Pandas库主要针对Series和DataFrame两种数据结构进行操作,一般与Numpy同时导入:一、Series1、Series的定义与使用Series 是一个带有名称和索引(显性)的一维数组Series 中包含的数据类型可以是整数、浮点、字符串、...
”pandas将df赋值到另一个df“ 的搜索结果
1.读取.csv文件df2= pd.read_csv(‘beijingsale.csv‘, encoding=‘gb2312‘,index_col=‘id‘,sep=‘\t‘,header=None)参数解析见:https://www.cnblogs.com/datablog/p/6127000.htmlindex_col用于指定用作行索引的...
在数据处理过程中,经常会出现对某列批量做某些操作,比如dataframe df要对列名为“values”做大于等于30设置为1,小于30设置为0操作,可以这样使用dataframe...以上这篇对pandas将dataframe中某列按照条件赋值的实例讲
Pandas库主要针对Series和DataFrame两种数据结构进行操作,一般与Numpy同时导入:一、Series1、Series的定义与使用Series 是一个带有名称和索引(显性)的一维数组Series 中包含的数据类型可以是整数、浮点、字符串、...
1 dataframe和series操作1.1 构造dataframe1) 空dataframe通过columns,index参数指定dataframe的行索引、列名。df1 = pd.DataFrame(columns=['c1', 'c2'], index=['ind1', 'ind2'])2) ...可以通过index=[]参数设置df...
更新应该工作。尝试这个:df1 = df1.set_index('SubscriberKey')df1Output:Inst A1 A2 A3 A4SubscriberKey'abc' 1 0 0 0 0'bcd' 2 0 0 0 0'cde' 1 0 0 0 0'def' ...
import pandas as pd import numpy as np data = {'a': [4, 6, 5, 7, 8], 'b': ['w', 't', 'y', 'x', 'z'], 'c': [1, 0, 6, -5, 3], 'd': [3, 4, 7, 10, 8], } df = pd.DataFrame(data, index=['one', 'two', '...
在Python中使用Pandas来处理数据,经常会需要根据...1、首选引入pandas库import pandas as pd2、定义一个简单的列表来作为演示操作。a=[['js',100,'cz',200],['zj',120,'xs',300],['zj',150,'xs',200],['js',200,'...
示例代碼df1 = pd.DataFrame({'terms' : ['term1','term2'],'code1': ['1234x', '4321y'],'code2': ['2345x','5432y'],'code3': ['3456x','6543y']})df1 = df1[['terms'] + df1.columns[:-1].tolist()]df2 = pd....
python如果读取一个excel文件,将指定的一列存放在新的excel中pandas可以比较的实现。import pandas as pddf=pd.read_excel(r'e:/aaaaa.xlsx',usecols=[2])df.to_excel(r'e:/aaaaa1.xlsx',index=False)请问在Pandas...
一个有col标签,另一个没有。我将标签添加到需要它们的df,然后连接两个dfs。连接工作正常,但我添加的标签看起来像个别列表或其他东西。我无法弄清楚python正在做什么,特别是当你打印标签和df时,它看起来都很好。...
对数据进行切片时,而且后期还需要对这些数据进行修改,我们因该利用.copy()对切片后的数据进行备份

1,pandas操作主要有对指定位置的赋值,如上一篇中的数据选择一样,根据loc,iloc,ix选择指定位置,直接赋值2,插入,insert方法,插入行和列3,添加4,删除 drop方法5,弹出 pop方法In [1]:import pandas as pd...
df1['A']=df2['flag'] 是pandas数据处理常用的一种列赋值的方法。 今天在进行列赋值时,发现处理后的结果不符合预期。查阅了一些资料,df1['A']=df2['flag']不是直接整列赋值的,而是根据索引index的映射来进行赋值...
