利用python爬取在前程无忧网搜索python关键字出现的最新的招聘数据,保存到本地Excel,进行数据查看和预处理,然后利用matplotlib进行数据分析和可视化。 1. 爬取数据 目标url:https://www.51job.com/ 在前程无忧...
”前程无忧数据分析“ 的搜索结果
毕业设计:基于python前程无忧数据采集分析可视化系统+Flask框架(源码+文档)

(2) 涉及知识点:分布式爬虫、Hadoop,Spark,大数据分析,数据可视化 (3) 分析路径:首先部署Hadoop+Spark大数据处理平台 (2) 本案
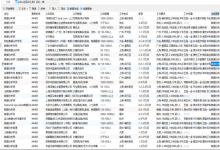
基于Python的前程无忧职位数据分析与可视化项目源代码+数据+爬虫,采集某职位信息,保存在本地csv文件中 采集某职位信息,保存在本地csv文件中,并使用采集到的信息进行数据分析,包括职位薪资分析,分析职位学历、...
基于spark+echarts实现的前程无忧招聘网站数据大屏分析源码+项目说明.zip本资源中的源码都是经过本地编译过可运行的,评审分达到95分以上。资源项目的难度比较适中,内容都是经过助教老师审定过的能够满足学习、使用...
总的来说,这些分析揭示了网页等级排名和职位等级排名与职位的具体特征之间的关联。特定类型的职位、公司类型、规模和行业可能会影响它们在搜索结果中的可见度和优先级。综合来看,这些分析结果表明,不同搜索关键词...
近期想找数据分析方面的工作,又苦于没有工作经验,在老司机的指导下,我尝试将招聘网站前程无忧上广州数据分析岗位的部分数据用爬虫获取并进行了简单的数据分析。一、数据获取不得不说,前程无忧几乎没有反爬虫机制...

前程无忧爬虫 【程序运行前确保项目需要的库都已下载】 # 数据爬取: ``` 1、修改51job_info.py代码66行,根据需要修改页数,默认2页,数据分析需要海量数据时可修改成1000页 2、运行51job_info.py 3、输入职位...
根据前程无忧不完全样本统计,北上广深成都重庆平均月工资从高到低依次为 北京14994元、上海14286元、深圳13404元、广州10946元、成都10511元、重庆10342元。综合北上广深成都重庆六大来看,行业平均月工资(元)...

该篇在第一章结果的基础上,对数据进行可视化分析。 地区、经验、学历,技能要求。 #薪资水平的分布
前程无忧成都招聘岗位样本数43100个,平均月薪10511元,高新区岗位7646个平均11945元,平均工资最高的几个行业为电子技术/...招聘数据-前程无忧招聘-2024年3月-成都-招聘数据治理总结分析。前程无忧招聘数据治理数据。
运用python的selenium模块爬取前程无忧网站的1万条数据
基于spark+echarts实现的互联网行业数据大屏分析源码+项目说明(数据来源于前程无忧).zip 基于spark+echarts实现的互联网行业数据大屏分析源码+项目说明(数据来源于前程无忧).zip 基于spark+echarts实现的互联网行业...
【项目资源】: 包含前端、后端、移动开发、操作系统、人工智能、物联网、信息化管理、数据库、硬件开发、大数据、课程资源、音视频、网站开发等各种技术项目的源码。 ... 【项目质量】: 所有源码都经过严格测试,...
记录一次前程无忧的接口逆向
1、导入包 小狐狸这儿有一个免费分享编程 Python相关学习资料的基地688244617 快来加入吧! import requests #取数 from lxml import etree #用xpath解析 import pymysql #连接数据库 import chardet #自动获取...
前程无忧网数据分析报告
标签: 数据分析


2、前程无忧的招聘岗位信息数据固定的放在HTML的各个标签内,通过id选择器、标签选择器和组合选择器可以诸如公司名、岗位名称和薪资等11个字段的数据。 3、基于上述1和2,可以通过解析检索“大数据”得到的URL得到其...
摘要随着互联网行业的兴起,计算机行业相关的招聘信息不胜枚举。前程无忧作为全国性权威人才招聘网站,拥有全国最大的职位信息库, 它提供了最新最全最准确的信息,为企业
首先说明这篇文章的数据来源,为前程无忧中所有“数据分析师”这一职位信息所得来的。并且主要分析了数据分析师在全国不同地区的需求情况、总体薪酬情况、不同城市薪酬分布、不同学历薪酬分布、不同地区学历要求情况...
1.了解招聘网站的数据分析目标 2.学会针对不同的网站设计数据存储方式 3.掌握数据存储相关的库
项目介绍 主要目标: 1、了解与IT行业的就业市场信息,打造自身的职业规划路线 ... 1、网页数据采集:scrapy、urllib、re 2、数据存储:MySQL 3、文字切割、词频统计:pandas、jieba、collections 4...
51job-广深数据挖掘岗位爬取scrapy项目目录下开启爬虫提取岗位详细信息,为以后数据分析做准备scrapy的异步性能还是很不错的,同比相同数据量下用request、lxml写的多线程爬虫性能要高出百分之50以上!
前程无忧爬虫,仅供学习使用
标签: 学习 爬虫
前程无忧爬虫–仅供学习使用 前程无忧职位链接:https://search.51job.com/list/090200,000000,0000,00,9,99,大数据,2,1....
(小白第一次学习整合)关于前程无忧平台数据分析师求职的薪资水平分析 @[项目目录] 数据爬取 数据清洗 数据描述分析 词云图绘制 分组统计汇报 建立模型 特征选择 模型比较及调参 模型预测 小结 数据爬取 import ...
推荐文章
- Android RIL框架分析-程序员宅基地
- Python编程基础:第六节 math包的基础使用Math Functions_ps math function-程序员宅基地
- canal异常 Could not find first log file name in binary log index file_canal could not find first log file name in binary-程序员宅基地
- 【练习】生成10个1到20之间的不重复的随机数并降序输出-程序员宅基地
- linux系统扩展名大全,Linux系统文件扩展名学习-程序员宅基地
- WPF TabControl 滚动选项卡_wpf 使用tabcontrol如何给切换的页面增加滚动条-程序员宅基地
- Apache Jmeter常用插件下载及安装及软硬件性能指标_jmeter插件下载-程序员宅基地
- SpringBoot 2.X整合Mybatis_springboot2.1.5整合mybatis不需要配置mapper-locations-程序员宅基地
- ios刷android8.0,颤抖吧 iOS, Android 8.0正式发布!-程序员宅基地
- 【halcon】C# halcon 内存暴增_halcon 读二维码占内存-程序员宅基地