例
创建套接字,向目标网站HTTP端口80或HTTPS端口443发送请求,获取指定网页的源代码,实现一个简单的网络爬虫程序。 参考代码: 运行结果: 温馨提示 关注本公众号“Python小屋”,通过菜单“最新资源”...
虽然python的多线程受GIL限制,并不是真正的多线程,但是对于I/O密集型计算还是能明显提高效率,比如说爬虫。分别用两种方式获取10个访问速度比较慢的网页,一般方式耗时50s,多线s。序:叮咚叮咚,...
python爬虫之下载文件的方式以及下载实例目录第一种方法:urlretrieve方法下载第二种方法:request download第三种方法:视频文件、大型文件下载实战演示第一种方法:urlretrieve方法下载程序示例:import osfrom ...
以上代码使用了colly库来创建一个爬虫实例,...使用colly库的爬虫程序,该程序将使用Go语言爬取内容。// 定义回调函数,用于处理抓取到的网页数据。// 创建一个Colly爬虫实例。// 打印网页URL。// 添加要爬取的URL。
本文从百度、360两种搜索引擎介绍关键字的提交爬取信息,在引用例的基础上做了优化,可以自主输入关键字,打印输出提交关键词后的查找内容的字符串长度以及相关的URL。

关于asyncio模块的介绍,笔者会在后续的文章中加以介绍,本文将会讲述一个基于asyncio实现的HTTP框架——aiohttp,它可以帮助我们异步地实现HTTP请求,从而使得我们的程序效率大大提高。 简介 asyncio可以实现单线程...

我们的爬虫程序在执行过程中,可能需要满足以下条件: 1、可以每天定时执行,爬取指定电商等网站内容。 2、可以对分布式爬虫进行监控,当爬虫程序挂掉之后,可以通知管理员。 下面我们来介绍如何实现...
打开cmd输入以下命令即可,如果python的环境在C盘的目录,会提示权限不够,只需以管理员方式运行cmd窗口。因为目录关系,在D盘建立了一个叫做爬虫的文件夹,然后保存信息,注意文件...python爬虫入门基础代码实例如下。
python实现网络爬虫
标签: python
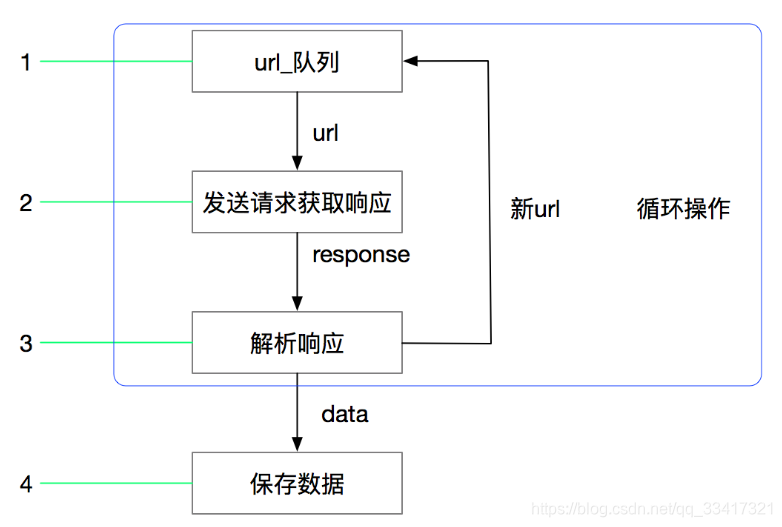
网络爬虫, 就是抓取网页数据的程序。 网络爬虫的实现流程包括三个部分: 获取网页、 解析网页、 存储数据。 首先通过 Requests 库向指定的 URL 地址发送 HTTP 请求, 从而把整个网页的 数据爬取下来, 接着通过 ...
通过学习这些内容,你将能够掌握Python爬虫的基本原理和技术,并能够编写自己的爬虫程序。在学习和使用爬虫的过程中,要遵守相关规则和道德标准,确保自己的行为合法合规。祝你在Python爬虫之旅中取得成功!
进程是计算机中正在运行的程序的实例。 它是计算机为了完成某个任务而创建的一个执行单元,包含程序代码、数据和执行状态等信息。 每个进程都有自己的内存地址空间、文件句柄、网络连接等资源。 进程可以与其他...



用到threading的Timer,也类似单片机那样子,在中断程序中再重置定时器,设置中断,python实例代码如下 import threading import time def change_user(): print('这是中断,切换账号') t = threading.Timer(3, ...


B站上刷视频的一些笔记.

给大家分享一波Python全套学习资料,免费!免费!免费!微信扫描下方CSDN官方认证二维码即可领取啦。

给大家安利一篇文章:小白进阶之Scrapy第一篇 这篇文章一步步讲如何使用Scrapy框架进行网页爬虫,简直是初学者的福音。 我接下来的内容也是按照他的思路写的,写这篇文章的目的是为了整理一下思路,把一些关键点列...
近期,有些朋友问我一些关于如何应对反爬虫的问题。由于好多朋友都在问,因此决定写一篇此类的博客。把我知道的一些方法,分享给大家。博主属于小菜级别,玩爬虫也完全是处于兴趣爱好,如有不足之处,还望指正。
推荐文章
- Java面向对象程序设计 第七章总结_方法的返回值被错误地处理为一个非空的对象-程序员宅基地
- RFX2401C skyworks射频2.4GHZ ZIGBEE/ISM发射/接收RFeIC_rfx2401c csdn-程序员宅基地
- Lambda简便方法引用、构造方法引用_lambdautils.getname-程序员宅基地
- sql表格模型获取记录内容_SQL Server和BI –如何使用Excel记录表格模型-程序员宅基地
- GateWay配置_grateway配置-程序员宅基地
- 云栖专辑| 阿里毕玄:程序员的成长路线-程序员宅基地
- Android 导出traces.txt 遇到的坑_biotraces无法导出-程序员宅基地
- 【ffmpeg 给视频添加背景音乐,去掉视频背景音乐原声】_ffmpeg.net 视频 加入 音频-程序员宅基地
- cocos2d-x3.2 lua 返回键监听_cocos2dx-lua cc.director:getinstance():endtolua()-程序员宅基地
- etcc oracle ebs,Oracle EBS12.2.6 克隆问题集合-程序员宅基地