”spark“ 的搜索结果
一、Spark简介 【1】什么是Spark? Apache Spark是用于大规模数据处理的统一分析引擎,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序 【2】Spark特点 运行速度快:Spark有先进的...
spark数据处理databrickssparkknowledgebase共22页.pdf.zip
毕业设计 课程设计 项目开发 系统开发 Spark 机器学习 大数据 算法 源码 毕业设计 课程设计 项目开发 系统开发 Spark 机器学习 大数据 算法 源码 毕业设计 课程设计 项目开发 系统开发 Spark 机器学习 大数据 算法 ...
Spark on Yarn详解
标签: spark
Spark on Yarn详解 Spark 可以跑在很多集群上,比如跑在local上,跑在Standalone上,跑在Apache Mesos上,跑在Hadoop YARN上等等。不管你Spark跑在什么上面,它的代码都是一样的,区别只是–master的时候不一样。...
spark数据处理sparkinmemoryclustercomputingforiterativeandinteractiveapplications共43页.pdf.zip
毕业设计-基于Hadoop+Spark的大数据金融信贷风险控系统源码.zip

spark3.1.2 单机安装部署 概述 Spark是一个性能优异的集群计算框架,广泛应用于大数据领域。类似Hadoop,但对Hadoop做了优化,计算任务的中间结果可以存储在内存中,不需要每次都写入HDFS,更适用于需要迭代运算的...
今天的文章,我们来学习我们回归中的逻辑回归,并带来简单案例,学习用法。希望大家能有所收获。同时,希望我的文章能帮助到每一个正在学习的你们。也欢迎大家来我的文章下交流讨论,共同进步。
主要是获取sparkcontext对象,基于对象作为执行环境入口。通过submit客户端工具进行提交,代码中不要设置master。代码中的文件要所有节点都要能访问到,可以是分布式文件系统。
mv spark-2.1.2-bin-hadoop2.7 ./spark 解压到目标目录即完成安装, spark 解压后主要包含如下子目录: bin/ (工具程序目录) conf/ (配置文件目录) jars/ (scala Jar 包目录) python/ (python package 目录) ...
在短视频流行的当下,推荐引擎扮演着极其重要的角色,而要想达到最佳的推荐效果,推荐引擎必须依赖用户的实时反馈。所谓实时反馈,其实就是我们习以为常的点赞、评论、转发等互动行为,不过,这里需要突出的,是一个...
spark read mysql
Spark on Hive & Hive on Spark你分清了吗
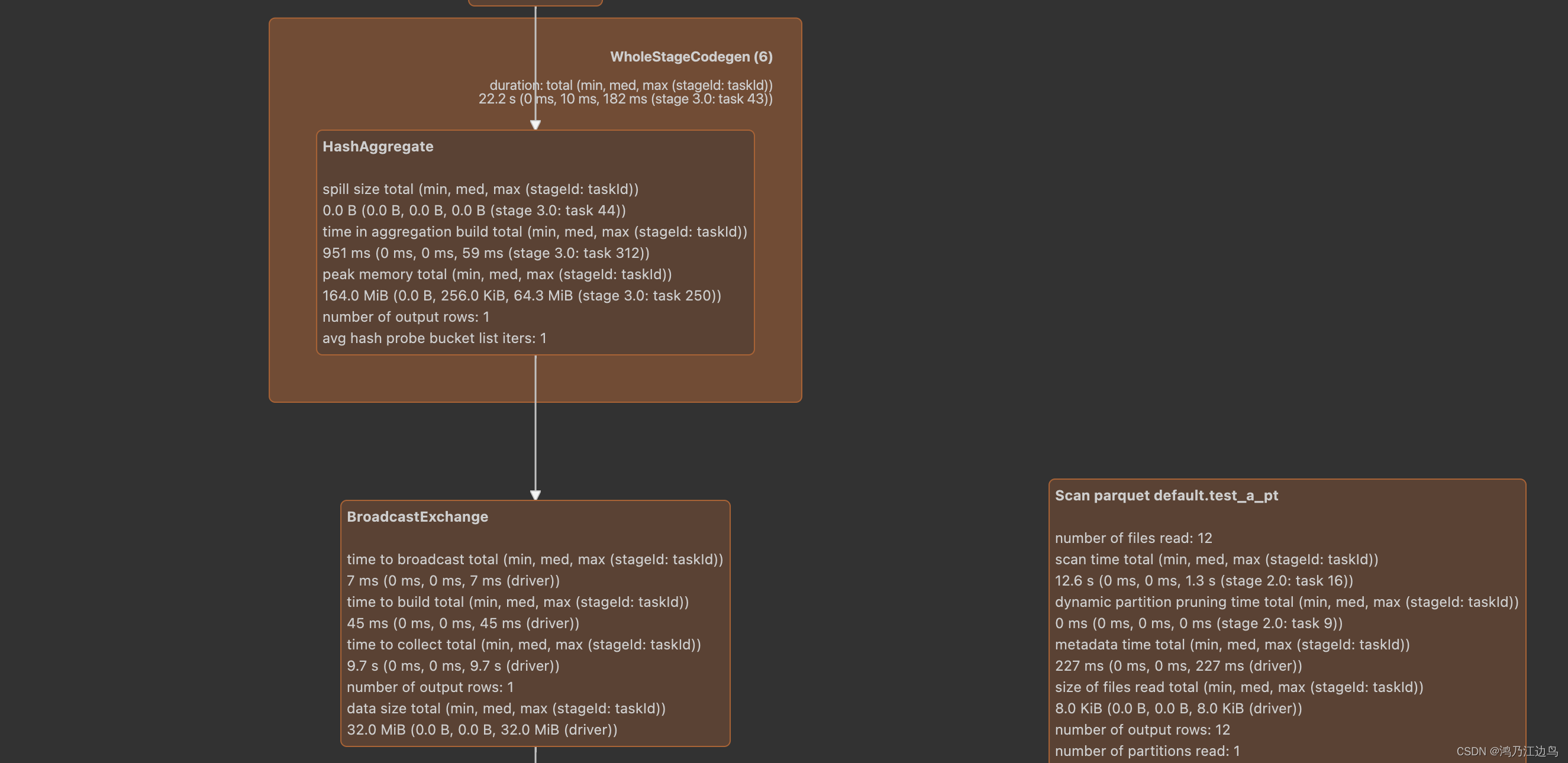
Spark 集群的独立部署环境中,不需要依赖其他的资源调度框架,自身就实现了资源调度的功能,所以环境中还有其他两个核心组件:Master和Worker,这里的Master是一个进程,主要负责资源的调度和分配,并进行集群的监控...
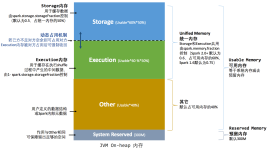
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点...
