
”hive相关“ 的搜索结果
把所有数据分析相关的日志数据存储至ClickHouse这个优秀的数据仓库之中,当前日数据量达到了300亿。需求:按条件筛选Hive表中的数据同步到ClickHouse中方法一: 按照ClickHouse 官方文档提供的方法,在ClickHouse 中...
Hive调优总结:1. 改硬件.2. 开启或者增大某些设置(配置). 负载均衡, 严格模式(禁用低效SQL), 动态分区数...3. 关闭或者减小某些设置(配置). 严格模式(动态分区), 推测执行...4. 减少IO传输. Input(输入)/Output(输出...
在cdh6.3.2已经做好hbase和hive相关配置,这里不阐述。要创建上述的表结构,你需要先在HBase中创建相应的表,然后在Hive中创建一个EXTERNAL TABLE来映射到这个HBase表。

SparkSQL与Hive交互
4、Apache Hive是一款分布式SQL计算的工具,其主要功是:将SQL语句 翻译成MapReduce程序运行,可以用IntelliJ IDEA,PyCharm等进行数据库的编写与导入更加简洁。安装好hadoop环境之后,可以执行hdfs相关的shel命令对...
主要介绍大数据数据仓库的理论知识,hadoop和hive相关知识
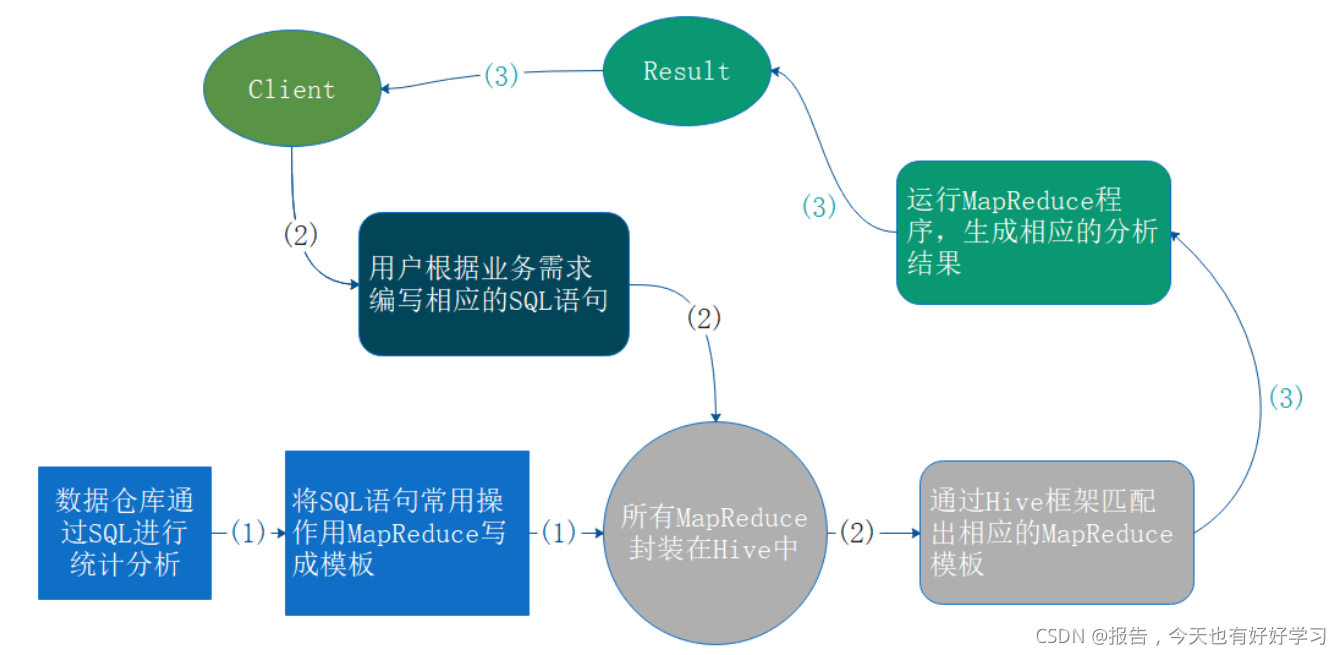

