带有PySpark的Spark和Python用于大数据:Spark机器学习项目
”大数据/Spark“ 的搜索结果
大数据Spark企业级实战,PDF电子版,带书签,非常清晰喔~
尚硅谷大数据技术Spark教程-笔记01【Spark(概述、快速上手、运行环境、运行架构)】
通过理论和实际的紧密结合,可以使学员对大数据Spark技术栈有充分的认识和理解,在项目实战中对Spark和流式处理应用的场景、以及大数据开发有更深刻的认识;并且通过对流处理原理的学习和与批处理架构的对比,可以对...
spark编程基础课件 适合初学者 有需要的可以下载看看 巴拉巴拉巴巴
大数据spark搭建,spark安装包
大数据Spark学习资料


在整个毕业论文设计的过程中我学到了做任何事情所要有的态度和心态, 首先我明白了做学问要一丝不苟, 对于出现的任何问题和偏差都不要轻视, 要通过正确的途径去解决, 在做事情的过程中要有耐心和毅力, 不要一...
大数据Spark实战视频培训教程:本课程内容涉及,Spark虚拟机安装、Spark表配置、平台搭建、快学Scala入门、Spark集群通信、任务调度、持久化等实战内容。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室...


大数据分为离线和实时数据 Hive仅是离线数据 sparkStreaming 和 Flink 是实时数据工具 spark衍生出各种工具,其核心是mr的优化 Hive(核心功能:SQL=>Spark、对象(databases,table,column/type)) SQL => ...
大数据技术课程的Spark大作业以及Spark实验.zip大数据技术课程的Spark大作业以及Spark实验.zip大数据技术课程的Spark大作业以及Spark实验.zip大数据技术课程的Spark大作业以及Spark实验.zip大数据技术课程的Spark大...

spark学习课件,让你深入浅出学习spark。Spark是Hadoop MapReduce的替代方案。MapReudce不适合迭代和交互式任务,Spark主要为交互式查询和迭代算法设计,支持内存存储和高效的容错恢复。Spark拥有MapReduce具有的...
大数据技术之Spark源码
《大数据Spark企业级实战》详细解析了企业级Spark开发所需的几乎所有技术内容,涵盖Spark的架构设计、Spark的集群搭建、Spark内核的解析、Spark SQL、MLLib、GraphX、Spark Streaming、Tachyon、SparkR、Spark多语言...
spark作为一种新型的数据库形式,综合了以前各个数据库的优点研制的
大数据开发的准备步骤,各个大数据安装的说明书,hadoop,saprk等

大数据测试数据spark
标签: spark
大数据测试数据spark
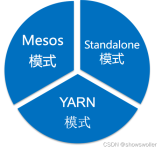
本文详细讲解了spark集群的三种部署模式

这是一位大数据分析开发者的一本Spark入门学习用的总结
本资料是集合20篇知网被引最高的基于spark的大数据论文,包括大数据Spark技术研究_刘峰波、大数据下基于Spark的电商实时推荐系统的设计与实现_岑凯伦、基于Spark的Apriori算法的改进_牛海玲、基于Spark的大数据混合...
Hadoop的Yarn框架比Spark框架诞生的晚,所以Spark自己也设计了一套资源调度框架。区别1、MR是基于磁盘,spark是基于内存2、MR的task是进程3、spark的task是线程,在executor进程里执行的线程。4、MR在Container里...
大数据技术之spark.docx
推荐文章
- 联邦学习综述-程序员宅基地
- virtuoso--工艺库答疑_tsmc mac-程序员宅基地
- C++中的exit函数_c++ exit-程序员宅基地
- Java入门基础知识点总结(详细篇)_java基础知识重点总结-程序员宅基地
- 【SpringBoot】82、SpringBoot集成Quartz实现动态管理定时任务_springboot集成quratz 实现动态任务调度-程序员宅基地
- testNG常见测试方法_idea_java_testng 测试-程序员宅基地
- Debian11系统安装-程序员宅基地
- Centos7重置root用户密码_centos7更改root密码-程序员宅基地
- STM32常用协议之IIC协议详解_正点原子stm32 iic-程序员宅基地
- 【视频播放】Jplayer视频播放器的使用_jplayer 播放amr-程序员宅基地