保姆级教程之VMD-CNN-BILSTM轴承故障诊断,MATLAB代码_轴承故障诊断 代码-程序员宅基地
技术标签: matlab cnn 深度学习 人工智能 神经网络
本期为大家带来VMD-CNN-BILSTM的轴承故障诊断。
和前几期一样,依旧是包含了数据处理,优化VMD参数,特征提取,再到CNN-BiLSTM的故障诊断,其他类型的故障诊断均可参考此流程。数据替换十分简单!
其中优化VMD参数部分,采用的是最新推出的,效率非常高的融合鱼鹰和柯西变异的麻雀优化算法(OCSSA),文件中也包含了该算法与其他算法的对比的代码。
故障诊断部分,本期作者将CNN-LSTM,CNN-BiLSTM,VMD-CNN-LSTM,VMD-CNN-BiLSTM四种故障诊断模型进行了对比。突出了本期提出的VMD-CNN-BILSTM模型的优越性。
友情提示:对于刚接触故障诊断的新手来说,这篇文章信息量可能有点大,大家可以收藏反复阅读。即便有些内容本篇文章没讲出来,但其中的一些跳转链接,也完全把故障诊断这个故事讲清楚了。
与上一期文章相似,先给大家看看文件夹目录,都是作者精心整理过的。
最后一个压缩包是有关VMD画图的程序。考虑到大家可能会用到VMD的相关作图,包络谱,频谱图等,作者在这里也一并附在代码中了。这部分大家需要自行更改数据!也就是作者比较火的文章之一,这里边提到的所有代码:VMD分解,matlab代码,包络线,包络谱,中心频率,峭度值,能量熵,样本熵,模糊熵,排列熵,多尺度排列熵,西储大学数据集为例
如图所示,本期内容一共做了三件事情:
一,对官方下载的西储大学数据进行处理,步骤如下:
1.一共加载10种数据,然后取每个数据的DE_time(%DE是驱动端数据 FE是风扇端数据 BA是加速度数据 选择其中一个就行)
2.设置滑动窗口w,每个数据的故障样本点个数s,每个故障类型的样本量m
3.将所有的数据滑窗完毕之后,综合到一个data变量中
有关西储大学数据的处理之前有文章也讲过,大家可以看这篇文章:西储大学轴承诊断数据处理,matlab免费代码获取
图中的1750,1772,1790是西储大学轴承的转速,大家做诊断的时候,选择其中一个即可,即选同一转速下的不同故障进行诊断更有意义!
二,对第一步数据处理得到的数据进行特征提取
选取五种适应度函数进行优化,这里大家可以自行决定选哪一个!以此确定VMD的最佳k和α参数。五种适应度函数分别是:最小包络熵,最小样本熵,最小信息熵,最小排列熵,排列熵/互信息熵,代码中可以一键切换。至于应该选择哪种作为自己的适应度函数,大家可以看这篇文章。VMD为什么需要进行参数优化,最小包络熵/样本熵/排列熵/信息熵,适应度函数到底该选哪个
老粉应该知道,之前也推过一篇文章,就是关于西储大学特征提取的,但当时作者懒,没有写一个大循环,需要大家针对每种类型的数据依次提取。这次,作者把特征提取写了一个大循环,方便一键特征提取,大家也可以很简单的更换自己的数据!
