
”spark“ 的搜索结果
Spark系列之SparkSubmit提交任务到YARN
一、SparkSQL相关 1.在执行insert 语句时报错,堆栈信息为:FileSystem closed。常常出现在ThriftServer里面。 原因:由于hadoop FileSystem.get 获得的FileSystem会从缓存加载...2.在执行Spark过程中抛出:Failed t

什么是Spark Spark特点 Spark运行模式 Spark编写代码 SparkCore 什么是RDD RDD的主要属性 RDD的算子分为两类: Rdd数据持久化什么作用? cache和Checkpoint的区别 什么是宽窄依赖 什么是DAG DAG边界 ...
自行查看

大数据 hadoop spark hbase ambari全套视频教程(购买的付费视频)

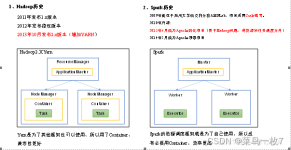
一、面试题Spark通常来说,Spark与MapReduce相比,Spark运行效率更高。请说明效率更高来源于Spark内置的哪些机制?hadoop和spark使用场景?spark如何保证...
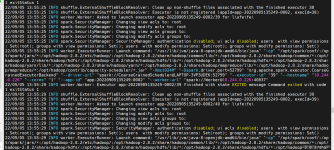
spark安装&部署过程
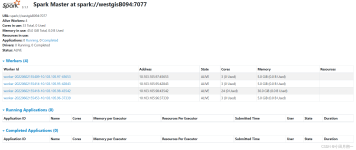
spark任务运行后,会将Driver所在机器绑定到4040端口,提供当前任务的监控页面。 此端口号默认为4040,展示信息如下: 调度器阶段和任务列表 RDD大小和内存使用情况 环境信息 正在运行的executors的信息 ...

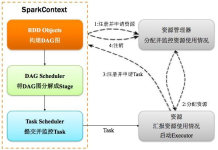
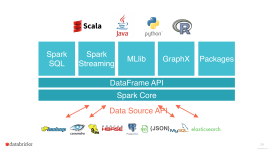
简单的spark概述: 原文: Apache Spark is a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general ...

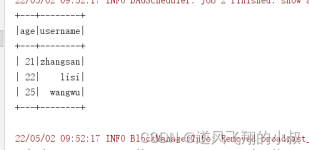
Spark SQL里面有很多的参数,而且这些参数在Spark官网中没有明确的解释,可能是太多了吧,可以通过在spark-sql中使用set -v 命令显示当前spark-sql版本支持的参数。 本文讲解最近关于在参与hive往spark迁移过程中...

安装Spark之前,需要安装JDK、Hadoop、Scala。显示上面的正常运行界面,表示本地的spark环境已搭建完成!环境变量Path添加条目%SCALA_HOME%\bin。为了验证Scala是否安装成功,开启一个新的cmd窗口。环境变量Path添加...

Spark参数配置和调优,Spark-SQL、Config
If so, this book will be your companion as you create data-intensive app using Spark as a processing engine, Python visualization libraries, and web frameworks such as Flask. To begin with, you will...

1、在存储方式上,HDFS以文件为单位,每个文件大小为 64M~128M, 而mongo则表现的更加细颗粒化; 2、MongoDB支持HDFS没有的索引概念,所以在读取速度上更快; 3、MongoDB更加容易进行修改数据; ...
推荐文章
- [源码解析] 机器学习参数服务器ps-lite 之(3) ----- 代理人Customer-程序员宅基地
- 卷积神经网络笔记--吴恩达深度学习课程笔记(四)_卷积神经 特征平面-程序员宅基地
- ANSYS无限大平板两边传热仿真_ansys热仿真-程序员宅基地
- SpringBoot使用prometheus监控_spring security 只开启/actuator/promethues断点-程序员宅基地
- Redis数据结构_redis取值fet list-程序员宅基地
- 为什么在java中计算2的32次方可以用1L左移32表示_java中2的32次方如何表示-程序员宅基地
- ADC触摸屏编程测试笔记_韦东山老师_adc_cnt-程序员宅基地
- 查看堆栈信息_hprof文件可以看到堆栈信息-程序员宅基地
- service和systemctl的区别_systemctl service-程序员宅基地
- Spine 事件-程序员宅基地