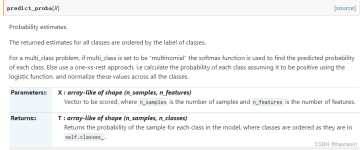
总的来说,predict返回的是一个预测的值,predict_proba返回的是对于预测为各个类别的概率。predict_proba返回的是一个n 行 k 列的数组,第 i行j列的数值是模型预测 第 i 个预测样本为某个标签的概率,并且每一行的...
”predict_proba“ 的搜索结果
我们在建模时通常根据准确性或准确性来评估其预测模型,但几乎不会问自己:“我的模型能够预测实际概率吗?但是,从商业的角度来看,准确的概率估计是非常有价值的(准确的概率估计有时甚至比好的精度更有价值)。...
predict_proba:返回一个 n 行 k 列的数组, 第 i 行 第 j 列上的数值是模型预测 第 i 个预测样本为某个标签的概率,并且每一行的概率和为1。 具体见下面示例: from sklearn.linear_model import Logistic...
发现个很有用的方法——predict_proba 今天在做数据预测的时候用到了,感觉很不错,所以记录分享一下,以后可能会经常用到。 我的理解:predict_proba不同于predict,它返回的预测值为,获得所有结果的概率。(有...
发现个很有用的方法——predict_proba 今天在做数据预测的时候用到了,感觉很不错,所以记录分享一下,以后可能会经常用到。 我的理解:predict_proba不同于predict,它返回的预测值为,获得所有结果的概率。(有...
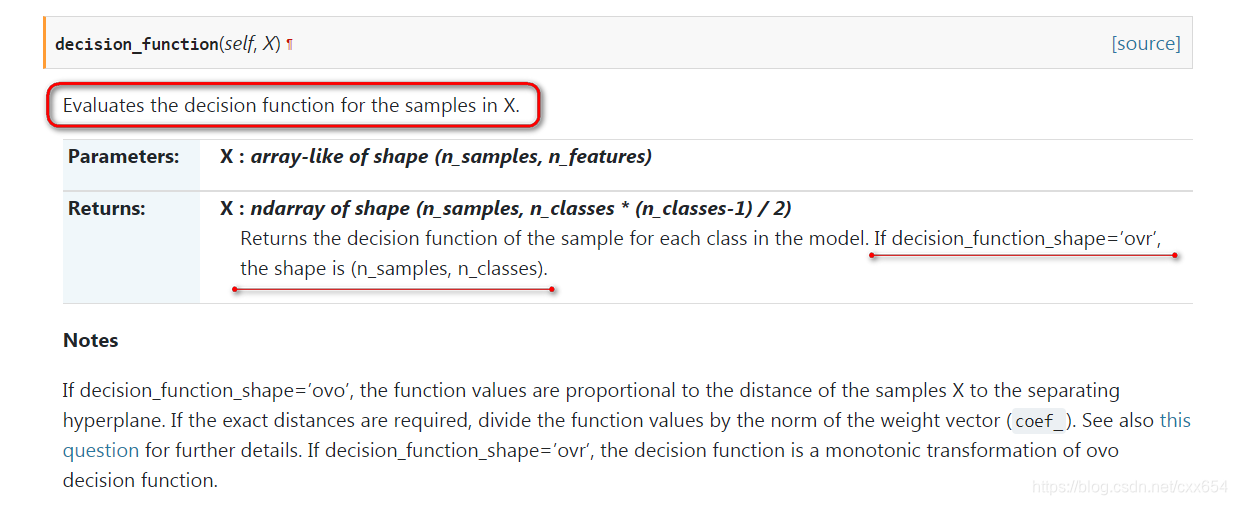
predict_proba 返回的是一个 n 行 k 列的数组,列是标签(有排序), 第 i 行 第 j 列上的数值是模型预测 第 i 个预测样本为某个标签的概率,并且每一行的概率和为1。 predict 直接返回的是预测 的标签。 具体见下面...
发现个很有用的方法——predict_proba今天在做数据预测的时候用到了,感觉很不错,所以记录分享一下,以后可能会经常用到。我的理解:predict_proba不同于predict,它返回的预测值为,获得所有结果的概率。(有多少个...
