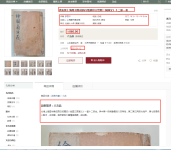
”爬虫“ 的搜索结果


Python爬虫学习心得小结
基于Python+MongoDB的可配置异步爬虫
利用Excel数据爬虫
标签: 爬虫

文章目录1、什么是爬虫?2、常见的的数据获取形式3、爬虫分类4、爬虫的流程5、url的详解6、 常见的请求头参数7、 常用的请求方法8、常见的响应状态码 1、什么是爬虫? 爬虫可以帮助我们在互联网上自动的获取数据和...

=========================== ...整理的原因是,爬虫入门简单快速,也非常适合新入门的小伙伴培养信心。所有链接指向GitHub,祝大家玩的愉快~O(∩_∩)O WechatSogou [1]- 微信公众号爬虫。基于搜狗微信搜索的微...


这几天在爬网站时发现有个别网站抓取时返回值为None、[ ]甚至是字段中返回“系统错误”等字眼),反复确认代码无误,怀疑是网站有反爬虫机制,尝试增加header后依然无法提取,考虑到只是提取本页面数据,并没有频繁...
最近在 GitHub 发现了一个爬虫库,这个库整理了**所有中国大陆爬虫开发者涉诉与违规相关的新闻、资料与法律法规。** 该项目库用来整理所有中国大陆爬虫开发者涉诉与违规相关的新闻、资料与法律法规。致力于帮助在...
例如,可能会在网站中放置“反爬虫”标记,告诉爬虫不要爬取这个网站。此外,网站还可能会在服务器上设置“黑名单”,如果爬虫的 IP 在黑名单中,就不允许访问网站。同时,Python 还有很多强大的功能,如多线程、...
自己笔记本电脑在公司跑爬虫,然后下班了,我把爬虫先暂停,然后把电脑带回家。回家后我再接着跑爬虫,它不香吗
特别申明:阅读本文之后,请勿滥用爬虫采集资源,攻击他人服务器。网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。...
爬虫需求的兴起源于网络发展,技术工具的发展与善恶无关。文章从历史视角解释了爬虫的起源和发展,强调了获取数据的重要性,以及搜索引擎和爬虫的关系。强调了爬虫需求的自然产生,技术只是工具,与善恶无关。同时...


cookie和session区别 cookie数据存放在客户浏览器上,session数据放在服务器上 cookie不是很安全,别人...爬虫处理cookie和session 带上cookie、session的优点: 能够请求到登录后页面 带上cookie、session的弊端:
Robots 协议(也称为爬虫协议等)的全称是「网络爬虫排除标准」(Robots Exclusion Protocol)。网站通过 Robots 协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。

1.爬虫通俗的概念:通过编写程序,去模拟我们的浏览器,去获取网络之上的相关的数据与信息。 2.爬虫的价值:爬虫的价值在于能够获取网上大量的有价值的信息,加以包装与利用去创造更大的价值。 3.爬虫的原则:不可以...
查看网站的爬虫协议,避免爬虫爬的好,牢饭吃得早(保姆级图文)

python爬虫基本概述 一、爬虫是什么 二、爬虫可以做什么 三、爬虫的分类 四、爬虫的基本流程 一、爬虫是什么 网络爬虫(Crawler)又称网络蜘蛛,或者网络机器人(Robots). 它是一种按照一定的规则, 自动...
在初步了解网络爬虫之后,我们接下来就要动手运用Python来爬取网页了。我们知道,网络爬虫应用一般分为两个步骤:1.通过网页链接获取内容;2.对获得的网页内容进行处理这两个步骤需要分别使用不同的函数库:requests...
在学习爬虫进阶路上少不了用到一些抓包工具,今天就给大家隆重推荐6款爬虫抓包神器。 聊一聊:爬虫抓包原理 爬虫的基本原理就是模拟客户端(可以是浏览器,也有可能是APP)向远程服务器发送 HTTP 请求,我们需要知道...
推荐文章
- NSFuzz:TowardsEfficient and State-Aware Network Service Fuzzing-程序员宅基地
- 刘睿民畅谈大数据:政府应紧急设立首席数据官-程序员宅基地
- nginx 编译安装依赖包_nginx编译怎么添加新的依赖库-程序员宅基地
- Python+OpenCV+Tesseract实现OCR字符识别_python + opencv + tesseract-程序员宅基地
- 微型计算机主板上的主要部件,微型计算机主板上安装的主要部件-程序员宅基地
- 推荐一款可匹敌国际大厂的国产企业级低无代码平台_国产私有化 无代码-程序员宅基地
- UE4 蓝图 实现 数组的边遍历边删除_ue4 数组删不掉-程序员宅基地
- python爬虫之bs4解析和xpath解析_from bs4 import beautifulsoup xpath-程序员宅基地
- MySQL配置环境变量-程序员宅基地
- VGG16进行微调,训练mnist数据集_vgg16 tensorflow 2 mnist-程序员宅基地