至于特征提取的具体原理,也在这篇文章进行过详细介绍,大家可以跳转阅读。简单来说,就是利用包络熵最小的准则把每个样本的最佳IMF分量提取出来,然后对其9个指标进行计算,分别是:均值,方差,峰值,峭度,有效值,峰值因子,脉冲因子,波形因子,裕度因子。然后用这9个指标构建每个样本的特征向量。
另外本期文章采用了一个新颖的效率较高的智能算法---效率非常高的融合鱼鹰和柯西变异的麻雀优化算法(OCSSA)对VMD参数进行了优化,该算法是由作者自行改进。找到了每个故障类型的最佳IMF分量,并利用包络熵最小的准则,提取出了最佳的IMF分量。
提取特征后,每种状态是120个样本,一共十个状态,得到一个1200*9列的矩阵,然后对每行数据打上标签。1-10代表不同的故障类型。划分每种状态的前90组为训练集,后30组为测试集。
三,采用CNN-BILSTM实现故障分类
本期作者将CNN-LSTM,CNN-BiLSTM,VMD-CNN-LSTM,VMD-CNN-BiLSTM四种故障诊断模型进行了对比。
结果展示
为了突出VMD-CNN-BiLSTM优越性,将四个模型的训练次数都设置为150,学习率为0.01,正则化参数为0.001,训练100次后开始调整学习率,学习率调整因子为0.01。统计结果如下:
| 算法 | 准确率 | 训练时间 |