Hive是一个SQL转化转化工具,将SQL的计算转为MapReduce的计算,让开发人员更加方便进行大数据开发。如果使用多个客户端进行访问,就需要有多个Hiveserver服务,此时会启动多个Metastore。2、不需要单独配置metastore ...
什么是Hive?Hive是基于Hadoop的一个数据仓库工具,用于进行数据提取、转换和加载(ETL)。它可以将结构化的数据文件映射为一张数据库表,并提供类似SQL的查询语言(HiveQL),使用户能够使用SQL语句来查询、汇总和...
Hive 简介Hive 是一个基于 hadoop 的开源数据仓库工具,用于存储和处理海量结构化数据。它把海量数据存储于 hadoop 文件系统,而不是数据库,但提供了一套类数据库的数据存储和处理机制,并采用 HQL (类 SQL )语言对...
idea中使用的apache hive的cdh版本的所有驱动jar zookeeper-jute-3.5.9.jar zookeeper-3.5.9.jar hive-jdbc-1.1.0-cdh5.12.1-standalone.jar curator-framework-4.2.0.jar ...高可用需要添加curator相关jar
Flink与hive的介绍及简单示例
相关技术包括离线处理,实时处理,OLAP等,如hadoop、spark、flink、hive、hbase、oozie...以及大数据项目,如用户画像、数据仓库等 Hadoop是一个由Apache基金会所开发的分布式系统基础架构。 Spark是基于内存计算...
相关软件版本如下: 备注:64位 软件 版本 Linux Ubuntu 18 Hadoop 2.7.7 MySQL 5.7 MySQL驱动 5.1.47 Hive 2.3.7 DBeaver 7.1.0 检查Hadoop环境 (1)查看Hadoop版本号,命令如下: hadoop ...
Hive的安装部署
【Hive下篇:超干货文章带你深入了解Hive!hive分区分桶!学习hive原理!】表的分区,分桶,数据的读取和写入
在网上搜索了好些文章,基本上都是说hive-jdbc的版本和服务器上的hive版本不一致所致,通过断点跟踪,确实是由于服务器端返回这条错误信息,先后更换了好几个hive-jdbc版本,都无法解决。业务上需要在一个SpringBoot...

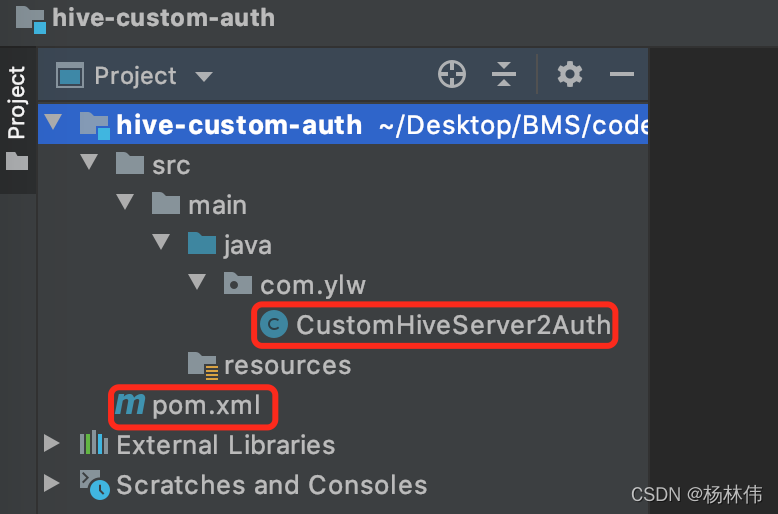
hive-set设置总结
标签: hive
Hive相关的配置属性总结set hive.cli.print.current.db=true;在cli hive提示符后显示当前数据库。set hive.cli.print.header=true;显示表头。select时会显示对应字段。set hive.mapred.mode=strict;防止笛卡儿积的...
hive编程手册,从入门到精通
标签: hive
hive从初级到高级的编程,讲解详细,有项目实战案例。包含了hive所有的知识点,以及实战应用到的所有相关知识。
浅谈Hive程序相关规范
标签: hive

由于Hive是一个基于Hadoop分布式文件系统的数据仓库架构,主要运行在 Hadoop分布式环境下,因此,需要在文件hive-env.sh中指定Hadoop相关配置文件的路径,用于Hive访问HDFS(读取fs.defaultFS属性值)和 MapReduce...
本文是对 flink 1.14 官网中读写 hive 部分内容的翻译整理。

hive自定义udf函数
推荐文章
- 联邦学习综述-程序员宅基地
- virtuoso--工艺库答疑_tsmc mac-程序员宅基地
- C++中的exit函数_c++ exit-程序员宅基地
- Java入门基础知识点总结(详细篇)_java基础知识重点总结-程序员宅基地
- 【SpringBoot】82、SpringBoot集成Quartz实现动态管理定时任务_springboot集成quratz 实现动态任务调度-程序员宅基地
- testNG常见测试方法_idea_java_testng 测试-程序员宅基地
- Debian11系统安装-程序员宅基地
- Centos7重置root用户密码_centos7更改root密码-程序员宅基地
- STM32常用协议之IIC协议详解_正点原子stm32 iic-程序员宅基地
- 【视频播放】Jplayer视频播放器的使用_jplayer 播放amr-程序员宅基地