
”scrapy爬虫“ 的搜索结果

这是我写的一个爬取三七中文网一个网站的小说的爬虫,爬虫是基于scrapy框架的,比较简单,可以使用,也适合初学者.爬取的小说放到了MySQL数据库中.


Scratch,是抓取的意思,这个Python的爬虫框架叫Scrapy,大概也是这个意思吧,就叫它:小刮刮吧。 小刮刮是一个为遍历爬行网站、分解获取数据而设计的应用程序框架,它可以应用在广泛领域:数据挖掘、信息处理和或者...
scrapy爬虫框架
标签: python


安装 在终端输入pip install,如果速度太慢指定国内镜像安装pip ...执行scrapy genspider 爬虫文件名 域名 如scrapy genspider lagou www.lagou.com,会在spiders文件夹中生成名为lagou.py的爬虫模板文件,该方式是
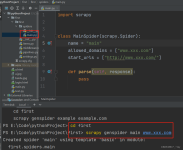
1 爬虫示例 要实现爬虫功能,只要执行四个步骤: 定义spider 类 确定 spider 的名称(name) 获取初始化请求(start_request) 解析数据 parse() 1.1 示例1 重写 start_request() 方法 示例1:重写 start_request() ...
Scrapy是一个功能强大并且非常快速的网络爬虫框架,是非常优秀的python第三方库,也是基于python实现网络爬虫的重要的技术路线。 Scrapy的安装: 直接在命令提示符窗口执行pip install scrapy貌似不行。 我们需要先...
【课程简介】 本课程适合所有需要弥补python网络爬虫的同学,课件内容制作精细,由浅入深,适合入门或进行知识回顾。 【全套课程列表】 01-Requests库入门(共59页...12-实例4-股票数据定向Scrapy爬虫(共23页).pptx
scrapy爬虫之热门网站数据爬取 1、很详细地完成了对scrapy的使用 2、其中有对正则表达式的详细使用 3、有对xpath和css选择器的使用 4、有对scrapy中的item、pipeline等类的修改和使用.zip
该案例相对完整,欢饮下载交流。有疑问,可以留言,一起交流探讨并发掘爬虫世界的美!该案例结构清晰,注释明了,可以使大家很好地理解scrapy爬虫框架。
通过 scrapy 爬虫架构爬取中国古诗网的 唐诗三百首 通过 scrapy 爬虫架构爬取中国古诗网的 唐诗三百首 通过 scrapy 爬虫架构爬取中国古诗网的 唐诗三百首 通过 scrapy 爬虫架构爬取中国古诗网的 唐诗三百首
Scrapy爬虫框架相对于使用requests库进行网页的爬取,拥有更高的性能。 Scrapy官方定义:Scrapy是用于抓取网站并提取结构化数据的应用程序框架,可用于广泛的有用应用程序,如数据挖掘,信息处理或历史存档。 建立...
Scrapy爬虫的标准流程一般包括以下几个步骤: 1、明确需求和目标网站的结构,确定需要爬取的数据以及爬取规则。 2、创建一个Scrapy项目,使用命令行工具创建一个新的Scrapy项目。
Python实现爬虫是很容易的,一般来说就是获取目标网站的页面,对目标页面的分析、解析、识别,提取有用的信息,然后该入库的入库,该下载的下载。...这次介绍通过Scrapy爬虫框架来实现同样的功能。
本文主要通过实例介绍了scrapy框架的使用,分享了两个例子,爬豆瓣文本例程 douban 和图片例程 douban_imgs ,具体如下。 例程1: douban 目录树 douban --douban --spiders --__init__.py --bookspider.py --...
基于Python的网易新闻Scrapy爬虫:数据分析与可视化大屏展示-毕业源码案例设计.rar基于Python的网易新闻Scrapy爬虫:数据分析与可视化大屏展示-毕业源码案例设计.rar基于Python的网易新闻Scrapy爬虫:数据分析与可视...
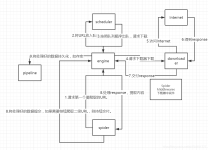
Scrapy 爬虫框架 1. 概述 Scrapy是一个可以爬取网站数据,为了提取结构性数据而编写的开源框架。Scrapy的用途非常广泛,不仅可以应用到网络爬虫中,还可以用于数据挖掘、数据监测以及自动化测试等。Scrapy是基于...
用scrapy框架爬取拉钩职位信息,保存为csv文件,并上传到mysql数据库当中。此案例仅用于学习爬虫技术,不作商业用途。若侵权,请联系删除。
基于Python的scrapy爬虫框架实现爬取招聘网站的信息到数据库
大家好我是小菜鸡,让我们一起学习Python的网络爬虫框架-Scrapy爬虫框架的使用(一起努力,咱们顶峰相见!!!)

本资源提供了一套基于Python的Scrapy爬虫框架与Scrapy-Redis分布式爬虫的设计源码,包含61个文件,其中包括51个Python源代码文件,7个配置文件,以及1个Git忽略文件。此外,还包括1个文本文件和1个Markdown文档。...
pythonscrapy爬虫实例Python爬虫Scrapy实例

推荐文章
- 【vue-treeselect+vxe-table】数据量大的时候懒加载,数据回显,输入框绑值,末级节点不要前面的箭头等问题详解_treeselect显示加载中-程序员宅基地
- 【从0入门JVM】-01Java代码怎么运行的_代码如何在jvm中运行-程序员宅基地
- TreeViewer应用实例(ITreeContentProvider与LabelProvider的使用)-程序员宅基地
- 如何将别人Google云端硬盘中的数据进行保存_谷歌网盘怎么保存别人的资源-程序员宅基地
- java中查看数据类型_java查看数据类型-程序员宅基地
- Scrapy-redis分布式+Scrapy-redis实战-程序员宅基地
- web播放H.264/H.265,海康,大华监控摄像头RTSP流方案_海康api hls怎么取265的流-程序员宅基地
- HTML详解连载(7)-程序员宅基地
- PHP使用多线程-程序员宅基地
- 由excel一键生成json的小工具(基于python,仅支持单层嵌套)_excel转json github-程序员宅基地