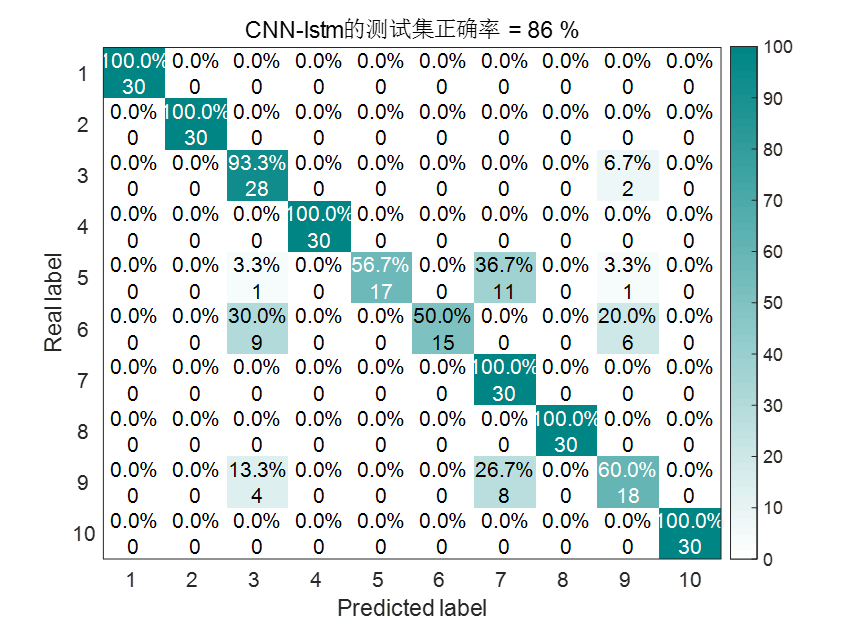
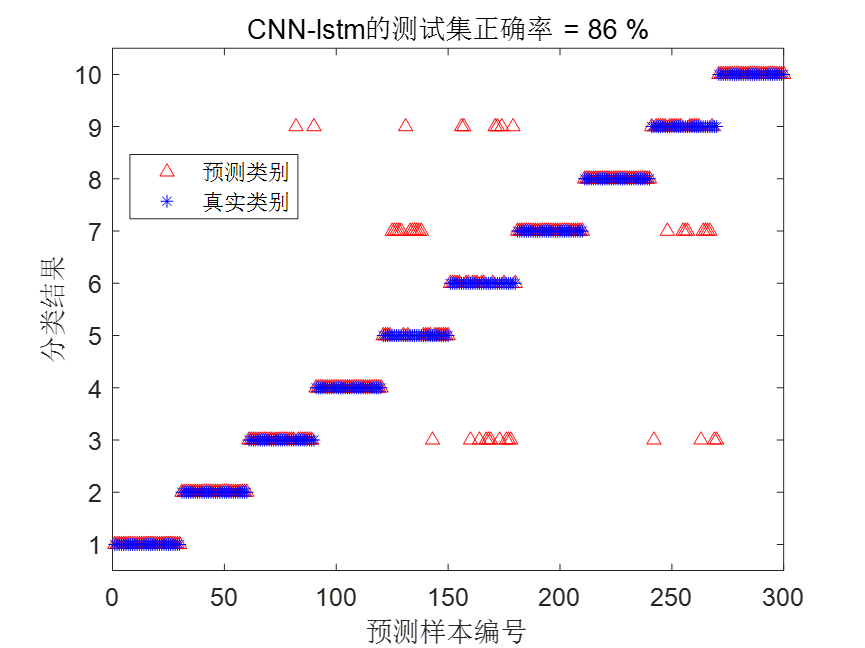
| CNN-LSTM | 86% | 165.003936秒 |
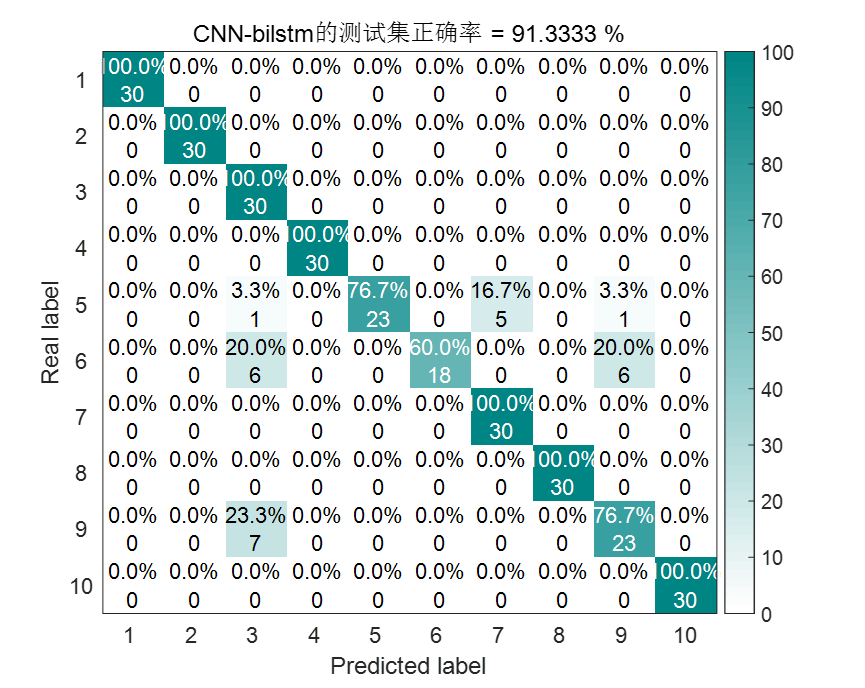
| CNN-BiLSTM | 91.33% | 236.622348秒 |
| VMD-CNN-LSTM | 95.667% | 8.148243秒 |
| VMD-CNN-BiLSTM | 99.33% | 8.905423 秒 |
根据统计结果可以看到,VMD-CNN-BiLSTM诊断模型不仅大大缩减了训练时间,而且诊断精度也是最高的。
CNN-LSTM结果图
CNN-BiLSTM结果图
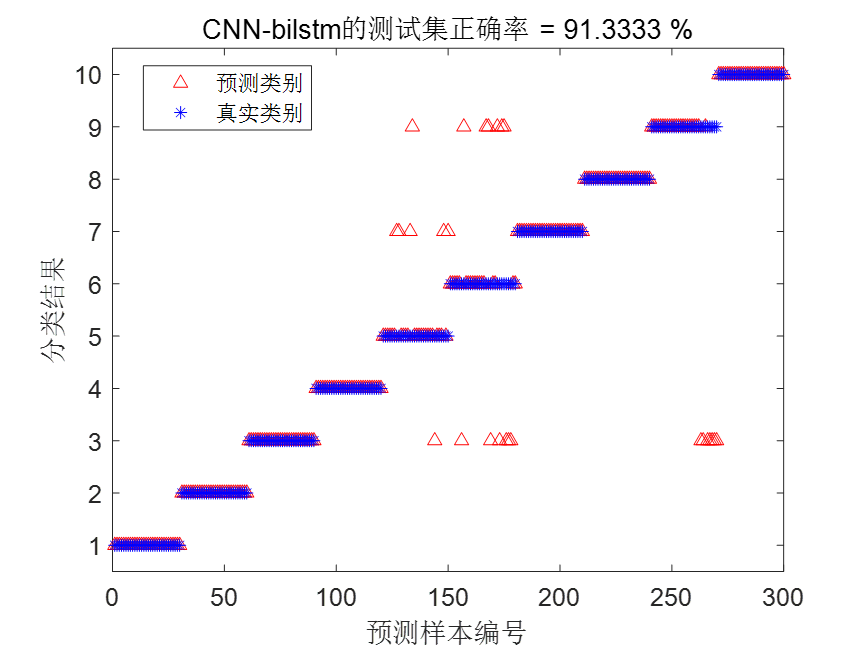
VMD-CNN-LSTM结果图
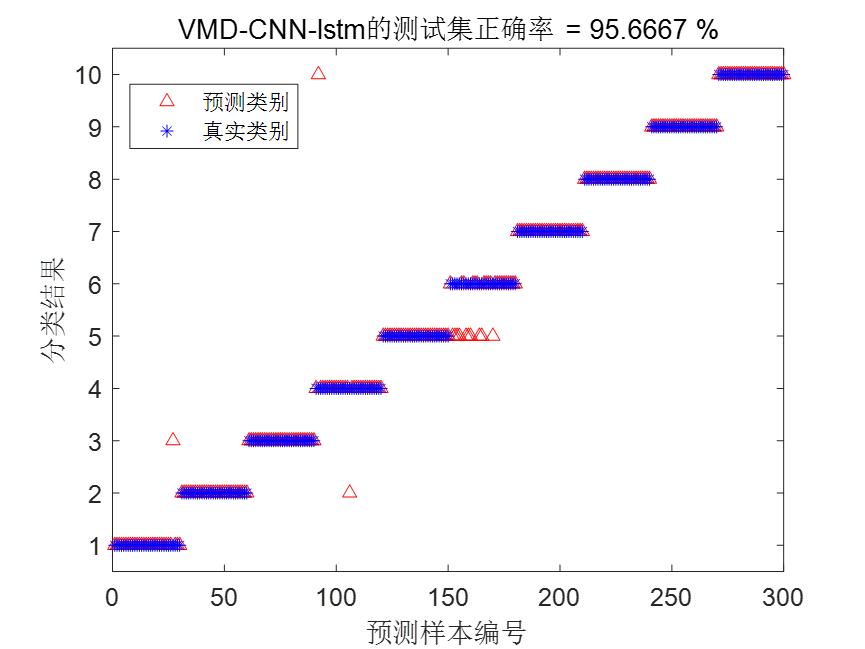

VMD-CNN-BiLSTM结果图

部分代码
数据处理代码:
clc;
clear;
addpath(genpath(pwd));
%DE是驱动端数据 FE是风扇端数据 BA是加速度数据 选择其中一个就行
load 97.mat %正常
load 107.mat %直径0.007英寸,转速为1750时的 内圈故障
load 120.mat %直径0.007,转速为1750时的 滚动体故障
load 132.mat %直径0.007,转速为1750时的 外圈故障
load 171.mat %直径0.014英寸,转速为1750时的 内圈故障
load 187.mat %直径0.014英寸,转速为1750时的 滚动体故障
load 199.mat %直径0.014英寸,转速为1750时的 外圈故障
load 211.mat %直径0.021英寸,转速为1750时的 内圈故障
load 224.mat %直径0.021英寸,转速为1750时的 滚动体故障
load 236.mat %直径0.021英寸,转速为1750时的 外圈故障
w=1000; % w是滑动窗口的大小1000
s=2048; % 每个故障表示有2048个故障点
m = 10; %每种故障有120个样本
D0=[];
for i =1:m
D0 = [D0,X097_DE_time(1+w*(i-1):w*(i-1)+s)];
end
D0 = D0';OCSSA优化VMD参数并特征提取的代码:
%% 此程序运行需要很长的时间!!