通过 sklearn 调库计算 logloss 遇到的问题解决。
@创建于:2022.04.17 @修改于:2022.04.17 ...predict_classes()、predict_proba()方法 在tf.keras.Sequential 模块下有效,在tf.keras.Model模块下无效。 1、方法介绍 predict()方法预测时,返回值是数值,表示样本
用xgboost建模预测了响应概率prob_predict xgb_model.predict_proba(x_test)返回是一个n*2的ndarray,一列是响应概率,另一列是不响应概率; 但是怎么把响应概率那一列对应到x_test的每一行形成一个完成的DataFrame...
predict_proba 返回的是一个 n 行 k 列的数组,列是标签(有排序), 第 i 行 第 j 列上的数值是模型预测 第 i 个预测样本为某个标签的概率,并且每一行的概率和为1。predict 直接返回的是预测 的标签。具体见下面示例...
在这个问题上,我引用了以下代码:>>> import sklearn>>> sklearn.__version__'0.13.1'>>> from sklearn import svm>... model = svm.SVC(probability=True)>... X = [[1,2,3], [2,3,4]]...
表示要求该分类器在训练时计算类别概率。通常情况下,分类器会输出样本属于每个类别的概率值,而不仅仅是预测的类别标签。这对于一些评估指标(如ROC曲线和AUC值)的计算是非常有用的。方法来获取样本属于每个类别的...


关于随机森林接口 predict_proba 的个人理解
发现个很有用的方法——predict_proba今天在做数据预测的时候用到了,感觉很不错,所以记录分享一下,以后可能会经常用到。我的理解:predict_proba不同于predict,它返回的预测值为,获得所有结果的概率。(有多少...
predict_proba返回的是一个n行k列的数组,第i行第j列上的数值是模型预测第i个预测样本的标签为j的概率。所以每一行的和应该等于1.举个例子>>> from sklearn.linear_model import LogisticRegression>>...
LogisticRegression.predict_proba函数究竟返回什么?在我的示例中,我得到这样的结果:[[ 4.65761066e-03 9.95342389e-01][ 9.75851270e-01 2.41487300e-02][ 9.99983374e-01 1.66258341e-05]]根据其他计算,使用S形...
成功解决AttributeError: predict_proba is not available when probability=False 目录 解决问题 解决思路 解决方法 解决问题 raise AttributeError("predict_proba is not available when " ...
上面是他们输出的结果 我们可以看出 model.predict 输出的是一个标签值,而第二个输出的是概率。我们可以看出来 两者输出的结果一样 那说明他们在深度学习中往往直接输出多类别的概率。总体而言,深度学习模型在输出...
有下面一段代码,用来预测值。import pandas as pdimport sklearnfrom sklearn import svm, model_selectiondf = pd.read_csv(args[1], encoding='shift-jis', index_col=0)y = df["label"]# 数据对应的标签X = df....
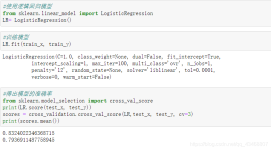
参数详解 from sklearn import linear_model linear_model.LogisticRegression(penalty='l2', dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, ...
我需要使用3倍交叉验证训练Random Forest classifier.对于每个样本,我需要在它恰好位于测试集中时检索预测概率....在我的情况下,我想使用predict_proba()方法,它返回多类方案中每个类的概率.但是,当我运行该...
当使用predscore=model.predict_proba直接计算AUC值时精度高,而保存为CSV文件精度损失,所以造成有误差。之后想要再次计算AUC直接加载保存的模型,再加载数据,这样计算的AUC与之前一致。我是使用model.predict_...
推荐文章
- Response使用 application/octet-stream 响应到前端_application/octet-stream;charset=utf-8-程序员宅基地
- 利用MultipartFile实现文件上传_实现了multipartfile file上传文件时要选择一个栏目,传给后端一个栏目id,如何实现-程序员宅基地
- muduo之Singleton_muduo singleton-程序员宅基地
- html5 动态存储 localStorage.name 和localStorage.setItem()的差别_localstorage.setitem('aa')和localstorage.aa一样吗-程序员宅基地
- 02.loadrunner之http接口脚本编写_http脚本-程序员宅基地
- The server time zone value ‘�й���ʱ��‘ is unrecognized or represents more than one time zone.-程序员宅基地
- 如何打造企业短视频账号的人设?_做的比较有人格化的公司短视频账号-程序员宅基地
- 一个会做饭的程序员如何每天给女朋友带不同的便当?-程序员宅基地
- PendingIntent重定向:一种针对安卓系统和流行App的通用提权方法——BlackHat EU 2021议题详解 (下)_getrunningservicecontrolpanel-程序员宅基地
- python 之 面向对象(反射、__str__、__del__)-程序员宅基地