今天写了一个 百度图片爬虫,代码如下 import requests import re import os import time headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/...
”爬虫百度图片“ 的搜索结果
Python爬虫批量下载百度图片
如何爬取图片、教你轻松爬取图片
XPath 是 Scrapy 中常用的一种解析器,可以帮助爬虫定位和提取 HTML 或 XML 文档中的数据。Scrapy 中使用 XPath 的方式和普通的 Python 程序基本一致。我们需要首先导入 scrapy 的 Selector 类和 scrapy 的 Request ...
浏览器会先下载图片的 url,再通过 url 下载图片。所以我们只要找到图片 url 的 http 请求即可。一般情况下,页面中的图片 url 就包含在页面的 HTML 文档中,使用谷歌浏览器开发者调试工具获取图片的 url
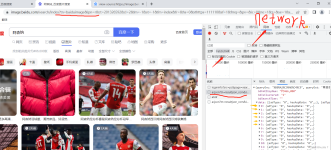
使用爬虫爬取百度图片
# 百度分页 page = 0 # 是否还有图片 end = True while end : page = page + 30 t = time.time() htime = int(round(t * 1000)) url = '...
文章目录前言爬虫百度图片时,总是有时好有时坏 解决方案更改headers:(2)我选择通过如下命令升级pip:(3)再下载cryptography(4)最后尝试最初的下载早中晚温差较大,注意保暖哦,sincerely,end. 前言 ...
输入关键字,批量下载百度图片的搜索结果。在别人的基础上进行了优化,支持汉字查询,可实现图片的批量下载。
基于python爬虫对百度贴吧进行爬取的课程设计
.Net爬虫Demo
百度图片爬虫(python)
标签: 爬虫 百度
刚学习爬虫,写了一个百度图片爬虫当作练习。 环境:python2.7(请下好第三方库requests) 实现的功能:输入关键字,下载270张关键字有关的百度图片到本地的()) 百度图片的加载是ajax异步形式的,除了前面的一部分...

百度图片爬虫
安装好go,配置好环境变量,下载后,直接执行run go pachong.go 即可下载。当然更改 关键则文件夹,爬虫你想要的图片也可以。请参考博客: https://blog.csdn.net/zhangpengzp/article/details/88565325

源码百度爬虫下载图片,简单输入你想要的图片文字内容,输入想要的页数,很快就下载好了

网页分析 1.搜索 搜索的关键词是拼接在url里的,这个好办! 2.分页 查看网页源代码,发现imgurl...鼠标滚轮下滚,图片会加载,触发某事件,也触发的网页请求。 F12调试网页,找到network,经过费力查找,我终于发现...
主要介绍了Python爬虫实现百度图片自动下载的方法以及相关代码分析,对此有兴趣的朋友参考下。

python爬虫爬取百度图片

python初学,不太懂哪里出了问题,运行之后显示搜到1020张图片,下载后前60张没有问题,后面就都是和前面一样,仔细一看,在第60张后面的程序又显示了找到关键词,正在下载。于是只能爬60张图片,求大佬们看一下什么...
百度图片爬虫python脚本,可以爬下关键字搜索下的所有图片。

第一步:登录百度图片官网,截图如下所示: 注意点一:开头必须是https(如上图所示,出现锁的标志),不能是http,否则后期下载图片文件会出错 第二步:输入关键字,页面加载出来之后,按F12进入开发者模式,由于百度图片ajax...
java爬虫爬取百度图片
标签: 爬虫百度图片
java爬虫爬取百度图片源码

推荐文章
- yolov3系列(四)-keras-yolo3-实时眼睛鼻子嘴巴监测系统_眼睛 嘴巴 yolo-程序员宅基地
- C++类型支持之std::decltype-程序员宅基地
- GB/T28181国标视频监控平台TINYGBS支持4G执法记录仪接入大型可视指挥调度平台-程序员宅基地
- 毕设项目 基于wifi的室内定位算法设计与实现-程序员宅基地
- 【.Net】C# 根据绝对路径获取 带后缀文件名、后缀名、文件名、不带文件名的文件路径...-程序员宅基地
- c语言比用delay更好的延时,PIC单片机C语言程序设计(15)-程序员宅基地
- 微型计算机的细思维特征,详细版2014计算机基础期末考试大纲-程序员宅基地
- org.eclipse.wst.common.component_org/eclipse/wst/common/componentcore/resources/ivi-程序员宅基地
- 数据结构乐智教学百度云_数据结构 百度网盘分享-程序员宅基地
- Arcade 绘制全屏-程序员宅基地