”流计算“ 的搜索结果
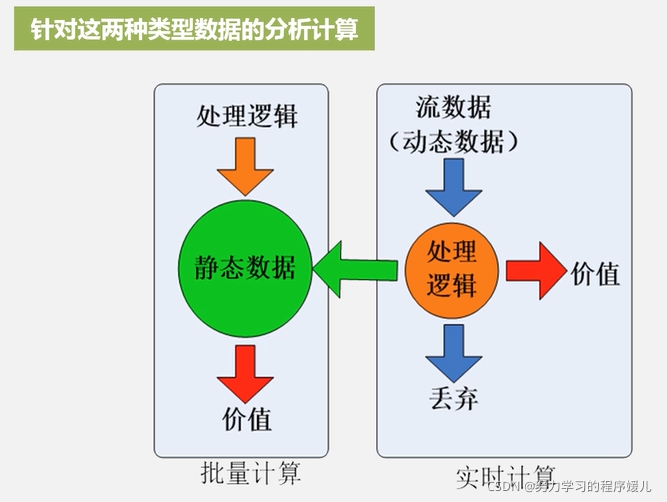
流计算通过将数据分成连续的、无限的数据流,并对每个数据进行逐个处理,从而实现实时的数据分析和处理。总之,流计算是一种实时处理数据的计算模型,它具有实时性、无限流、事件驱动、增量计算、状态管理和可伸缩性...
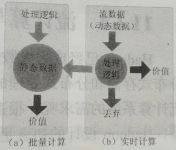
静态数据和流数据静态数据用一个非常形象的比喻,就是三峡水库里面蓄的水一样静止不动例如:数据仓库中的数据存入数仓后就维持不变,是典型的静态数据流数据:近年来,在Web应用、网络监控、传感检测等领域,兴起的...
导读:两千多年以前,孔老夫子站在大河边,望着奔流而去的河水,不禁感叹:“逝者如斯夫,不舍昼夜。”老夫子是在叹惜着韶华白首,时光易逝!两千多年以后的今天,当你我抱着手机读书、追剧、抢票、剁...
4_流计算和图计算.pptx
标签: 互联网
4_流计算和图计算.pptx
流数据:数据以大量,快速.时变的流形式持续到达. 2.流数据特征: 数据快速持续到达,潜在大小也许是无穷无尽的; 数据来源众多,格式复杂; 数据量大,但是不十分关注存储,一旦经过处理,要么被丢弃,要么被归档...
中国数据库技术大会实时计算与流计算专场PPT资料.rar,是学习实时计算与流计算最好的资料

低分分享-不仅仅是流计算-阿里美团头条-Flink实践完整版。
kafka连接flink流计算完整版,大数据项目实战时自己编写,kafka安装配置,flink安装配置,以及通过IDEA创建kafka-flink连接jar包等,实现kafka生产数据,flink消费,自我推荐,值得收藏
云环境下的实时流计算平台研究
标签: 实时流计算
云环境下的实时流计算平台研究 李钊
本文介绍了流计算框架Flink的原理和应用场景,以及通过代码示例演示了如何使用Flink实现实时统计任务。强调了流计算适用于实时产生数据的实时统计分析,以及Flink定义计算任务的简洁性和高效性。文章详细解释了Flink...
本文介绍了如何在流计算中使用Kafka连接计算任务,并重点讲解了Flink如何保证Exactly Once语义以及Kafka如何配合Flink实现端到端Exactly Once。文章深入解释了Flink的CheckPoint机制和Kafka的事务和生产幂等特性,...
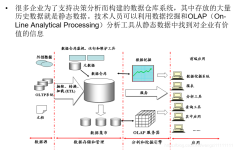
流计算概述 什么是流数据: 数据有静态数据和流数据。 静态数据: 很多企业为了支持决策分析而构建的数据仓库系统,其中存放的大量历史数据就是静态数据。技术人员可以利用数据挖掘和OLAP(On-Line Analytical...
Apache软件基金会下的顶级开源项目之一,Apache软件基金会最重要的三大分布式计算系统开源项目之一(Hadoop、Spark、Storm) Flink Apache 软件基金会顶级项目,是Apache软件基金会的5个最大的大数据项目之一 Storm ...
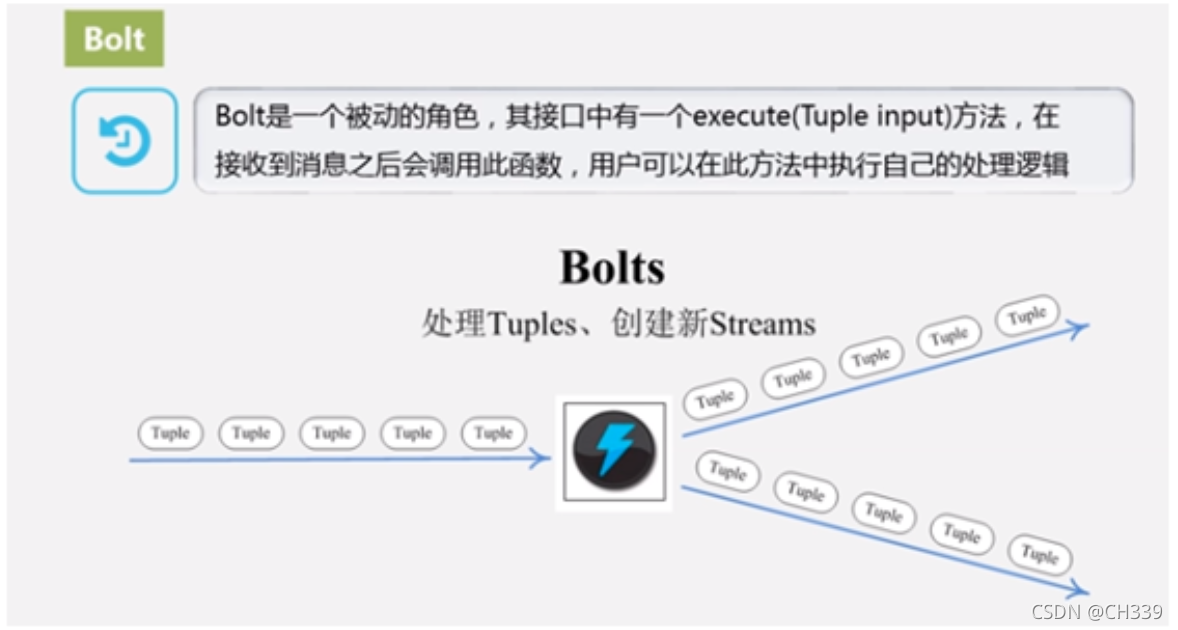
JAVA流式计算流的简单介绍Java 8 中,引入了流(Stream)的概念,利用提供的Stream API,我们可以方便的操作集合数据,这种方式很类似于使用SQL对数据库的操作。如何生成流利用Stream API,首先我们需要生成流,以下是...

