
”spark“ 的搜索结果
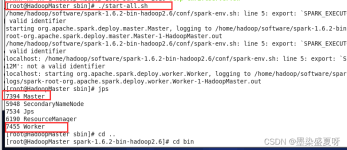
一、Spark单机模式部署 Spark版本 : spark-2.4.7-bin-hadoop2.7 1、安装配置JDK环境 2、下载Spark 官网下载http://spark.apache.org/ 然后上传到LInux服务器上 3、解压 tar -zxvf spark-2.4.7-bin-hadoop2.7.tgz ...


Spark自带example
标签: spark

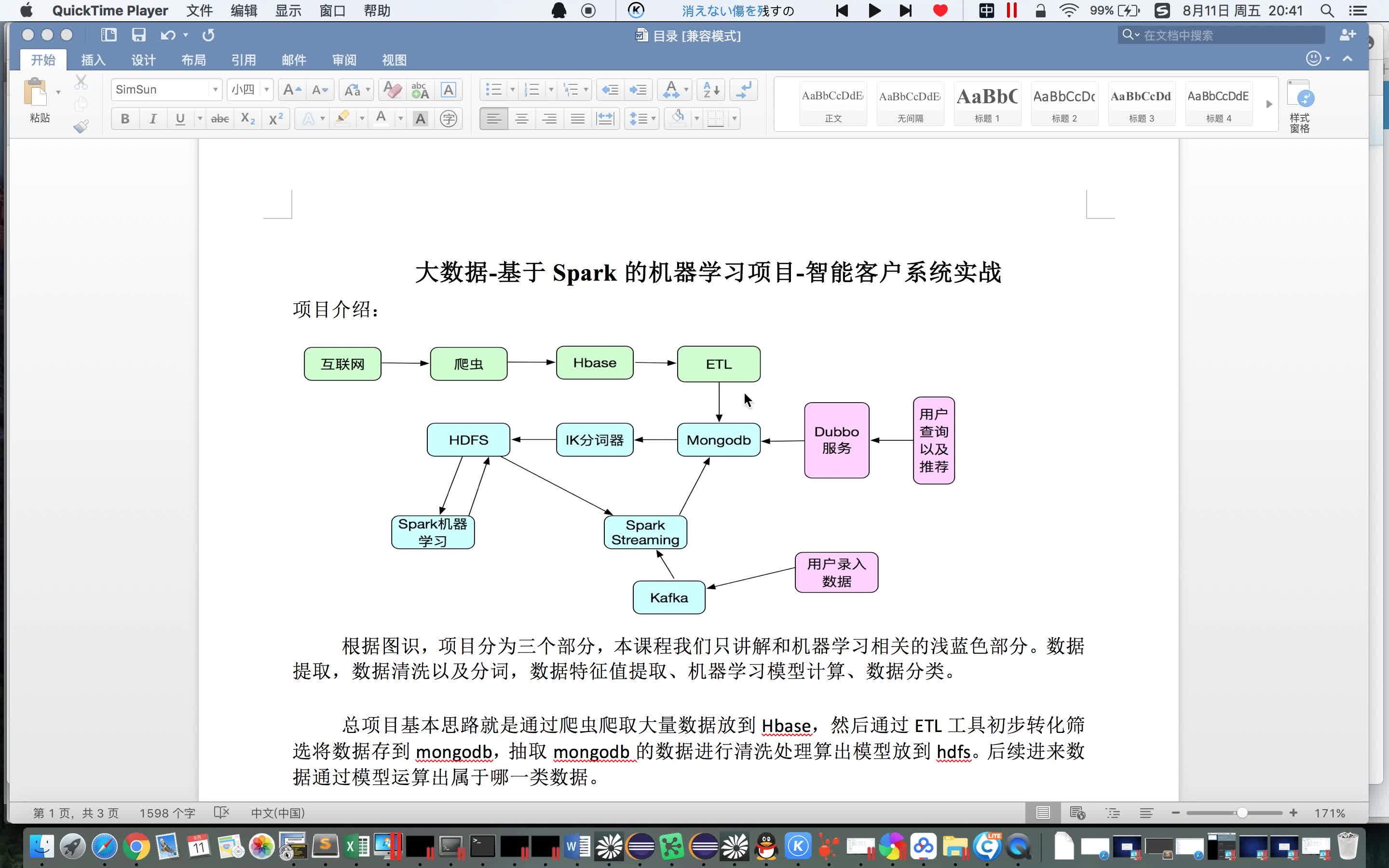
需求:需要通过spark对redis里面的数据进行实时读写 实现方案:通过建立连接池,在每台机器上单独建立连接,进行操作 1、利用lazy val的方式进行包装 class RedisSink(makeJedisPool: () => JedisPool) ...

目前Spark官方提供的最新版本3.2.0,是2021年10月份发布,但是该版本搭建Windows下环境,在使用spark-shell时,会报以下错误,尚无解决方案。 退而求其次,使用Spark3.1.2,则完全正常。 本次搭建环境,所使用到的...
Springboot+Spark

hive on spark
Spark 参数设置
标签: spark
Spark系统的性能调优是一个很复杂的过程,需要对Spark以及Hadoop有足够的知识储备。从业务应用平台(Spark)、存储 (HDFS)、操作系统、硬件等多个层面都会对性能产生很大的影响。借助于多种性能监控工具,我们可以...
英特尔大数据技术中心研发经理黄洁在OpenCloud 2015大会Spark专场的演讲PPT:Spark优化及实践经验分享,就Spark的内存管理、IO提升和计算优化3个方面进行了详细讲解。对于Spark,黄洁表示,它将成为大数据的一个重要...
Spark单节点部署 1. 找到安装文件 1 find / -name spark*.tgz 2. 解压文件到指定目录 1 tar -zxvf ~/experiment/file/spark-2.2.0-bin-hadoop2.7.tgz -C /opt 3. 重命名 1 mv /opt/spark-2.2.0-bin-hadoop2.7 /...


Hive on Spark配置
标签: hive

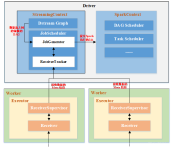



执行spark-shell报错 [root@hadoop101 conf]# spark-shell 2.报错 Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 2020-...

推荐文章
- spring cloud alibaba整合sentinel_dependency com.alibaba.cloud:spring-cloud-starter--程序员宅基地
- 基于GWO-CNN-LSTM-Attention超前24步多变量回归预测模型 多特征输入,单输出,MATLAB 要求2023及以上版本_前24步多变量回归预测算法-程序员宅基地
- Flutter环境配置 mac版_flutter 配置国内镜像源 mac-程序员宅基地
- GIT更新流程_git 更新-程序员宅基地
- 36V-48V供电系统的稳压芯片CSM7387_以太网芯片48v开入电压-程序员宅基地
- jquery Sortable实例_jq js sortable 案例-程序员宅基地
- Hive JDBC连接Tez(AM)容器长期不释放问题的解决方法_hive tez引擎 执行alter 添加分区操作, 客户端显示ok 为什么yarn上显示还在用户-程序员宅基地
- 几大高效分页存储过程汇总-程序员宅基地
- 网络用户名共享想不到计算机,我有个文件夹只想和另一台计算机的用户共享,不想让其他用户看到,请问高手如何设置共享密码?...-程序员宅基地
- COSMIC度量知识整理_cosmic 一个子处理可以是-程序员宅基地