Java实现的保存自己的文章到本地,需要本地有java环境,代码可直接运行,有说明文档
”Java爬虫“ 的搜索结果
Java实现的保存自己的文章到本地,需要本地有java环境,代码可直接运行,有说明文档
Java实现的保存自己的文章到本地,需要本地有java环境,代码可直接运行,有说明文档
Java实现的保存自己的文章到本地,需要本地有java环境,代码可直接运行,有说明文档
Java实现的保存自己的文章到本地,需要本地有java环境,代码可直接运行,有说明文档
基于java的开发源码-WebMagic (Java爬虫框架).zip
JAVA爬虫批量下载网页文件
标签: 网页爬虫
该爬虫代码可将一个多页面含有多条文件的下载地址截取到,然后将下载地址放到linux系统里在控制台输入一条命令就可以进行批量下载(还可以直接调用浏览器的接口直接下载,这个可以自行修改),代码有注释具体目的...
爬soho网的java爬虫,数据提取,MYSQL数据库导入

爬虫:一个基于微博用户数据的Java爬虫项目.zip
webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持自动重试、自定义UA/cookie等功能。
一个简单的百度贴吧java爬虫,可以爬取用户内容,用户名和楼层 一个简单的百度贴吧java爬虫,可以爬取用户内容,用户名和楼层
JAVA爬虫项目实战源码+实战案例+源码分享+案例库
Java实现的保存自己的文章到本地,需要本地有java环境,代码可直接运行,有说明文档
这是一个Java的爬虫项目,自己是用来爬去网站上的小说内容的。
使用ide工具编写爬虫技术,可以查出网站上的数据。
搜网络爬虫框架主要针对电子商务网站进行数据爬取,分析,存储,索引
最近公司叫我这个实习生去写一个爬虫,将爬取到的数据存到数据库中,再通过前端界面渲染出来,这可是一个大难题啊,我从来没写过爬虫,最近学了一下,写了一个爬虫实例,并将其存到了数据库中,现在分享给大家。...
基于 webmagic 的 Java 爬虫应用.zip
这里是【Java精品资源】java爬虫项目实战源码,希望该资源能对大家有所帮助哈!
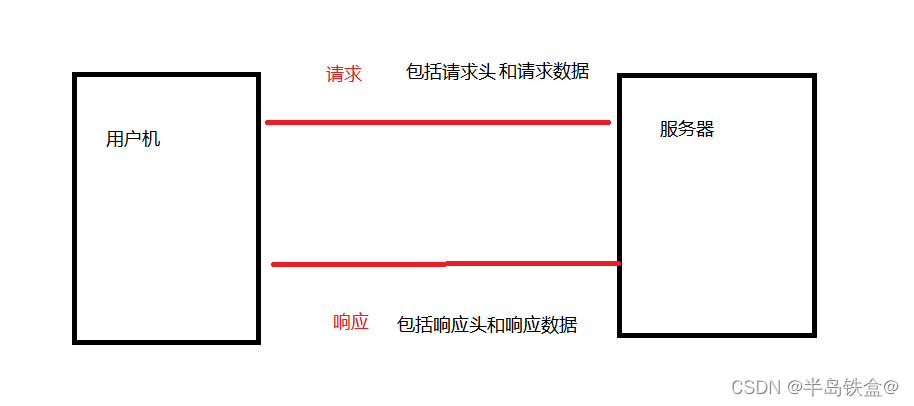
爬虫(Web crawler)是一种自动化程序,用于浏览互联网并收集网页数据。它可以按照预定的规则自动访问网页、提取数据,并将数据存储到本地或其他目标位置。爬虫通常用于搜索引擎、数据挖掘、信息收集、监测等应用。...
Java爬虫,信息抓取的实现 详细完整源码实例打包给大家,需要的可以下载下载学习!打包给大家,需要的可以下载下载学习!

java实现的爬虫,可以爬取亚马逊的衣服图片和其他相关资料,导入后可以直接运行。
【Java毕业设计】毕业设计美食推荐Java爬虫
java爬虫项目实战源码 爬虫源码下载 赠送源码.zip
Java爬虫批量爬取图片
标签: java
因为我是Java方向的,所以我就使用Java来写这个小爬虫程序了。 目标网址:妹子图 使用技术:Java基础知识、HttpClient 4.x 、Jsoup 爬取目标:获取几张图片。 爬取思路 对于这种图片的获取,...
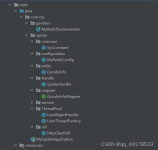
dddjava爬虫测试版体育赛事爬虫 加 体育比赛文字直播主要用的 springBoot 和 netty爬虫位置/src/main/java/com/example/ddd/crawler
推荐文章
- C++实现线性表的顺序存储结构_c++使用顺序存储表示方法创建线性表-程序员宅基地
- 重装protobuf报错undefined symbol: _ZNK6google8protobuf7Message11GetTypeNameB5cxx11Ev-程序员宅基地
- 【校招VIP】java语言考点之synchronized和volatile-程序员宅基地
- 互联网平台经济模式逐渐形成,许多新的创新型企业涌现出来,将会影响到社会的治理结构以及公共政策走向-程序员宅基地
- ethereum/EIPs-161 State trie clearing-程序员宅基地
- 2003与2007导出_导出2003-程序员宅基地
- 线性代数知识汇总_线性代数知识点总结-程序员宅基地
- oracle分区索引包含,分区表建LOCAL索引时是否一定包含分区键值-程序员宅基地
- CNN: TensorFlow 1.14.0 更新_tensorboard 1.14.0 对应的tensflow-程序员宅基地
- OTA系统包的制作和测试方法_ota升级测试用例-程序员宅基地