基于java爬虫的就业大数据系统设计与实现 1 摘 要 1 1.1课题选题背景 4 1.2课题研究的意义 4 2.1功能需求分析 4 2.2系统性能分析 5 3.1系统工作流程图 5 3.2数据结构设计 7 3.3系统各功能流程图 7 (1) 主模块功能...
”java爬虫“ 的搜索结果
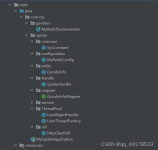
dddjava爬虫测试版体育赛事爬虫 加 体育比赛文字直播主要用的 springBoot 和 netty爬虫位置/src/main/java/com/example/ddd/crawler
基于 webmagic 的 Java 爬虫应用
给予SpringMVC的java爬虫Demo.zip
JAVA 爬虫技术爬取网页内指定链接和图片。JAVA 爬虫技术爬取网页内指定链接和图片。JAVA 爬虫技术爬取网页内指定链接和图片。JAVA 爬虫技术爬取网页内指定链接和图片。
java爬虫 爬取一千张美女图片并下载
Nutch:一个开源的Java爬虫框架,可用于爬取大规模的网页并建立搜索引擎。Crawler4j:一个开源的Java爬虫框架,可用于爬取网页并提取数据。Jsoup:一个开源的Java HTML解析器,可用于从网页中提取数据。WebMagic:一...

java爬虫 可以尝试一下java爬虫,爬取豆瓣电影榜单。用上正则表达式,结合一下gui 最初版本 import java.net.*; import java.util.*; import java.nio.charset.*; import java.io.*; import java.math.*; public ...
爬虫搜索,简单的搜索引擎,java爬虫,搜索引擎例子,爬虫demo,java实现互联网内容抓取,搜索引擎大揭密.java爬虫程序。web搜索。爬虫程序。sigar搜索,定时搜索互联网内容信息。
Java爬虫+自定义任务可解析cron

java爬虫抓取网页内容,下载网站图片。抓取整个网站的图片,获取网页完整内容
不借助第三方工具实现的java爬虫系统,采用广度优先策略实现,可设置爬取深度
学习使用webmagic 进行静态页面抓取,springboot + webmagic demo项目,进行学习使用 。java 使用webmagic爬取网页数据
基于Spring Boot的简单Java爬虫
HTTP是的缩写,翻译为超文本传输协议,它是基于TCP协议之上的一种请求-响应协议。HTTP请求格式是固定的,由HTTPHeader和HTTPBody两部分构成。
java爬取图片的实例代码(GetEveryPictures.java)+java清除空文件夹的代码(ClearEmptyDirs.java)。
一种基于JAVA爬虫的网络票务查询系统.pdf
一个简单的百度贴吧java爬虫,可以爬取用户内容,用户名和楼层 一个简单的百度贴吧java爬虫,可以爬取用户内容,用户名和楼层
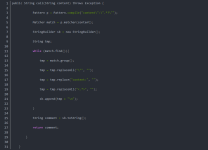
最开始采用的HttpClient获取页面+Jsoup分析页面,但是获取不到想要的页面内容,发现自己想要的数据是js生成的,HttpClient加了头和Cookie还是获取不到,最后采用的htmlunit获取页面就可以了。 WebClient webClient=...
WebMagic的架构设计参照了Scrapy,而实现则应用了HttpClient、Jsoup等Java成熟的工具。 WebMagic由四个组件(Downloader、PageProcessor、Scheduler、Pipeline)构成: Downloader : 下载器 PageProcessor: 页面解析...
Java爬虫详细完整源码实例
标签: Java
Java爬虫,信息抓取的实现 详细完整源码实例打包给大家,需要的可以下载下载学习!打包给大家,需要的可以下载下载学习!
Java爬虫信息抓取共14页.pdf.zip
毕业设计美食推荐Java爬虫

强力 Java 爬虫,列表分页、详细页分页、ajax、微内核高扩展、配置灵活
推荐文章
- 算法训练 K好数 (详解:题目理解+解题思路)-程序员宅基地
- vue element-ui 常见的新增、编辑、查看公用同一个页面_elementui 新增 编辑 共用-程序员宅基地
- 多元分类预测 | Matlab 深度置信网络(DBN)分类预测_dbn训练过程准确率显示 matlab-程序员宅基地
- 自媒体矩阵运营计划书:成功策划秘籍揭秘_自媒体矩阵运营商业计划书-程序员宅基地
- lisp 正则表达式示例-程序员宅基地
- ThinkPHP学习(四)volist标签高级应用之多重嵌套循环、隔行变色_thinkphp volist 单双行-程序员宅基地
- C语言多线程编程之一_c语言 线程 传参-程序员宅基地
- linux服务器搭建实验4报告,LINUX实验四报告-程序员宅基地
- 探索Node.js编程的新境界:BookNode.js-程序员宅基地
- feign实现远程调用_feign远程调用实现-程序员宅基地