% vmddata.mat就是最终特征提取的结果!
%% 以最小包络熵、最小样本熵、最小信息熵、最小排列熵,排列熵/互信息熵,为目标函数(任选其一),采用OCSSA算法优化VMD,求取VMD最佳的两个参数
clear
clc
close all
addpath(genpath(pwd))
xz = 5; %xz, 选择1,以最小包络熵为适应度函数,
% 选择2,以最小样本熵为适应度函数,
% 选择3,以最小信息熵为适应度函数,
% 选择4,以最小排列熵为适应度函数,
% 选择5,以复合指标:排列熵/互信息熵为适应度函数。
if xz == 1
fobj=@EnvelopeEntropyCost; %最小包络熵
elseif xz == 2
fobj=@SampleEntropyCost; %最小样本熵
elseif xz == 3
fobj=@infoEntropyCost; %最小信息熵
elseif xz == 4
fobj=@PermutationEntropyCost; %最小排列熵
elseif xz == 5
fobj=@compositeEntropyCost; %复合指标:排列熵/互信息熵
end
load data_total_1797.mat %这里选取转速为1797的10种故障,大家也可以选取其他类型的数据
D=2; % 优化变量数目
lb=[100 3]; % 下限值,分别是a,k
ub=[2500 10]; % 上限值
T=20; % 最大迭代数目
N=20; % 种群规模
vmddata = [];
for i=1:10 %因为有十种故障状态
disp(['正在对第',num2str(i),'个故障类型的数据进行VMD优化……请耐心等待!'])
every_data = data(1+120*(i-1):120*i,:); %一种状态是120个样本,每次选120个样本进行VMD优化和特征提取
da = every_data(1,:); %从当前状态的数据中任选一组数据进行VMD优化即可。
[OCSSABest_score,OCSSABest_pos,Bestidx,OCSSA_curve] = OCSSA(N,T,lb,ub,D,fobj,da');
display(['第',num2str(i),'个故障类型数据的最佳VMD参数是:', num2str(fix(OCSSABest_pos)),'最佳IMF分量是:IMF',num2str(Bestidx)]); %输出最佳位置
%% 以下为将最佳的a,k,idx回带VMD中,并进行9种时域指标特征提取
bbh = fix(OCSSABest_pos);%最佳位置取整
zuijiazhi(i,:)=[bbh,Bestidx]; %把最佳的惩罚因子,模态分量,最小适应度值对应IMF分量的索引值保存在变量zuijiazhi里
quxian(i,:)=OCSSA_curve; %把每种状态优化VMD寻优的曲线保存在quxian变量中
new_data = tezhengtiqu(bbh(1),bbh(2),Bestidx,every_data); %将优化得到的两个参数和最小适应度的索引值带回VMD中,提取得到当前状态的特征向量
vmddata = [vmddata;new_data]; %将每个状态提取得到的特征向量都放在一起
end
save vmddata.mat vmddata %将提取的特征向量保存为mat文件
save zuijiazhi.mat zuijiazhi %第一列为最佳的惩罚因子,第二列为最佳的模态分量,第三列为最小适应度值对应IMF分量的索引值
save quxian.mat quxian %每一行为一个状态的VMD优化收敛曲线
%% 删除路径,以免被其他函数混淆
rmpath(genpath(pwd))CNNBILSTM诊断的代码:
%% 初始化
clear
close all
clc
warning off
% 数据读取
addpath(genpath(pwd));
load data_total_1797.mat %加载处理好的特征数据
% 数据载入
bv = 120; %每种状态数据有120组
% 加标签值
hhh = size(data,2);
for i=1:size(data,1)/bv
data(1+bv*(i-1):bv*i,hhh+1)=i;
end
input=data(:,1:hhh);
output =data(:,end);
jg = bv; %每组120个样本
