与大数据生态系统中的许多流行技术(Kafka、HDFS、Spark 等)集成 - 分布式处理框架。 集成 MapReduce(并行处理)、YARN(作业调度)和 HDFS(分布式文件系统)。 - 高吞吐量实时流处理框架。 - Pachyderm 是一个...
”大数据/Spark“ 的搜索结果
spark知识点的链接地址: http://blog.csdn.net/joker992/article/details/50043349
park为了解决以往分布式计算框架存在的一些问题(重复计算、资源共享、系统组合),提出了一个分布式数据集的抽象数据模型:RDD(Resilient Distributed Datasets)弹性分布式数据集。
2021贺岁大数据入门spark3.0入门到精通资源简介: 本课程中使用官方在2020年9月8日发布的Spark3.0系列最新稳定版:Spark3.0.1。共课程包含9个章节:Spark环境搭建,SparkCore,SparkStreaming,SparkSQL,...
2021贺岁大数据入门spark3.0入门到精通资源简介: 本课程中使用官方在2020年9月8日发布的Spark3.0系列最新稳定版:Spark3.0.1。共课程包含9个章节:Spark环境搭建,SparkCore,SparkStreaming,SparkSQL,...
python大数据之spark编程基础与提升视频课程 演讲人 202x-11-11 Python大数据之Spark编程基础与提升视频课程课件PPT模板全文共15页,当前为第1页。 04/ 第4章spark机器学习之核心应用 03/ 第3章spark机器学习之特征...
1、请问什么情况数据是确定放在内存的呢,我做loadufs操作从hdfs加载到tachyon的都是看到 not in memory 的,但是用spark textFile(tachyon://hostname:19998/test.txt)调用文件后,后来在web UI上又能看到有部分...
2021贺岁大数据入门spark3.0入门到精通资源简介: 本课程中使用官方在2020年9月8日发布的Spark3.0系列最新稳定版:Spark3.0.1。共课程包含9个章节:Spark环境搭建,SparkCore,SparkStreaming,SparkSQL,...
大数据spark实验报告包含实验过程

近几年在大数据领域 Spark 还是比较火的,它可以快速计算大量数据,TB 甚至 PB 级别,因为它是基于内存的计算,比 MapReduce 更快,更灵活。 不过 Spark 使用的不好,也会很慢,平时在使用的时候需要特别了解 Spark ...
针对大数据的离线分析,提高对数据的处理能力,一般应用于分析报表以及针对商户大量交易数据处理。
面试大数据岗位 spark相关问题汇总
spark sql, 通过spark处理公交大数据。

1、该资源内项目代码经过严格调试,下载即用确保可以运行! 2、该资源适合计算机相关专业(如计科、人工智能、大数据、数学、电子信息等)正在做课程设计、期末大...电商+大数据+spark机器学习(开发源码+项目说明).zip
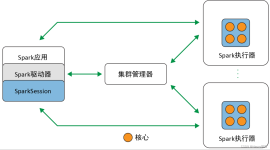
大数据-spark-分析可视化自动推荐系统,用于学习大数据,有一系列的流程分析以及实现代码,最新的jar版本
2021贺岁大数据入门spark3.0入门到精通资源简介: 本课程中使用官方在2020年9月8日发布的Spark3.0系列最新稳定版:Spark3.0.1。共课程包含9个章节:Spark环境搭建,SparkCore,SparkStreaming,SparkSQL,...
大数据Spark面试题汇总,共有79道面试题以及题目的解答 部分题目如下: 1. spark 的有几种部署模式,每种模式特点? 2. Spark 为什么比 mapreduce 快? 3. 简单说一下 hadoop 和 spark 的 shuffle 相同和差异? 5. ...
什么是Spark Spark是一种快速、通用、可扩展的大数据分析引擎,2009年诞生于加州大学伯克利...Hadoop的MapReduce作为第一代分布式大数据计算引擎,在设计之初,受当时计算机硬件条件所限(内存、磁盘、cpu等),为了能
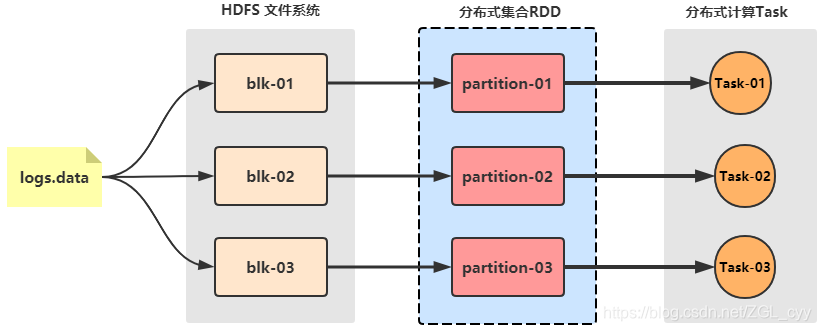
2021贺岁大数据入门spark3.0入门到精通资源简介: 本课程中使用官方在2020年9月8日发布的Spark3.0系列最新稳定版:Spark3.0.1。共课程包含9个章节:Spark环境搭建,SparkCore,SparkStreaming,SparkSQL,...
光环大数据培训spark体系课程文档,花钱上课的课件文档!
2021贺岁大数据入门spark3.0入门到精通资源简介: 本课程中使用官方在2020年9月8日发布的Spark3.0系列最新稳定版:Spark3.0.1。共课程包含9个章节:Spark环境搭建,SparkCore,SparkStreaming,SparkSQL,...
2021贺岁大数据入门spark3.0入门到精通资源简介: 本课程中使用官方在2020年9月8日发布的Spark3.0系列最新稳定版:Spark3.0.1。共课程包含9个章节:Spark环境搭建,SparkCore,SparkStreaming,SparkSQL,...
利用Python和Spark进行海量数据的实时分析,解决商业方案
大数据面试题,大数据成神之路开启...Flink/Spark/Hadoop/Hbase/Hive... 已经更新100+篇~ 关注公众号~ 大数据成神之路目录 大数据开发基础篇 :skis: Java基础 :memo: NIO :open_book: 并发 :...
2021贺岁大数据入门spark3.0入门到精通资源简介: 本课程中使用官方在2020年9月8日发布的Spark3.0系列最新稳定版:Spark3.0.1。共课程包含9个章节:Spark环境搭建,SparkCore,SparkStreaming,SparkSQL,...
过往记忆的链接地址请点击此处
推荐文章
- golang zk大量disconnected event_golang zk watch-程序员宅基地
- python产生fir滤波器_Python 基于FIR实现Hilbert滤波器求信号包络详解-程序员宅基地
- Linux进程概念-程序员宅基地
- 如何用 CSS 将超出显示宽度的内容隐藏起来[转]_css标签根据外层标签宽度显示或隐藏-程序员宅基地
- Elasticsearch介绍及如何使用_elasticsearch match_phrase_prefix-程序员宅基地
- 《算法笔记》 第五章 入门篇(3)--数学问题_算法第五章组合数学基础内容-程序员宅基地
- SONiC(1):运行SWSS测试用例_sonic platform common-程序员宅基地
- 《软件测试》读书笔记(持续更新)_软件测试读书笔记csdn-程序员宅基地
- es安装IK分词器_ik github-程序员宅基地
- C++Primer第五版中文版 第11章 练习题答案-程序员宅基地