开始是参考其他文章的做法,但情况不一样,那篇文章并没有分组赋值,由于不涉及分组,所以对dataframe赋值时是一整列进行赋值的,而这是pandas官方建议的赋值方法之一 import pandas as pd import numpy as np ...
df[‘x2’] = np.where(df[‘name’] == ‘’, 0, df[‘amount’]) df[‘x3’] = df[‘amount’].where(df[‘name’] != ‘’, 0) 2、通过apply+lambda方式的条件函数运算,进行条件表示的时候要标记 loc! cellparam...
常见库简介xlrdxlrd是一个从Excel文件读取数据和格式化信息的库,支持.xls以及.xlsx文件。http://xlrd.readthedocs.io/en/latest/1、xlrd支持.xls,.xlsx文件的读2、通过设置on_demand变量使open_workbook()函数只...
有时候我们需要对表格里面的数据进行一些预处理的操作,这时候就...import pandas as pd dates = np.arange(20200101,20200107) df1 = pd.DataFrame(np.arange(24).reshape(6,4),index=dates,columns=['a','b','c',

为了更好的理解这些基本操作,我们将读取一个真实的股票数据。 import pandas as pd # 读取文件 data = pd.read_csv("./data/stock_day.csv") # 删除一些列,让数据更简单些,再去做后面的操作
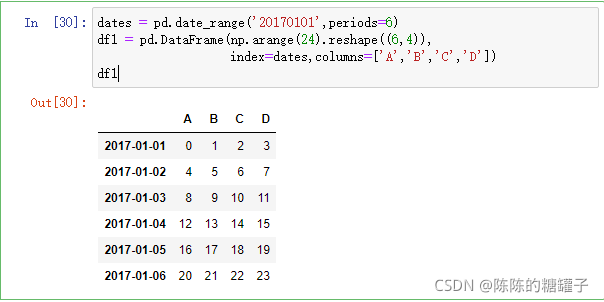
import pandas as pd import numpy as np dates = np.arange(20170101,20170107) #取值 df1 = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['A','B','C','D']) df1 A B C D ...
df_test = pd.DataFrame(np.arange(40).reshape(10, 4), columns=['a', 'b', 'c', 'd'], index=np.arange(10)) df_test.at[[1, 3, 5, 7], 'a'] = 0 df_test 结果如图: 当然,还可以使用这个方法 ...
在使用Pandas进行数据处理过程当中,有时候需要将数据的某一列都赋值为某一个列表的形式。但是如果列的元素个数与列表的元素个数相同时赋值,会导致列表中的每一个元素对应到了列的一个表格中(详情见下)。本文即...
pandas根据条件赋值:常用条件,多条件并行、是否相等、字符串是否包含、是否为nan等。
使用 pandas 将一列的值赋值给一个新的 DataFrame 的方法是: import pandas as pd # 创建一个示例 DataFrame df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}) # 将列 'A' 的值赋值给新的 ...
pandas 指定单元格赋值
import pandas as pd import numpy as np df = pd.DataFrame(data = np.random.randint(0,150,size = [10,3]),# 计算机科⽬的考试成绩 index = list('ABCDEFGHIJ'),# ⾏标签,⽤户 columns=['Python','Tensorflow...
df[df[‘SUCC_RATE_ANOMALY’]==1]
推荐文章
- 联邦学习综述-程序员宅基地
- virtuoso--工艺库答疑_tsmc mac-程序员宅基地
- C++中的exit函数_c++ exit-程序员宅基地
- Java入门基础知识点总结(详细篇)_java基础知识重点总结-程序员宅基地
- 【SpringBoot】82、SpringBoot集成Quartz实现动态管理定时任务_springboot集成quratz 实现动态任务调度-程序员宅基地
- testNG常见测试方法_idea_java_testng 测试-程序员宅基地
- Debian11系统安装-程序员宅基地
- Centos7重置root用户密码_centos7更改root密码-程序员宅基地
- STM32常用协议之IIC协议详解_正点原子stm32 iic-程序员宅基地
- 【视频播放】Jplayer视频播放器的使用_jplayer 播放amr-程序员宅基地