JAVA爬虫项目源代码
标签: 爬虫 JAVA
此资源为爬虫项目,使用JAVA,采用多线程编程和队列。基于HttpCliet、Jsoup、FastJsonjar包实现。
标签: 爬虫 JAVA
此资源为爬虫项目,使用JAVA,采用多线程编程和队列。基于HttpCliet、Jsoup、FastJsonjar包实现。

爬虫简介安装及配置

这里写自定义目录标题欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、...


一、什么是爬虫 爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。 百度的网络爬虫就叫做BaiduSpider 二、什么是搜索引擎 搜索引擎:核心模块一般包括爬虫、索引、检索和排序等,同时...
https://spidertools.cn/#/ 爬虫工具库 各种格式化 参数提取 加密解密 爬虫分享。http://tool.chinaz.com/tools/unicode.aspx 站长工具编码解码合集。http://web.chacuo.net/netproxycheck 代理服务器连接...
上七月算法 Python爬虫班 第一课示例代码
爬虫 001 robots.txt 协议 002 了解爬虫 003 常用的re模块的正则匹配的表达式 004 reuqests请求 005 请求和响应 006 Beautifulsoup 007 牛逼的requests-html 008 request-html-render 009 解析语法 010 xpath解析 ...
在开始制作爬虫前,我们应该做好前期准备工作,找到要爬的网站,然后查看它的源代码我们这次爬豆瓣美女网站,网址为:用到的工具:pycharm,这是它的图标...博文来自:zhang740000的博客Python新手写出漂亮的爬虫代码...
这篇文章主要与大家分享一下自己在python爬虫方面的收获与见解。 python爬虫是大家最为熟悉的一种python应用途径,由于python具有丰富的第三方开发库,所以它可以开展很多工作:比如 web开发(django)、应用程序...
导读:此文是一篇爬虫网络论文范文,为你的毕业论文提供有价值的参考。(1张家口学院网络信息中心,河北张家口075000;2张家口学院理学系,河北张家口075000)[摘 要]网络爬虫是搜索引擎和网站常用的搜索技术,它在为用户...
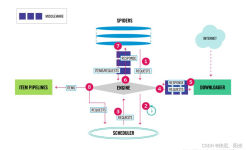
分布式爬虫则是将多台主机组合起来,共同完成一个爬取任务,这将大大提高爬取的效率。 一、分布式爬虫架构 在了解分布式爬虫架构之前,首先回顾一下Scrapy的架构,如下图所示。 Scrapy单机爬虫中有一个本地爬取...
爬虫爬数据有几个雷区:一是只能爬取公开数据,二是不能对目标业务和网站造成影响,三是目标网站的全部或部分内容没有使用反爬措施。
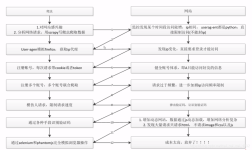
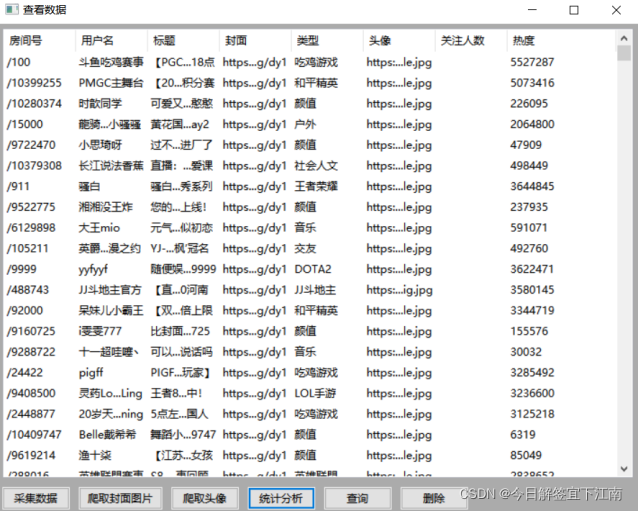
python爬虫_基本数据类型python爬虫_函数的使用python爬虫_requests的使用python爬虫_selenuim可视化质量分python爬虫_django+vue3可视化csdn用户质量分python爬虫_正则表达式获取天气预报并用echarts折线图显示...
对现在所有的主流平台爬取是没任何问题!
爬虫

3. 侵犯隐私:爬虫可能会爬取用户的个人信息或隐私信息,如聊天记录、搜索历史记录等,如果未经用户同意就将这些信息公开或出售,可能构成侵犯隐私罪。1. 侵犯版权:爬虫可能会爬取版权受保护的信息,如音乐、电影、...

爬虫按照系统结构和实现技术,大致可以分为以下几种类型:通用网络爬虫(General Purpose Web Crawler)、聚焦网络爬虫(Focused Web Crawler)、增量式网络爬虫(Incremental Web Crawler)、深层网络爬虫(Deep ...