
”机器学习分类“ 的搜索结果

整理自coursera华盛顿大学机器学习课程

四、二分类到多分类 五、类别不平衡问题 一、常见方法与其核心 1、线性判别分析 以一种基于降维的方式将所有的样本映射到一维坐标轴上,然后设定一个阈值,将样本进行区分,映射依据为:类间间距大,类内间距小。 ...
机器学习的一般分类为:监督学习、无监督学习、强化学习、半监督学习、主动学习。 1.监督学习 监督学习是从<x, y>这样的示例对中学习统计规律,然后对于新的X,给出对应的y。 输入空间、特征空间、输出空间...
对于KNN,SVM,adaboost以及决策树等分类算法对数据集运行结果进行总结,代码点我博文
Extended-wavelength diffuse reflectance spectroscopy with a machine-learning method for in vivo tissue classification 在活体组织上使用机器学习方法对扩展波长的漫反射光谱分类 ** 研究对象:猪的不同组织和...
机器学习分类和预测任务
目录 1. 准确率,召回率,精确率,F1-...3. Python3 sklearn实现分类评价指标 1. 准确率,召回率,精确率,F1-score,Fβ,ROC曲线,AUC值 为了评价模型以及在不同研究者之间进行性能比较,需要统一的评价标准。...


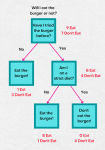
分类。 na_values["?"]—空 数据特别大,不适合放在内存里面处理,不适合用pandas处理 pandas中的describe()可以将数据所有特征显示出来,describe()显示的是数字特征,非数字特征加上include=[‘0’] 默认前5行。...
说起分类算法,相信学过机器学习的同学...一起来通过这篇文章回顾一下机器学习分类算法吧(本文适合已有机器学习分类算法基础的同学)。 机器学习是一种能从数据中学习的计算机编程科学以及艺术,就像下面这句话说得
Spark mllib包含的分类模型有:逻辑回归,决策树,随机森林,梯度提升树,多层感知机,线性SVM,朴素贝叶斯。 回归模型有:线性回归,决策树回归,随机森林回归,梯度提升树回归,生存回归,保序回归。 在spark ...
机器学习及其分类
KNN: 依赖数据,无数学模型可言。适用于可容易解释的模型。 对异常值敏感,容易受到数据不平衡的影响。 Bayesian: 基于条件概率, 适用于不同维度之间相关性较小的时候,比较容易解释。也适合增量训练,不必要再重...

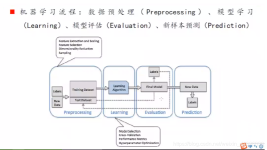
机器学习经典算法的C语言代码,比如:ID3算法 人脸识别源代码 K紧邻算法、人工神经网络

本篇文章详解机器学习应用流程,应用在结构化数据和非结构化数据(图像)上,借助案例重温机器学习基础知识,并学习应用机器学习解决问题的基本流程。
本文通过对不同机器学习分类算法的实验比较,探讨它们在数据集上的性能差异。实验涵盖了常见的分类算法如决策树、支持向量机、逻辑回归等,并通过准确率、召回率等指标进行评估。读者将了解各算法在不同数据集上的...
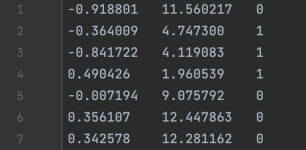
介绍机器学习相关,大致了解什么是机器学习,以及机器学习分类、基本用途。完整版请下载PDFhttp://download.csdn.net/download/u011626960/10255071
在一个机器学习任务中,如果每一条数据的目标值是离散的,则该任务是一个分类任务。 解决分类问题基本的方法有:线性分类器、决策树、朴素贝叶斯、人工神经网络、K近邻(KNN)、支持向量机(SVM); 组合基本分类...


推荐文章
- java学生成绩管理系统(GUI+javaSwing+Excel)-程序员宅基地
- 山东大学软件学院2020级人工智能导论期末试题_山东大学人工智能导论期末考试-程序员宅基地
- MyBatis配置项--配置环境(environments)--事务管理器(transactionManager)-程序员宅基地
- 三菱PLC(FX5U)与C#通信说明_三菱plc安装序列号-程序员宅基地
- Oracle DBA数据库日常维护完全手册_oracle dba日常-程序员宅基地
- vim中的airline插件不显示箭头(解决)-程序员宅基地
- MATLAB与Hspice联合仿真_hspice 编译loadsig-程序员宅基地
- 牛顿迭代法(Newton’s Method)迭代求根的Python程序_newton迭代 python-程序员宅基地
- python中的字符串以及内置方法_程序功能为使用内置函数计算字符串a='aegweg'长度,并将计算的长度输出在屏幕上。-程序员宅基地
- [技术讨论]代码编写能力与管理手段的配合_代码管理手段-程序员宅基地