对于使用Pytorch 的小伙伴,可能在复现模型时候出现了以下报错,这个错误是因为出现了 inplace operation 造成的,以下尝试了几种解决方案,方案4⃣️/5⃣️ 可行,希望对有同样问题的小伙伴有帮助!...
”ReluBackward“ 的搜索结果
4.PyTorch损失优化 4.1.权值初始化 4.1.1.梯度消失与爆炸 对于一个含有多层隐藏层的神经网络来说,当梯度消失发生时,接近于输出层的隐藏层由于其梯度相对正常,所以权值更新时也就相对正常,但是当越靠近输入层...
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [19, 175, 32]], which is output 0 of ReluBackward0, is at version ...
在这个错误信息中,被修改的变量是一个形状为 [2, 1024, 18, 8, 16] 的 torch.cuda.FloatTensor,它是 ReluBackward0 的输出 0,版本号为 1,但是期望版本号为 0。 为了找到导致这个错误的操作,可以使用 PyTorch ...
这个错误是由于你在计算梯度时使用了 inplace 操作,导致了梯度计算所需的变量被修改。为了解决这个问题,你可以尝试启用 PyTorch 的异常检测功能。在执行前向计算之前,可以使用 `torch.autograd.set_detect_...
这个错误是由于在反向传播过程中,需要计算梯度的变量被in-place操作修改了。具体来说,是因为您在计算反向传播时,使用了in-place操作(如`tensor[index] = value`)而导致的。在 PyTorch 中,这种操作会直接修改...
这个错误通常表示你在一个inplace操作中修改了一个需要梯度计算的变量。建议尝试启用PyTorch的autograd anomaly detection功能,以找到导致错误的操作。可以通过在代码中添加以下代码启用该功能: ...
错误2:Function ‘LogSoftmaxBackward’ returned nan values in its 0th output.错误3:Function ‘MulBackward0’ returned nan values in its 0th output出现这种情况,大家可以尝试换一个数据集,我折腾了两天...
1.RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [128, 128, 1]], which is output 0 of ReluBackward0, is at ...
由于网络里连用两个nn.ReLU(inplace = True),由于是inplace操作,所以不产生中间变量,导致backward的时候,缺失这部分需要的变量,测试了将 inplace = False,不行,pass。通过nvidia-smi查看显存占用,通过fuser ...

RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation [torch.cuda.FloatTensor [4, 64, 128, 128]], which is output 0 of ReluBackward0, is at ...
解决RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [2, 512, 32, 32]], which is output 0 of ReluBackward0, is at ...
小虎最近在写一个分割模型的代码,debug的时候不仅慢而且还出现了这个报错。
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation。pytorch梯度回传导致的错误。
在DistributedDataParallel加上broadcast_buffers=False 问题解决。分布式训练时出现如下报错。
detach方法的实例说明
1 问题描述 今天在写作DeepLabV3+的代码时,遇到了一个问题, 程序报错: RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda....
pytorch 的 inplace 的问题背景:relu等激活函数的inplace:“+=”操作的默认inplace:报错形式最后说两句 背景: 最近将一个模型训练代码从caffe平台移植到pytorch平台过程中遇到了一个诡异的inplace坑,特别记录...

RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [1, 64, 92, 122]], which is output 0 of LeakyReluBackward0, is at ...

RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [2, 256, 20, 20]], which is output 0 of struct torch::autograd::...
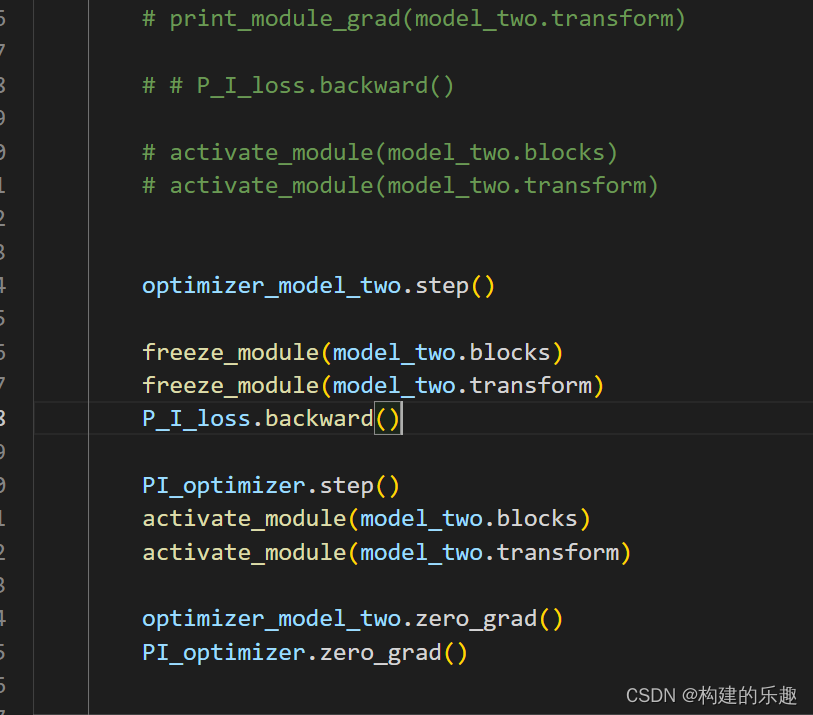

编写代码,pytorch出现了这个问题: RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [1, 64, 92, 122]], which is ...
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [1, 32, 22, 256, 256]], which is output 0 of ReluBackward1, is at ...
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.FloatTensor [128, 2048, 7, 7]], which is output 0 of ReluBackward0, is at version 3...
推荐文章
- RecyclerView实现吸顶效果项目实战(三):布局管理器LayoutManager-程序员宅基地
- 【智能排班系统】基于AOP和自定义注解实现接口幂等性-程序员宅基地
- SpringBoot整合Swagger2 详解_springboot swagger2 开关-程序员宅基地
- spring boot 项目报错 java.sql.SQLException: The server time zone value '�й���ʱ��' is unrecognized_springboot项目里面报错 the server time zone value ' й-程序员宅基地
- 最全Android Kotlin 学习路线(Kotlin 从入门、进阶到实战)_kotlin学习-程序员宅基地
- 【前端素材】推荐优质新鲜绿色蔬菜商城网站设计Harmic平台模板(附源码)-程序员宅基地
- elementui表格添加fixed之后样式异常_element table fixed 样式异常-程序员宅基地
- C语言中的 #include <stdio.h>是什么?_include <stdio.h>含义-程序员宅基地
- (转载)linux命令之五十三telnet命令_telnet linux reboot-程序员宅基地
- 局部色调映射(Local Tone Mapping)-程序员宅基地