(4) 李航《统计学习方法》基于Python实现——朴素贝叶斯_统计学习方法李航朴素贝叶斯法例题python实现-程序员宅基地
技术标签: python 机器学习 贝叶斯 统计学习方法 Python
1:高斯模型下的朴素贝叶斯
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
import math
# 特征假设是高斯分布
# data
def create_data():
iris = load_iris()
df = pd.DataFrame(iris.data,columns = iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
data = np.array(df.iloc[:100,:])
return data[:,:-1],data[:,-1]
X,y = create_data()
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3)
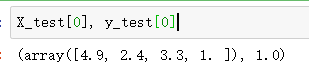
X_test[0], y_test[0]
class NaiveBayes:
def __init__(self):
self.model = None
# 数学期望
# @staticmethod
def mean(X):
return sum(X) / float(len(X))
# 标准差(方差)
def stdev(self, X):
avg = self.mean(X)
return math.sqrt(sum([pow(x-avg, 2) for x in X]) / float(len(X)))
# 概率密度函数
def gaussian_probability(self, x, mean, stdev):
exponent = math.exp(-(math.pow(x-mean,2)/(2*math.pow(stdev,2))))
return (1 / (math.sqrt(2*math.pi) * stdev)) * exponent
# 处理X_train
def summarize(self, train_data):
summaries = [(self.mean(i), self.stdev(i)) for i in zip(*train_data)]
return summaries
# 分类别求出数学期望和标准差
def fit(self, X, y):
labels = list(set(y))
data = {
label:[] for label in labels}
for f, label in zip(X, y):
data[label].append(f)
self.model = {
label: self.summarize(value) for label, value in data.items()}
return 'gaussianNB train done!'
# 计算概率
def calculate_probabilities(self, input_data):
# summaries:{0.0: [(5.0, 0.37),(3.42, 0.40)], 1.0: [(5.8, 0.449),(2.7, 0.27)]}
# input_data:[1.1, 2.2]
probabilities = {
}
for label, value in self.model.items():
probabilities[label] = 1
for i in range(len(value)):
mean, stdev = value[i]
probabilities[label] *= self.gaussian_probability(input_data[i], mean, stdev)
return probabilities
# 类别
def predict(self, X_test):
# {0.0: 2.9680340789325763e-27, 1.0: 3.5749783019849535e-26}
label = sorted(self.calculate_probabilities(X_test).items(), key=lambda x: x[-1])[-1][0]
return label
def score(self, X_test, y_test):
right = 0
for X, y in zip(X_test, y_test):
label = self.predict(X)
if label == y:
right += 1
return right / float(len(X_test))
主函数
model = NaiveBayes()
model.fit(X_train, y_train)
print(model.predict([4.4, 3.2, 1.3, 0.2]))
model.score(X_test, y_test)
2:sklearn贝叶斯实现
from sklearn.naive_bayes import GaussianNB
clf = GaussianNB()
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
clf.predict([[4.4, 3.2, 1.3, 0.2]])

智能推荐
Linux查看登录用户日志_怎么记录linux设备 发声的登录和登出-程序员宅基地
文章浏览阅读8.6k次。一、Linux记录用户登录信息文件1 /var/run/utmp----记录当前正在登录系统的用户信息;2 /var/log/wtmp----记录当前正在登录和历史登录系统的用户信息;3 /var/log/btmp:记录失败的登录尝试信息。二、命令用法1.命令last,lastb---show a listing of la_怎么记录linux设备 发声的登录和登出
第四章笔记:遍历--算法学中的万能钥匙-程序员宅基地
文章浏览阅读167次。摘要:1. 简介 2. 公园迷宫漫步 3. 无线迷宫与最短(不加权)路径问题 4. 强连通分量1. 简介在计算机科学裡,树的遍历(也称为树的搜索)是圖的遍歷的一种,指的是按照某种规则,不重复地访问某种樹的所有节点的过程。具体的访问操作可能是检查节点的值、更新节点的值等。不同的遍历方式,其访问节点的顺序是不一样的。两种著名的基本遍历策略:深度优先搜索(DFS) 和 广度优先搜索(B...