Hive on Spark:Hive既作为存储元数据又负责SQL的解析优化,语法是HQL语法,执行引擎变成了Spark,Spark负责采用RDD执行。 Spark on Hive : Hive只作为存储元数据,Spark负责SQL解析优化,语法是SparkSQL语法,...

Spark-Shell操作 spark-shell简述 spark-shell是REPL(Read-Eval-Print Loop,交互式解释器),它为我们提供了交互式执行环境,表达式计算完成以后就会立即输出结果,而不必等到整个程序运行完毕,因此可以及时...
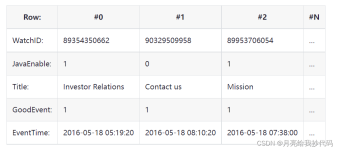
spark读取clickhouse数据 一:这种jdbc的连接加载的是全量表数据 val prop = new java.util.Properties prop.setProperty("user", "default") prop.setProperty("password", "123456") prop.setProperty("driver...
hue执行不用引擎sql导致任务中断
Hadoop和Spark都是并行计算,Hadoop一个作业称为一个Job,Job里面分为Map Task和Reduce Task阶段,每个Task都在自己的进程中运行,当Task结束时,进程也会随之结束; 好处在于进程之间是互相独立的,每个task独享...
RDD(弹性分布式数据集合)是Spark的基本数据结构,Spark中的所有数据都是通过RDD的形式进行组织。本文讲解RDD的属性、创建方式、广播与累加器等重要知识点,并图解RDD高频算子。
Spark是一种基于内存的快速的、通用、可拓展的大数据分析计算引擎。 一、Spark与MapReduce Hadoop框架中的MapReduce计算引擎,也是一种大数据分析计算引擎。那既然已经又来MR那我们为何还要开发Spark计算模型呢?...
花了将近一个月时间学习了Spark,为了总结所学知识,我用ProcessOn绘制了几张Spark思维导图 这里是Spark思维导图地址 Spark思维导图地址 注意:需要有ProcessOn账号才能查看 1.Spark 入门 2.Spark Core 3.Spark ...
推荐文章
- 【Java进阶】线程池之无限队列 - 使用工厂类Executors.newFixedThreadPool(n) ,创建无限队列线程池_线程池无限队列-程序员宅基地
- python 之路,致那些年,我们依然没搞明白的编码-程序员宅基地
- 国二报C语言,国二C语言.doc-程序员宅基地
- FTP快速搭建-程序员宅基地
- [原创]我的WCF之旅(7):面向服务架构(SOA)和面向对象编程(OOP)的结合——如何实现Service Contract的继承_servicecontract using-程序员宅基地
- openmediavault(OMV) (18)云相册(2)photoprism-程序员宅基地
- VS2017使用protobuf动态链接库的编译错误问题_vs2017运行不了protobuf项目-程序员宅基地
- idea右键项目没有出现git选项、idea工具栏没有Git快捷图标_idea 右键没有git-程序员宅基地
- m3u8索引文件介绍_69嗉媂x.m3u8-程序员宅基地
- 2021 泰迪杯 A 题_第十二届泰迪杯数据挖掘竞赛a题论文-程序员宅基地