A.Spark Streaming B MLlib C Graph X D Spark R 2. Hadoop框架的缺陷有 (ABC) A.表达能力有限,MR编程框架的限制 B.过多的磁盘操作,缺乏对分布式内存的支持 C.无法高效低支持迭代式计算 D.海量的数据存储 3. 与...
”spark“ 的搜索结果
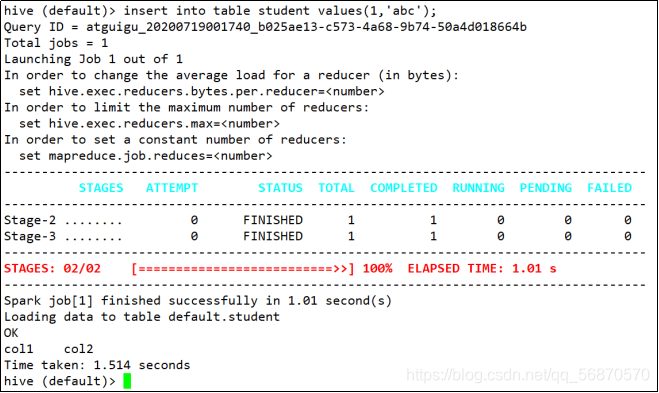
spark on hive : hive只作为存储角色,spark 负责sql解析优化,底层运行的还是sparkRDD 具体可以理解为spark通过sparkSQL使用hive语句操作hive表,底层运行的还是sparkRDD, 步骤如下: 1.通过sparkSQL,加载...

Spark独立集群管理器,一种简单的Spark集群管理器,很容易建立集群,基于Spark自己的Master-Worker集群 Apache Mesos,一种能够运行Haoop MapReduce和服务应用的集群管理器 Hadoop YARN,Spark可以和...
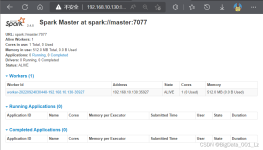
当以分布式集群部署的时候,可以根据自己集群的实际情况选择Standalone模式(Spark自带的模式)、Spark on YARN模式或者Spark on mesos模式。Spark的各种运行模式虽然在启动方式、运行位置、调度策略上各有不同,但...

Spark Installation with Maven & Eclipse IDE 文章目录Spark Installation with Maven & Eclipse IDE安装说明Maven & Eclipse IDE说明参考网站安装过程JDK安装Eclipse IDE安装Maven安装Spark安装新建...
spark为什么快
:quit
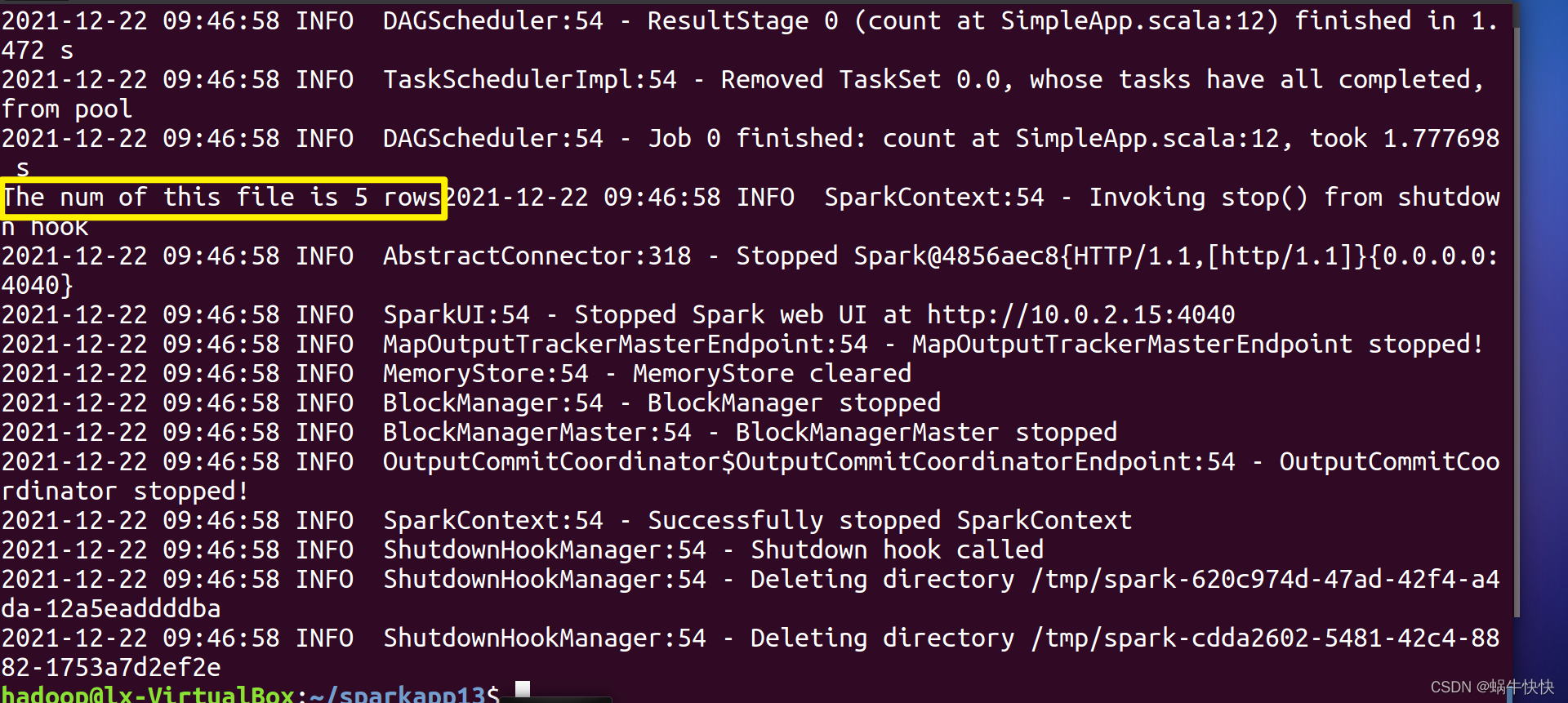
Table or view not found: aaa.bbb The column number of the existing table dmall_search.query_embedding_data_1(struct<>) doesn’t match the data schema(struct<user_id:string,dt:string,sku_list:...


