
”最近邻“ 的搜索结果

K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。
用C++实现最近邻近点对,利用算法导论的知识实现最近邻近点对问题
利用K-最近邻算法进行高识别率的信号特征五分类

最近邻插值法放大图像:最近邻插值法在放大图像时补充的像素是最近邻的像素的值。由于方法简单,所以处理速度很快,但是放大图像画质劣化明显,常常含有锯齿边缘。最近邻插值法算法原理 ↑二. 最近邻插值法算法流程...
转自https://www.cnblogs.com/futurehau/p/6524396.htmlAnnoy是高维空间求近似最近邻的一个开源库。Annoy构建一棵二叉树,查询时间为O(logn)。Annoy通过随机挑选两个点,并使用垂直于这个点的等距离超平面将集合划分...
一段时间后,我在MATLAB Image Processing Toolbox中通过了imresize功能的代码,为图像的最近邻插值创建了一个简化版本。以下是如何应用于您的问题:%# Initializations:scale = [2 2]; %# The resolution scale ...
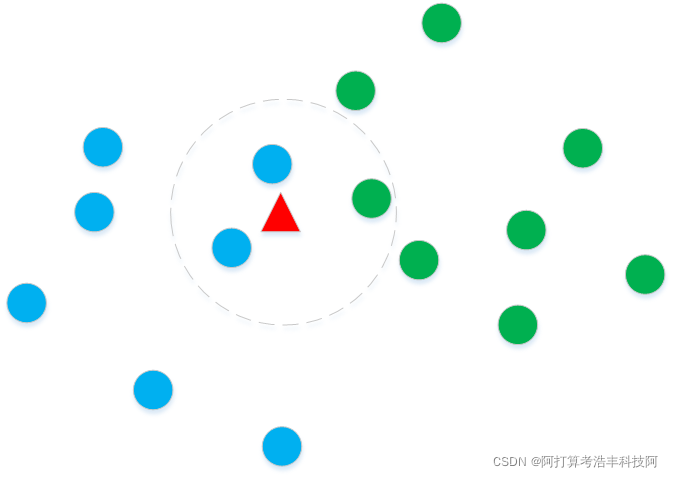



在一组点中查找 k - 最近邻 (kNN) 的程序。 使用的距离度量:欧氏距离 用法: [邻居距离] = kNearestNeighbors(dataMatrix, queryMatrix, k); dataMatrix (N x D) - 维数为 D 的 N 个向量(我们在其中搜索最近的邻居...
基于SVD分解和最近邻算法的高维人脸识别代码,是MATLAB系统上实现的代码,可直接运行,包含人脸数据库
最近邻数据关联算法(NNDA)
标签: 算法
其中,这个最近邻一般指观测点迹在统计意义下上距离被跟踪目标的预测位置最近。(主观上看,比如欧式距离最近)。但是问题来了,为什么要作用这个为统计距离。是因为这种方法是在最大似然意义下最佳。最近邻算法...

本文提出了一种基于K最近邻(k-Nearest Neighbor,KNN)文本分类的伪装入侵检测方法,减少了TFIDF权重表示中高频命令的权重,提出新的权重表示方法 STFIDF,使得有区分性的命令权重增大,有利于更准确地表示用户的行为特征,...
【代码】数据预处理-最近邻插值算法。

针对频谱的可预测性问题,通过对数据集的分析,使用k最近邻(k NN)回归模型预测频谱的信道-场强值。基于观测数据呈现出的周期性,提出了一种针对周期性数据进行优化的k NN模型,并用其进行预测。比较了原始k NN回归模型和...
提出了基于遗传进化的最近邻聚类算法, 该算法结合了遗传算法(GA )与最近邻聚类算法 (NN )。 对要进行分类的样本和特征量进行优化选取, 去除位于类交界的模糊样本, 并对样本分类有效的 特征量进行放大, 对...
最近邻搜索是k近邻的特例,也就是1近邻。将1近邻改扩展到k近邻非常容易。下面介绍最简单的k-d tree最近邻搜索算法。基本的思路很简单:首先通过二叉树搜索(比较待查询节点和分裂节点的分裂维的值,小于等于就进入左...
https://blog.csdn.net/weixin_44049128/article/details/86502423此篇博文代码。
一、实验目的 1、熟悉并掌握MATLAB工具的使用...2、对图像执行放大、缩小及旋转操作,分别采用最近邻插值、双线性插值及双三次插值方法实现,要求根据算法自己编写代码实现,并分析三种方法的优缺点。 (二)、相关知
LBSs 中查询类型可 分为单个用户最近邻查询和群组最近邻查询。在深度分析现有群组最近邻查询中位置隐私保护的基础上,提出LBSs 中一种 面向位置隐私保护的群组最近邻查询方法。该方法采用分布式系统结构,...
研究关联限制在最近邻分类中的应用,提出结合关联限制的最近邻分类算法PCNN.算法分成两个阶段:首先通过自学习过程,成对地添加施加关联限制的样本对;然后再进行一般的最近邻分类.引入最大半径和有效距离,并进一步给...


最近邻插值、双线性插值
标签: python

推荐文章
- 记录nvm use node.js版本失败,出现报错: exit status 1: ��û���㹻��Ȩ��ִ�д˲�����_nvm use失败-程序员宅基地
- lua面向对象编程之点号与冒号的差异详细比较-程序员宅基地
- 百度云虚假下载_虚假新闻:关于公共云的5种常见误解-程序员宅基地
- Tesseract图像识别OCR的学习1_tesseract doocr-程序员宅基地
- 不同层级的Android开发者的不同行为,我们该如何进阶和规划?-程序员宅基地
- Pelee: A real-time object detection system on mobile devices-程序员宅基地
- Hadoop环境搭建(保姆级教学)_hadoop平台搭建步骤-程序员宅基地
- ZooKeeper实战之ZkClient客户端实现负载均衡_zookeeper实现负载均衡案例-程序员宅基地
- Android 枚举 VS 枚举注解_android 枚举注解-程序员宅基地
- HDU1715--第i个斐波那契数 大菲波数_返回第i个斐波那契数-程序员宅基地