中文分词在文本处理和信息检索中扮演着重要的角色。本文将介绍IK分词器,一个基于Lucene的开源中文分词...我们将详细讨论IK分词器的特点和使用方法,并提供一个简单的Java示例来演示如何使用IK分词器进行中文文本分词。
”中文分词器“ 的搜索结果
本文的目标有两个: 1、学会使用10大Java开源中文分词器 ...2、对比分析10大Java开源中文分词器的分词效果 ...本文给出了10大Java开源中文分词的使用方法以及分词结果对比代码,至于效果...10大Java开源中文分词器,
jieba(结巴分词)是一个开源的中文分词工具,用于将中文文本切分成词语或词汇单位。它是一个 Python 库,广泛用于自然语言处理(NLP)和文本分析领域。中文分词:jieba 可以将中文文本按照词语切分,使得文本可以更...
ES默认的analyzer(分词器),对英文单词比较友好,对中文分词效果不好。不过ES支持安装分词插件,增加新的分词器。1、如何指定analyzer?默认的分词器不满足需要,可以在定义索引映射的时候,指定text字段的分词器...
IKAnalyaer中文分词器,配合slor使用,让你的搜索效果更佳
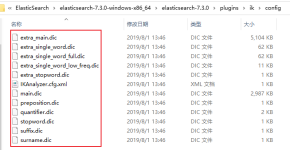
在 ik 的文件的 config 目录下有 ik 分词的配置文件(IKAnalyzer.cfg.xml)以及相关的 dic 字典文件。在ES home/plugins 目录下创建目录 ik,并将我们下载下zip包解压到 es_home/plugins/ik 目录下。远程扩展字典的...
基于 Java 的中文分词器分词效果评估对比项目。它主要实现了以下功能: 分词效果评估:用户可以通过程序对比不同分词器的分词结果,以及计算分词速度、行数完美率、行数错误率、字数完美率、字数错误率等指标。 ...
solr全文检索引擎默认对中文的支持不好,使用中文分词器后可以准确的按照中文词语进行分词,该资源是其中一种,测试环境:linux
但这些分词器对我们最常使用的中文并不友好,不能按我们的语言习惯进行分词。ik分词器就是一个标准的中文分词器。它可以根据定义的字典对域进行分词,并且支持用户配置自己的字典,所以它除了可以按通用的习惯分词外...
IK-Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包,也就是可以将一串中文字符分割成一个个的词组或者字词 文件中包含分词工具 ikanalyzer-2012_u6.jar 中文分词配置 IKAnalyzer.cfg..xml
绝对可以用哈,我工程都在用,所以放心的使用,积分也不高的就5分
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。可用于solr和Lucene
用于elasticsearch7.6.2配套的中文分词器,欢迎大家使用 下面是它的描述,用于elasticsearch7.6.2配套的中文分词器,
elasticsearch-7.0.0版本 ik中文分词器,编译好的文件,亲测成功,2.4.6版本的见在本人其他资源中寻找,免费下载,成功请给好评。
对于ES IK分词插件在中文检索中非常常用,本人也使用了挺久的。但知识细节一直很碎片化,一直没有做详细的整理。过一段时间用的话,也是依然各种找资料,也因此会降低开发效率。所以在有空的时候好好整理下相关资料...
因为es本身的分词器对中文不是特别友好,所以使用ik分词器,分为 两种 模式,一种是粗 模式,一种是细模式,还希望能帮助到刚刚接触的人
solr在7.0后内部集成有自己的中文分词器,但是其内部的分词器只是机械的分词,使用插件将更符合中文分词的习惯!
Friso高性能中文分词器框架源码,包含开发文档。 Friso 是使用 c 语言开发的高性能中文分词器,使用流行的mmseg算法实现。完全基于模块化设计和实现,可以很方便的植入其他程序中, 例如:MySQL,PHP,并且提供了...
一个微型的中文分词器,目前提供了以下几种分词算法: 按照词语的频率(概率)来利用构建 DAG(有向无环图)来分词,使用 Trie Tree 构建前缀字典树 使用隐马尔可夫模型(Hidden Markov Model,HMM)来分词 融合 DAG...
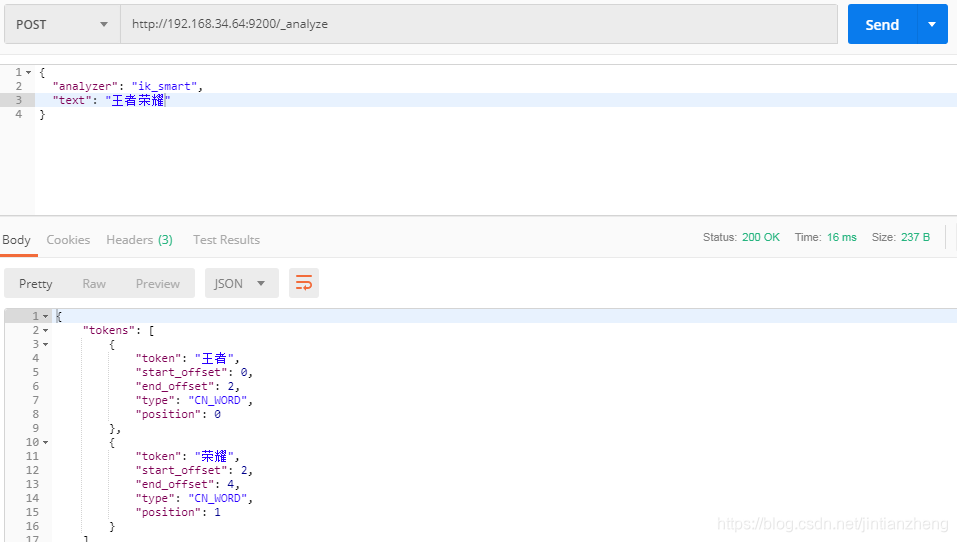
以上用例是使用 analyzer 指定英文分词器查看分词结果,如果field是索引里的字段,会使用字段指定的分词器进行分词。 接下来进入测试。 默认分词器 默认使用standar分词器 在不标明的时候都是使用默认的standar...