【案例分享】使用ActiveReports报表工具,在.NET MVC模式下动态创建报表_activereports.net 实现查询报表功能-程序员宅基地
文章浏览阅读591次。提起报表,大家会觉得即熟悉又陌生,好像常常在工作中使用,又似乎无法准确描述报表。今天我们来一起了解一下什么是报表,报表的结构、构成元素,以及为什么需要报表。什么是报表简单的说:报表就是通过表格、图表等形式来动态显示数据,并为使用者提供浏览、打印、导出和分析的功能,可以用公式表示为:报表 = 多样的布局 + 动态的数据 + 丰富的输出报表通常包含以下组成部分:报表首页:在报表的开..._activereports.net 实现查询报表功能
Ubuntu18.04 + GNOME xrdp + Docker + GUI_docker xrdp ubuntu-程序员宅基地
文章浏览阅读6.6k次。最近实验室需要用Cadence,这个软件的安装非常麻烦,每一次配置都要几个小时,因此打算把Cadence装进Docker。但是Cadence运行时需要GUI,要对Docker进行一些配置。我们实验室的服务器运行的是Ubuntu18.04,默认桌面GNOME,Cadence装进Centos的Docker。安装Ubuntu18.04服务器上安装Ubuntu18.04的教程非常多,在此不赘述了安装..._docker xrdp ubuntu
iOS AVFoundation实现相机功能_ios avcapturestillimageoutput 兼容性 ios17 崩溃-程序员宅基地
文章浏览阅读1.8k次,点赞2次,收藏2次。首先导入头文件#import 导入头文件后创建几个相机必须实现的对象 /** * AVCaptureSession对象来执行输入设备和输出设备之间的数据传递 */ @property (nonatomic, strong) AVCaptureSession* session; /** * 输入设备 */_ios avcapturestillimageoutput 兼容性 ios17 崩溃
Oracle动态性能视图--v$sysstat_oracle v$sysstat视图-程序员宅基地
文章浏览阅读982次。按照OracleDocument中的描述,v$sysstat存储自数据库实例运行那刻起就开始累计全实例(instance-wide)的资源使用情况。 类似于v$sesstat,该视图存储下列的统计信息:1>.事件发生次数的统计(如:user commits)2>._oracle v$sysstat视图
随便推点
Vue router报错:NavigationDuplicated {_name: "NavigationDuplicated", name: "NavigationDuplicated"}的解决方法_navigationduplicated {_name: 'navigationduplicated-程序员宅基地
文章浏览阅读7.6k次,点赞2次,收藏9次。我最近做SPA项目开发动态树的时候一直遇到以下错误:当我点击文章管理需要跳转路径时一直报NavigationDuplicated {_name: “NavigationDuplicated”, name: “NavigationDuplicated”}这个错误但是当我点击文章管理后,路径跳转却是成功的<template> <div> 文章管理页面 <..._navigationduplicated {_name: 'navigationduplicated', name: 'navigationduplic
Webrtc回声消除模式(Aecm)屏蔽舒适噪音(CNG)_webrtc aecm 杂音-程序员宅基地
文章浏览阅读3.9k次。版本VoiceEngine 4.1.0舒适噪音生成(comfort noise generator,CNG)是一个在通话过程中出现短暂静音时用来为电话通信产生背景噪声的程序。#if defined(WEBRTC_ANDROID) || defined(WEBRTC_IOS)static const EcModes kDefaultEcMode = kEcAecm;#elsestati..._webrtc aecm 杂音
医学成像原理与图像处理一:概论_医学成像与图像处理技术知识点总结-程序员宅基地
文章浏览阅读6.3k次,点赞9次,收藏19次。医学成像原理与图像处理一:概论引言:本系列博客为医学成像原理与图像处理重要笔记,由于是手写,在此通过扫描录入以图片的形式和电子版增补内容将其进行组织和共享。前半部分内容为图像处理基础内容,包括图像的灰度级处理、空间域滤波、频率域滤波、图像增强和分割等;后半部分内容为医学影象技术,包括常规胶片X光机、CR、DR、CT、DSA等X射线摄影技术、超声成像技术、磁共振成像(MRI)技术等。本篇主要内容是概论。_医学成像与图像处理技术知识点总结
notepad++ v8.5.3 安装插件,安装失败怎么处理?下载进度为0怎么处理?_nodepa++-程序员宅基地
文章浏览阅读591次,点赞13次,收藏10次。notepad++ v8.5.3 安装插件,下载进度为0_nodepa++
hive某个字段中包括\n(和换行符冲突)_hive sql \n-程序员宅基地
文章浏览阅读2.1w次。用spark执行SQL保存到Hive中: hiveContext.sql("insert overwrite table test select * from aaa")执行完成,没报错,但是核对结果的时候,发现有几笔数据超出指定范围(实际只包含100/200)最终排查到是ret_pay_remark 字段包含换行符,解决方案:执行SQL中把特殊字符替换掉regexp_replace(..._hive sql \n
印象笔记05:如何打造更美的印象笔记超级笔记_好的印象笔记怎么做的-程序员宅基地
文章浏览阅读520次,点赞10次,收藏8次。印象笔记05:如何打造更美的印象笔记超级笔记本文介绍印象笔记的具体使用,如何打造更美更实用的笔记。首先想要笔记更加好看和实用,我认为要使用超级笔记。所谓超级笔记就是具有很多便捷功能的笔记。_好的印象笔记怎么做的