本篇博客,Alice为大家带来关于Spark命令的详解。 ...之前我们使用提交任务都是使用spark-shell提交,spark-shell是Spark自带的交互式Shell程...
这样,你就可以在 Spark 项目中使用 Scala 连接 MySQL 5.6 并进行数据的读取和写入。在 Spark 项目中,你需要在项目的构建工具中添加 MySQL 连接驱动的依赖。将 DataFrame 中的数据保存到 MySQL。在 Spark 项目中...

本人维护的Spark主要运行在三个Hadoop集群上,此外还有其他一些小集群或者隐私集群。这些机器加起来有三万台左右。目前运维的Spark主要有Spark2.3和Spark1.6两个版本。用户在使用的过程中难免会发生各种各样的问题,...
Spark、Python spark、Hadoop简介 Spark简介 1、Spark简介及功能模块 Spark是一个弹性的分布式运算框架,作为一个用途广泛的大数据运算平台,Spark允许用户将数据加载到cluster集群的内存中储存,并多次重复...
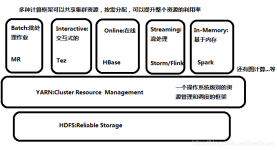


一、Spark单机模式部署 Spark版本 : spark-2.4.7-bin-hadoop2.7 1、安装配置JDK环境 2、下载Spark 官网下载http://spark.apache.org/ 然后上传到LInux服务器上 3、解压 tar -zxvf spark-2.4.7-bin-hadoop2.7.tgz ...

推荐文章
- 【UBUNTU】ubuntu18.04安装及更新_ubuntu18更新-程序员宅基地
- OpenSSL心脏滴血漏洞(CVE-2014-0160)_openssl漏洞的原因是-程序员宅基地
- 数据结构实验-哈夫曼编码_待编码数据-程序员宅基地
- dataframe的索引遍历_pandas | 如何在DataFrame中通过索引高效获取数据?-程序员宅基地
- 位置传感器_lbk位置传感器-程序员宅基地
- dubbo 报错:java.lang.NoClassDefFoundError: org/I0Itec/zkclient/exception/ZkNoNodeException_dubbo nested exception is java.lang.noclassdeffoun-程序员宅基地
- Spring Boot 2.x 整合 ShardingSphere 5.0.0 实现分库分表_整合shardingsphere-jdbc-core-spring-boot-starter-程序员宅基地
- 表白编码C语言,C语言告白代码,一闪一闪亮晶晶~-程序员宅基地
- mycat_wrapper-linux-aarch64-64-程序员宅基地
- 支持向量机的核函数选择:影响性能的关键因素-程序员宅基地