通过对scrapy框架的几大组成模型通俗细致的讲解,让大家可以非常清楚地理解scrapy框架的整体工作流程。
”scrapy爬虫“ 的搜索结果
自定义下载中间件可以让我们在遇到重定向时重新发起请求。# 当状态码为301或302时,重新发起请求# 其他状态码直接返回响应。
Scrapy爬虫框架入门(豆瓣电影Top 250)

我们通过以上学习,仅编写了2行代码,就完成了爬取数据的工作。
【代码】scrapy爬虫实战(部分源代码)
python爬虫实践(部分源代码)......
此部分代码是使用scrapy框架进行爬虫的实例,按照以下文章分享的内容进行整理的https://cuiqingcai.com/3472.html,欢迎有兴趣的同学进行下载学习。
此项目的功能是爬取知乎用户信息以及人际拓扑关系,爬虫框架使用scrapy,数据存储使用mongo,下载这些数据感觉也没什么用?分析、图谱甚至是学习Scrapy框架作为一个很好的示例 ### 本地运行 爬虫程序依赖mongo和...
scrapy爬虫之热门网站数据爬取 1、很详细地完成了对scrapy的使用 2、其中有对正则表达式的详细使用 3、有对xpath和css选择器的使用 4、有对scrapy中的item、pipeline等类的修改和使用
[Scrapy爬虫项目搭建与配置详解](https://images2017.cnblogs.com/blog/1273425/201711/1273425-20171106173149950-2052668055.png) # 1. 介绍 在信息爆炸的时代,数据是至关重要的资源。为了获取海量数据,人们...
本源码提供了一个基于Python的Scrapy爬虫框架设计。项目包含20个文件,其中包括6个Python字节码文件、6个Python源文件、3个XML文件、1个Gitignore文件、1个IML文件、1个CSV文件、1个TXT文件和1个CFG文件。这个项目是...
基于scrapy框架的爬虫代码,示例包括一些网站二级爬虫。
本项目是基于Python的Scrapy爬虫框架设计源码,包含22个文件,其中主要包含12个py源代码文件,4个xml配置文件等。系统采用了Python编程语言,实现了网站爬虫的功能,可以高效地抓取网站数据。项目结构清晰,代码...
优化Scrapy爬虫的并发性能
标签: 开发技术
然后,我们将带领您步骤创建第一个Scrapy爬虫,涵盖了安装Scrapy及相关依赖的过程,以及如何编写基本的Scrapy爬虫脚本。通过本章的学习,您将对Scrapy爬虫框架有一个清晰的认识,能够开始构建自己的网络爬虫项目。...
Scrapy+Python 抓取花瓣网不同主题的图片,仅用于个人练习,不作于商业用途

这是创建scrapy项目后默认创建的管道类,也可以自行新建别的管道,这里一般就会用来接受spider传过来的数据并对其进行**[打包]**创建目录后spiders里是空的,这时候就需要我们创建第一个爬虫文件。成功,内容和正常...
# 1.1 什么是网络爬虫? 网络爬虫是一种自动化程序,用于在互联网上提取信息。通过模拟人类浏览器的行为,爬虫可以访问网页、提取数据,并对数据进行分析和处理。网络爬虫的应用领域非常广泛,包括搜索引擎的建立、...

Scrapy爬虫框架 笔趣阁小说抓取 知识点:Scrapy爬虫框架使用 Scrapy爬虫框架使用 scrapy爬虫开发的基本步骤 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目 明确目标 (编写items.py):明确你想要抓取...
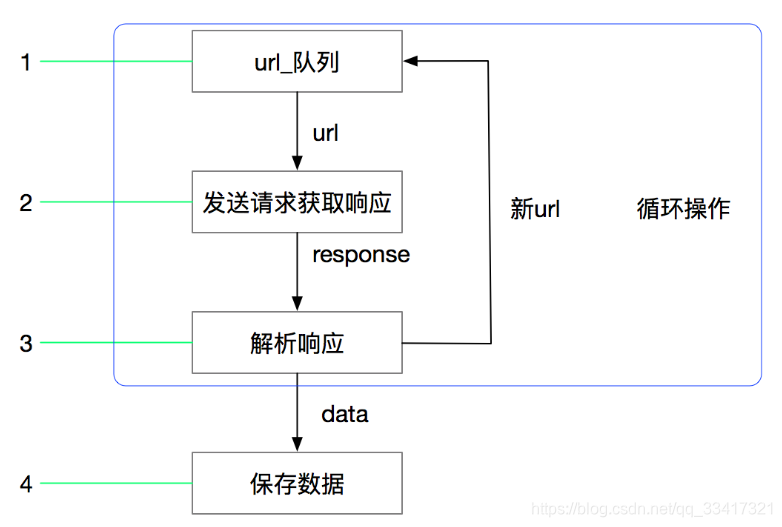
通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。1.引擎(Engine)– 引擎负责控制数据流在系统所有组件中的流向,并在不同的条件时触发相对应的事件。这个组件相当于爬虫的“大脑”...
piplines.py 爬虫项目的管道文件,主要用来对items里面定义的数据进行进一步的加工与处理。__init__.py 此文件为项目的初始化文件,主要写的是一些项目的初始化信息items.py 爬虫项目的数据容器文件,主要用来定义...
一个简单的爬虫,工程文件结构齐全,可直接使用,与博客文章同步分享。

目录Scrapy是啥Scrapy的安装实例:爬取美剧天堂new100:(1)创建工程:(2) 创建爬虫程序(3) 编辑爬虫(4)设置item模板:(5) 设置配置文件(6)设置数据处理脚本:(7)运行爬虫 Scrapy是啥 scrapy是一个使用python...
scrapy爬虫爬取oschina开源中国博客文章保存到本地数据库。 这个是本人最近学习爬虫的一个实践案例,源码解析详情请移步博文:https://blog.csdn.net/xiaocy66/article/details/83834261
Scrapy 爬虫教程实践
推荐文章
- 小说网站系统源码|PHP付费小说网站源码带app-程序员宅基地
- Swift编码规范_swift 正则判断文件类型-程序员宅基地
- 关于shell 中return用法解释(转)_shell return-程序员宅基地
- Linux编译宏BUILD_BUG_ON_ZERO-程序员宅基地
- c51语言单片机打铃系统设计,基于单片机的自动打铃系统的设计-程序员宅基地
- 在php中使用SMTP通过密抄批量发送邮件-程序员宅基地
- python数据清洗+数据可视化_python课程题目数据清除与可视化-程序员宅基地
- 【11g】3.3 Oracle自动存储管理存储配置_oraclestorageoptions-程序员宅基地
- signature=b2f9171fa2897cefe08a669efaf58433,FULFILLMENT TRACKING IN ASSET-DRIVEN WORKFLOW MODELING-程序员宅基地
- 宜兴市计算机中等学校,重磅!江苏省陶都中等专业学校正式揭牌!-程序员宅基地