JAVA爬虫项目源代码
标签: 爬虫 JAVA
此资源为爬虫项目,使用JAVA,采用多线程编程和队列。基于HttpCliet、Jsoup、FastJsonjar包实现。
标签: 爬虫 JAVA
此资源为爬虫项目,使用JAVA,采用多线程编程和队列。基于HttpCliet、Jsoup、FastJsonjar包实现。

用法:运行脚本并传入URL参数,脚本会爬取视频分享网页上的所有视频链接,并打印。...在开发爬虫时,建议深入研究目标网站的结构和规则,使用合适的工具和库,并遵循最佳实践来确保爬虫的效率和合法性。
用法:运行脚本并传入微博用户的ID,脚本会爬取该用户的最新微博并打印。 爬虫需要遵守网站的...在开发爬虫时,建议深入研究目标网站的结构和规则,使用合适的工具和库,并遵循最佳实践来确保爬虫的效率和合法性。
爬虫简介安装及配置

注意:在实际应用中,爬取邮件地址可能涉及隐私问题,应遵守相关法律法规。 用法:运行脚本并传入...在开发爬虫时,建议深入研究目标网站的结构和规则,使用合适的工具和库,并遵循最佳实践来确保爬虫的效率和合法性。
抖音主页视频爬虫演示,程序运行长期稳定。

这里写自定义目录标题欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、...
用法:运行脚本并传入天气预报网站的URL,脚本会爬取天气信息,并打印出相关的数据。...在开发爬虫时,建议深入研究目标网站的结构和规则,使用合适的工具和库,并遵循最佳实践来确保爬虫的效率和合法性。
04网络爬虫共40页.pdf.zip

python爬虫常见异常共1页.pdf.zip
python爬虫常见异常共1页.pdf.zip
一、什么是爬虫 爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。 百度的网络爬虫就叫做BaiduSpider 二、什么是搜索引擎 搜索引擎:核心模块一般包括爬虫、索引、检索和排序等,同时...
学习Python数据爬虫的方法共1页.pdf.zip
Java爬虫信息抓取共14页.pdf.zip
爬虫
爬虫 001 robots.txt 协议 002 了解爬虫 003 常用的re模块的正则匹配的表达式 004 reuqests请求 005 请求和响应 006 Beautifulsoup 007 牛逼的requests-html 008 request-html-render 009 解析语法 010 xpath解析 ...
爬虫爬数据有几个雷区:一是只能爬取公开数据,二是不能对目标业务和网站造成影响,三是目标网站的全部或部分内容没有使用反爬措施。
导读:此文是一篇爬虫网络论文范文,为你的毕业论文提供有价值的参考。(1张家口学院网络信息中心,河北张家口075000;2张家口学院理学系,河北张家口075000)[摘 要]网络爬虫是搜索引擎和网站常用的搜索技术,它在为用户...
这篇文章主要与大家分享一下自己在python爬虫方面的收获与见解。 python爬虫是大家最为熟悉的一种python应用途径,由于python具有丰富的第三方开发库,所以它可以开展很多工作:比如 web开发(django)、应用程序...
PhantomJS是一个无头(headless)浏览器,它可以解析和执行JavaScript,非常适合用于爬取动态网页。"无头"意味着它可以在没有用户界面的情况下运行,这对于服务器环境和自动化任务非常有用。
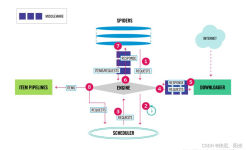
分布式爬虫则是将多台主机组合起来,共同完成一个爬取任务,这将大大提高爬取的效率。 一、分布式爬虫架构 在了解分布式爬虫架构之前,首先回顾一下Scrapy的架构,如下图所示。 Scrapy单机爬虫中有一个本地爬取...