时序差分方法 时序差分方法是强化学习理论中最核心的内容,是强化学习领域最重要的成果,没有之一。与动态规划的方法和蒙特卡罗的方法比,时序差分的方法主要的不同点在值函数估计上面。 动态规划方法计算值函数是...
”时序差分“ 的搜索结果

1、n步时序差分方法 2、n步回报 3、n步时序差分方法在随机游走上的应用
时序差分学习(Temporal Difference Learning)和SARSA算法都是强化学习领域中的重要概念和算法,用于训练智能体(Agent)在环境中学习并优化其行为。其中时序差分学习是一种通用的强化学习方法,而SARSA是一种特定...
时序差分算法对此进行了改进蒙特卡洛控制和时序差分学习有什么区别?四、时序差分算法(Temporal Difference Learning, TD 学习)4.1 时序差分(0)4.2 Sarsa算法4.3 Q学习(Q-learning)4.4 Sarsa和Q-learning有...
目录时序差分概述 时序差分概述 前面我们讲了基于模型的动态规划和不基于模型的蒙特卡罗算法,他们都有各自的优点和缺点。动态规划能够很好的基于模型来求解强化学习,但是现实问题中很少能提前知道这个模型;蒙特...
时序差分学习算法介绍.ppt

Temporal-difference (TD) learning可以说是增强学习的中心,它集成了蒙特卡洛思想和动态编程(dynamic programming, DP)思想,像蒙特卡洛方法一样,TD 方法不需要环境的动态模型,直接从经验经历中学习。
时序差分学习(TD)
标签: 学习

蒙特卡洛算法和时序差分算法,SARSA和Q-learning
强化学习——时序差分
由于目前分数阶混沌的理论分析和硬件设计都比较烦琐,提出了分数阶混沌系统的Simulink动态仿真方法。以分数阶Jerk系统为例,根据分数阶系统方程搭建分数阶混沌系统仿真模型,可动态地观察系统变量的变化规律。...
本文主要为学习sutton书中《时序差分学习》章节整理而来。 一、引言 1、蒙特卡洛方法回顾 (1)预测问题 蒙特卡洛的目标是根据策略π\piπ采样轨迹序列vπ(s)v_\pi(s)vπ(s):S1,A1,R2,...,Sk∼πS_1,A_1,R_2,...,...
强化学习(六):时序差分方法 时序差分(TD)方法结合了动态规划与蒙特卡洛的思想,其可以像蒙特卡洛方法一样直接从智能体与环境互动的经验中学习,而不需要知道环境的模型,其又可以像动态规划一样无须等待...
时序差分更新算法和回合更新算法一样都是利用经验数据进行学习,其区别在于时序差分更新不必等到回合结束,可以用现有的价值估计值来更新。因此时序差分更新既可用于回合制任务,也可用于连续性任务。 同策时序差分...



本文我们就来讨论可以不使用完整状态序列求解强化学习问题的方法:时序差分(Temporal-Difference, TD)。 时序差分这一篇对应Sutton书的第六章部分和UCL强化学习课程的第四讲部分,第五讲部分。 章节目录 时序差分...
目录1、时序差分预测1)与动态规划方法的比较2)与蒙特卡罗方法的比较3)时序差分预测伪代码2、Sarsa算法:在线策略的时序差分方法3、Q-learning算法:离线策略的时序差分方法4、Q-learning解决寻宝问题 蒙特卡罗...

前面讲到了MC(蒙特卡洛方法)和TD(0)算法。MC方式是根据采样到的经验轨迹实际得到的奖励来更新轨迹中出现的状态的价值,...基于这个想法,就产生了n步时序差分算法。即在某个状态的价值等于在当前状态下走n步得到的奖...
目录1. TD预测1.1. TD(0)算法三级目录 1. TD预测 TD是另一种对最优策略的学习方法,本节讲述TD预测,即使用TD求解策略π\piπ的值函数vπ(s)v_{\pi}(s)vπ(s)。 TD预测被称为 DP 和 MC 的结合体,DP是 期望更新+自...

上一节讲的是在已知模型的情况下,如何去解决一个马尔科夫决策过程(MDP)问题。方法就是通过动态规划来评估一个给定的策略,通过不断迭代最终得到最优价值函数。具体的做法有两个:一个是策略迭代,一个是值迭代。...
点击下方卡片,关注“CVer”公众号AI/CV重磅干货,第一时间送达本文作者:不起眼的木头君|来源:知乎(已获作者授权)https://zhuanlan.zhihu.com/p/34...
文章目录时序差分价值迭代 TD(nstep)TD(n_{step})TD(nstep)同策时序差分策略评估SARSA / SARSA(n)异策时序差分重要性采样Q学习(Q-Learning)双重Q学习(Double Q-Learning)资格迹算法 TD(λ)TD(\lambda)TD(λ)...
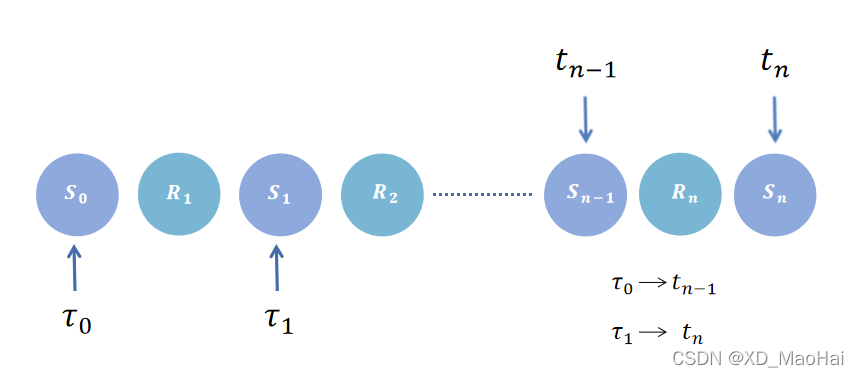
所有的方法都遵循广义策略迭代(即,广义上的策略评估和策略提升...时序差分 是 否 1.on-policy实现(sarsa) 2.off-policy实现(q-learning) n步bootstrap 是 否 1.on-policy实现(n步sarsa) 2.off-policy实现
推荐文章
- 树和二叉树5——先序遍历输出叶子到根的逆路径_编写一个程序,采用先序遍历方法输出所有从叶子结点到根节点的逆路径,并对图a-程序员宅基地
- 网站快速成型工具-Element UI_基于element 的网页ui-程序员宅基地
- 巨页的配置和修改_hugepages_total-程序员宅基地
- 【python】Python报错:RecursionError: maximum recursion depth exceeded in comparison-程序员宅基地
- 完成SSH项目 -- 实现dao层_ssh框架service层调用dao有的能创建成功-程序员宅基地
- 在.net下将word文档转换为加有水印pdf文档_.net webapi word pdf添加水印 开源-程序员宅基地
- 解决openweather无法注册的问题_openweather api 创建账户被禁止了-程序员宅基地
- winscp通过跳板机访问远程服务器(使用秘钥的方式传输文件)_winscp 隧道 跳板机上的密码-程序员宅基地
- 从C++到Java(一)_enum c++ java-程序员宅基地
- 网络学习第六天(路由器、VLAN)_路由和vlan-程序员宅基地