ik分词器tar包 7.10.2
elasticsearch的ik中文分词器,安装好elasticsearch后还需安装中文分词器
中文分词器ik-analyzer-solr5-5.x.jar,已经打包好,直接用就可以
一个微型的中文分词器,目前提供了以下几种分词算法: 按照词语的频率(概率)来利用构建 DAG(有向无环图)来分词,使用 Trie Tree 构建前缀字典树 使用隐马尔可夫模型(Hidden Markov Model,HMM)来分词 融合 DAG...
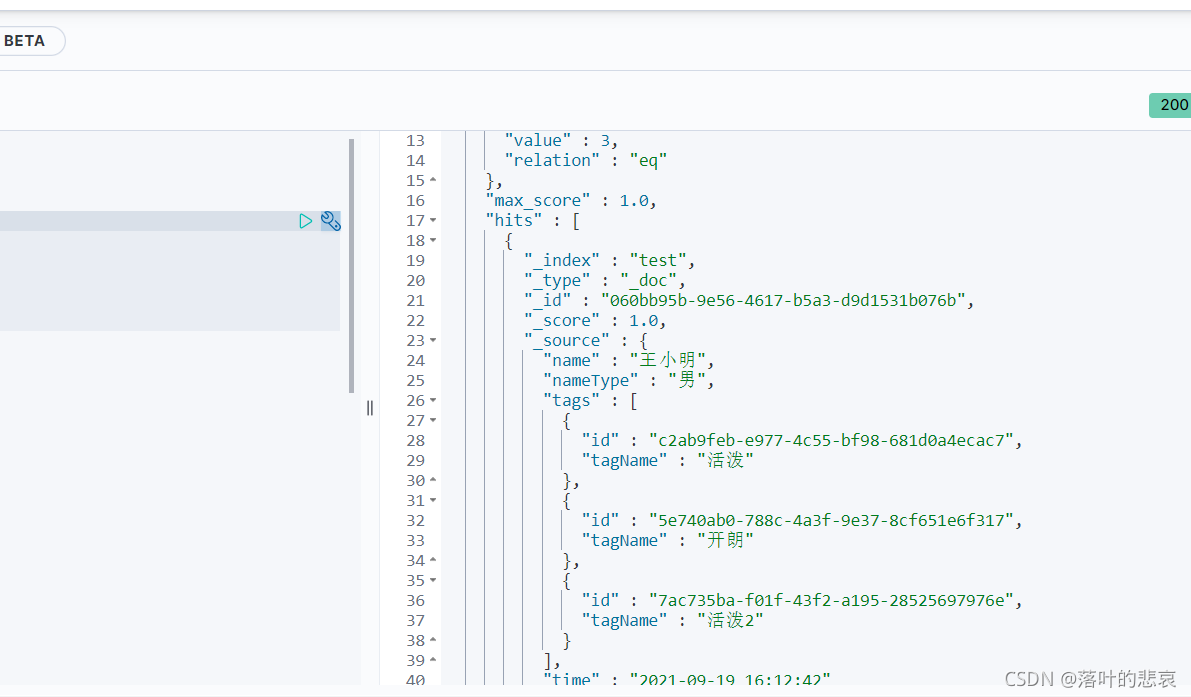
所有字段检索 高亮搜索 分词测试 GET /test_index/_analyze jieba中文分词支持添加禁用词和扩展词库功能 创建索引:PUT http://xxxx:9200/test_index 分词测试: GET http://xxxxxx:9200/test_index/_analyze
elasticserach 7.17.4版本的中文 IK分词器
文章目录分词器以及ik中文分词器概念ik分词器的安装环境准备设置jdk环境变量下载maven安装包并解压设置path验证maven是否安装成功下载IK分词器并安装使用IK分词器查询文档term词条查询match全文查询 分词器以及ik...
推荐文章
- c语言链表查找成绩不及格,【查找链表面试题】面试问题:C语言学生成绩… - 看准网...-程序员宅基地
- 计算机网络:20 网络应用需求_应用对网络需求-程序员宅基地
- BEVFusion论文解读-程序员宅基地
- multisim怎么设置晶体管rbe_山东大学 模电实验 实验一:单极放大器 - 图文 --程序员宅基地
- 华为OD机试真题-灰度图恢复-2023年OD统一考试(C卷)-程序员宅基地
- 【机器学习】(周志华--西瓜书) 真正例率(TPR)、假正例率(FPR)与查准率(P)、查全率(R)_真正例率和假正例率,查准率,查全率,概念,区别,联系-程序员宅基地
- Python Django 版本对应表以及Mysql对应版本_django版本和mysql对应关系-程序员宅基地
- Maven的pom.xml文件结构之基本配置packaging和多模块聚合结构_pom <packaging>-程序员宅基地
- Composer 原理(二) -- 小丑_composer repositories-程序员宅基地
- W5500+F4官网TCPClient代码出现IP读取有问题,乱码问题_w5500 ping 网络助手 乱码 send(sock_tcps,tcp_server_buff,-程序员宅基地