Hive 是将 SQL 转为 MapReduce。SparkSQL 可以理解成是将 SQL 解析成:“RDD + 优化” 再执行在学习Spark SQL前,需要了解数据分类。
”Spark基础“ 的搜索结果
Spark On YARN模式的搭建比较简单,仅需要在YARN集群上的一个节点上安装Spark即可,该节点可作为提交Spark应用程序到YARN集群的客户端。2)Spark中引入的RDD是分布在多个计算节点上的只读对象集合,这些集合是弹性的...
主要介绍Spark RDD的相关入门知识以及编程模型,附带介绍了Spark作业调度等一些底层工作机制的实现原理
Spark是一种快速、通用、可...目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkCore、SparkSQL、Spark Streaming、GraphX、MLib、SparkR等子项目,Spark是基于内存计算的大数据并行计算框架。
spark基础知识整理
标签: spark
spark基础知识思维导图整理,包括SparkCore和SparkSQL

在我博客中的三个基础章节 第 1 章 Spark 概述 第 2 章 Spark 第 3 章 案例 实操 从Spark入门到Spark的第一个基础案例
spark基础知识,个人分享,大家一起学习

本项目是一个基于Java和Scala语言开发的Spark基础教程配套源码,包含55个文件,主要文件类型包括Java源代码、Scala源代码、XML配置文件、日志文件、Git忽略文件、LICENSE文件和Idea配置文件。系统设计旨在为学习...
spark解决的问题:海量数据的计算,可以进行离线批处理以及实时流计算spark模块:sparkcore、SQL、流计算(SparkStreaming)、图计算(Graphx)、机器学习(MLib)spark特点:速度快、使用简单、通用性强、多模式...
spark基础知识,包含了RDD介绍,本地调试,spark-shell 交互式,spark-submit 提交

1.spark是什么 定义:Apache Spark是用于大规模数据(large-scala data)处理的统一(unifled)分析引擎 特点:对任意数据类型的数据进行自定义计算 Spark可以计算:结构化、半结构化、非结构化等各种类型的数据结构...

Spark基础环境搭建

本文档整理了spark所有的基本知识,带你入门spark,让你可以更详细的去了解spark,也为日后深入学习,打下良好的基础。Spark是一个通用引擎,可用它来完成各种各样的运算,包括 SQL 查询、文本处理、机器学习等,而...
星火基础 Spark基础知识I-Spark简介
spark python java scala

用Python火花Apache Spark ... 笔记本电脑RDD和基础数据框使用Python 3和Jupyter Notebook设置Apache Spark 与大多数Python库不同,让PySpark开始正常工作并不像pip install ...和import ...那样简单。我们大多数基于P
1. 快:与 Hadoop的 MapReduce相比,spark基于内存的运算要快100倍以上,基于硬盘的运算也 2. 易用:spark支持Java、 Pyth
如何在win上边运行scala程序以及在Linux上部署运行spark,如何在hdfs系统上运行scala程序.
《Spark编程基础及项目实践》课后习题及答案7.pdf《Spark编程基础及项目实践》课后习题及答案7.pdf《Spark编程基础及项目实践》课后习题及答案7.pdf《Spark编程基础及项目实践》课后习题及答案7.pdf《Spark编程基础...
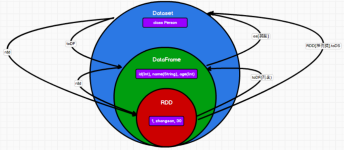
Spark的核心思想是通过一种可并行操作且有容错机制的弹性分布式数据集RDD(Resilient Distributed Dataset)以减少磁盘以及网络IO开销。RDD是一个能并行的数据结构,可以让用户显式地将数据存储到磁盘或内存中,并能...
有如下四个csv文件,列属性如下: #上传到本地 #加载数据 val customers = sc.textFile("file:///data/customers.csv").map(x => x.split(";").map(y => y.replace("\"", ""))) val products = sc.textFile(...
spark基础解析
scala与spark基础
标签: spark
本资源收集了scala与大数据spark的基础的学习笔记,有兴趣的同学可以下载学习
推荐文章
- 【解决报错】java.sql.SQLException: Access denied for user 'root'@'localhost' (using password: YES)-程序员宅基地
- echart y轴显示小数或整数_echarts y轴显示16位小数-程序员宅基地
- Android客户端和Internet的交互_android与internet-程序员宅基地
- linux新建分区步骤_linux创建基本分区的步骤-程序员宅基地
- 信号处理-小波变换4-DWT离散小波变换概念及离散小波变换实现滤波_dwt离散小波变换进行滤波-程序员宅基地
- Ubuntu 10.10中成功安装ns-allinone-2.34_进入/home/ubuntu1/ns-allinone-2.34目录cd /home/ubuntu1-程序员宅基地
- 使用AES算法对字符串进行加解密_java 判断aes加密 与否-程序员宅基地
- DFS深度优先搜索(前序、中序、后序遍历)非递归标准模板_深度优先搜索 无递归-程序员宅基地
- 程序员面试字节跳动,被怼了~_字节跳动java什么技术站-程序员宅基地
- 嵌入式软考备考(五)安全性基础知识-程序员宅基地