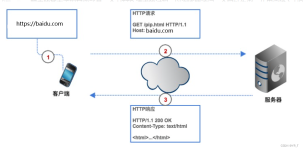
早在1989年,网络发明人蒂姆·伯纳斯 - 李(Tim Berners-Lee)就提出了网站的三大支柱:1)URL ,跟踪Web文档的地址系统2)HTTP,一个传输协议,以便在给定URL时查找文档3)HTML, 允许嵌入超链接的文档格式Web的最初...
”爬虫Python“ 的搜索结果
以下是爬虫Python基础知识的一些要点: 网络请求库:Python中常用的网络请求库有urllib和requests,它们可以发送HTTP请求并获取响应内容。 解析库:解析库用于解析HTML或XML等页面文档,提取出所需的数据。Python...
python爬虫python爬虫
1、python爬取企查查公司信息 2、添加应对反爬的设置 3、开箱即用,有示例数据文件 4、windows版本 5、需要登录或者人工验证 6、采用selenium模块+chromedriver驱动
利用Python来实现的爬虫,高效且可靠。
爬虫python入门
爬虫python入门
超级简单的Python爬虫入门教程(非常详细),通俗易懂,看一遍就会了
爬虫的全称为网络爬虫,简称爬虫,别名有网络机器人,网络蜘蛛等等。网络爬虫是一种自动获取网页内容的程序,为搜索引擎提供了重要的数据支撑。搜索引擎通过网络爬虫技术,将互联网中丰富的网页信息保存到本地,形成...
书籍资源
网络爬虫-Python和数据分析,非常好的python 学习书籍
爬虫python入门
爬虫python入门
Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架。Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。通常我们可以很简单的通过Scrapy 框架实现一个爬虫,...

Python爬虫利器二之Beautiful Soup的用法
爬虫python入门 爬虫python入门实战源码 爬虫python入门实战源码 爬虫python入门实战源码
爬虫python入门
爬虫python入门
爬虫的全称为网络爬虫,简称爬虫,别名有网络机器人,网络蜘蛛等等。网络爬虫是一种自动获取网页内容的程序,为搜索引擎提供了重要的数据支撑。搜索引擎通过网络爬虫技术,将互联网中丰富的网页信息保存到本地,形成...
如果你仔细观察,就不难发现,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工具,让爬虫变得简单、容易上手。爬取知乎优质答案,为...
爬虫python,巨细!Python爬虫详解

可从500px、Flickr、iStock、shutterstock等图片网站上批量爬取图片。input_filename为一个txt文件,txt文件中可有多行网址,每行是每页的网址。output_folder是爬取后的输出文件夹。
py爬虫Python爬虫Scrapy培训源码提取方式是百度网盘分享地址
讲诉python爬虫的20个案例 。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
Python爬虫相关软件是指方便Python爬虫编写、调试和执行的软件。以下将从编辑器、虚拟环境、爬虫框架、模块库、调试工具、反爬工具等多个方面进行阐述。以上就是Python爬虫开发中所需的软件工具。正确选择和使用这些...
爬虫python入门 网络爬虫(又被称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更经常的称为网页追逐 者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的 名字还有蚂蚁、自动索引、...
推荐文章
- Java面向对象程序设计 第七章总结_方法的返回值被错误地处理为一个非空的对象-程序员宅基地
- RFX2401C skyworks射频2.4GHZ ZIGBEE/ISM发射/接收RFeIC_rfx2401c csdn-程序员宅基地
- Lambda简便方法引用、构造方法引用_lambdautils.getname-程序员宅基地
- sql表格模型获取记录内容_SQL Server和BI –如何使用Excel记录表格模型-程序员宅基地
- GateWay配置_grateway配置-程序员宅基地
- 云栖专辑| 阿里毕玄:程序员的成长路线-程序员宅基地
- Android 导出traces.txt 遇到的坑_biotraces无法导出-程序员宅基地
- 【ffmpeg 给视频添加背景音乐,去掉视频背景音乐原声】_ffmpeg.net 视频 加入 音频-程序员宅基地
- cocos2d-x3.2 lua 返回键监听_cocos2dx-lua cc.director:getinstance():endtolua()-程序员宅基地
- etcc oracle ebs,Oracle EBS12.2.6 克隆问题集合-程序员宅基地