文章目录什么是流式计算数据流数据时序数据集有界数据集无界数据集主要应用场景批、流计算相结合Q&A附录 什么是流式计算 当你谈起流式计算的时候,说明你当前的处境已经涉及到了大数据范畴。 流式计算是大数据...
本文深入探讨了流计算中的数据关联,包括流批关联和双流关联的功能、特性和限制。以短视频推荐引擎为例,详细介绍了流批关联的实际应用场景和代码实现过程。同时提及了优化方法和结果验证,为读者提供了全面的...
近年来,在Web应用、网络监控、传感监测等领域,兴起了一种新的数据密集型应用——流数据,即数据以大量、快速、时变的流形式持续到达。数据快速持续到达,潜在大小也许是无穷无尽的数据来源众多格式复杂数据量大,...
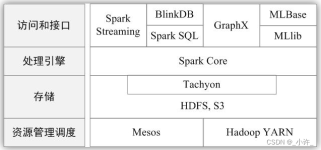
•Spark最初由美国加州伯克利大学(UCBerkeley)的AMP实验室于 2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大 型的、低延迟的数据分析应用程序 •2013年Spark加入Apache孵化器项目后发展迅猛,如今...

阐述了阿里巴巴内部流数据处理平台的发展历程,重点分析了JStorm和Blink两个流计算引擎的发展。JStorm由Storm重写而来,解决了Storm存在的问题,但在Apache孵化器中未能成为顶级项目。Blink是阿里巴巴内部流处理引擎...
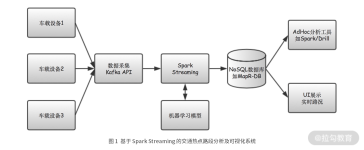
文章总结:Spark Streaming是Spark的实时流计算API,将连续的流数据按时间间隔划分为数据块,每个块是一个RDD,具备RDD的优点,如快速处理和数据容错性。然而,实时延迟较高,不支持小批处理时间间隔。Spark ...
推荐文章
- 分享66个焦点幻灯JS特效,总有一款适合您_js 幻灯片-程序员宅基地
- Qt: 窗口的显示和隐藏_qt释放还是隐藏对话框dialog.accept()-程序员宅基地
- 【风电功率预测】海洋捕食算法MPA优化BP神经网络风电功率预测【含Matlab源码 3770期】-程序员宅基地
- 2023研究生英语二真题笔记_2023年研英语二-程序员宅基地
- SpringBoot_第二章(案例入门)_第二章快速入门案例-程序员宅基地
- WebMvcConfigurer 详解_webmvcconfigurer extendmessageconverters-程序员宅基地
- sqlserver修改实例名_sqlserver修改实例名称-程序员宅基地
- Mac adb devices时,一直显示emulator-5554 offline如何解决_mac emulator-5554 offline-程序员宅基地
- Delphi XE10,Json 生成和解析,再利用indyhttp控件Post_delphixe json post-程序员宅基地
- 一个简单的基于MVC模式的登录验证过程_mvc的网站登录验证应用: 建立几个jsp页面,在这里我们主要做登录,所以我们要建logi-程序员宅基地