tn = 90; %选前tn个样本进行训练
input_train = []; output_train = [];
input_test = []; output_test = [];
for i = 1:max(data(:,end))
input_train=[input_train;input(1+jg*(i-1):jg*(i-1)+tn,:)];
output_train=[output_train;output(1+jg*(i-1):jg*(i-1)+tn,:)];
input_test=[input_test;input(jg*(i-1)+tn+1:i*jg,:)];
output_test=[output_test;output(jg*(i-1)+tn+1:i*jg,:)];
end
input_train = input_train';
input_test = input_test';
%归一化
[inputn_train,inputps]=mapminmax(input_train);
[inputn_test,inputtestps]=mapminmax('apply',input_test,inputps);
output_train = categorical(output_train);
output_test = categorical(output_test);
for i = 1:size(input_train,2)
Train_xNorm{i,:} = reshape(inputn_train(:,i),hhh,1,1);
end
for i = 1:size(input_test,2)
Test_xNorm{i,:} = reshape(inputn_test(:,i),hhh,1,1);
end
numFeatures = size(input,2);
numHiddens = 120;
numClasses = 10;代码获取
每一步代码都有非常详细的注释,数据替换也十分简单!
完整代码获取,点击下方卡片后台回复关键词:
tgdm826
智能推荐
获取大于等于一个整数的最小2次幂算法(HashMap#tableSizeFor)_整数 最小的2的几次方-程序员宅基地
文章浏览阅读2w次,点赞51次,收藏33次。一、需求给定一个整数,返回大于等于该整数的最小2次幂(2的乘方)。例: 输入 输出 -1 1 1 1 3 4 9 16 15 16二、分析当遇到这个需求的时候,我们可能会很容易想到一个"笨"办法:..._整数 最小的2的几次方
Linux 中 ss 命令的使用实例_ss@,,x,, 0-程序员宅基地
文章浏览阅读865次。选项,以防止命令将 IP 地址解析为主机名。如果只想在命令的输出中显示 unix套接字 连接,可以使用。不带任何选项,用来显示已建立连接的所有套接字的列表。如果只想在命令的输出中显示 tcp 连接,可以使用。如果只想在命令的输出中显示 udp 连接,可以使用。如果不想将ip地址解析为主机名称,可以使用。如果要取消命令输出中的标题行,可以使用。如果只想显示被侦听的套接字,可以使用。如果只想显示ipv4侦听的,可以使用。如果只想显示ipv6侦听的,可以使用。_ss@,,x,, 0
conda activate qiuqiu出现不存在activate_commandnotfounderror: 'activate-程序员宅基地
文章浏览阅读568次。CommandNotFoundError: 'activate'_commandnotfounderror: 'activate
Kafka 实战 - Windows10安装Kafka_win10安装部署kafka-程序员宅基地
文章浏览阅读426次,点赞10次,收藏19次。完成以上步骤后,您已在 Windows 10 上成功安装并验证了 Apache Kafka。在生产环境中,通常会将 Kafka 与外部 ZooKeeper 集群配合使用,并考虑配置安全、监控、持久化存储等高级特性。在生产者窗口中输入一些文本消息,然后按 Enter 发送。ZooKeeper 会在新窗口中运行。在另一个命令提示符窗口中,同样切换到 Kafka 的。Kafka 服务器将在新窗口中运行。在新的命令提示符窗口中,切换到 Kafka 的。,应显示已安装的 Java 版本信息。_win10安装部署kafka
【愚公系列】2023年12月 WEBGL专题-缓冲区对象_js 缓冲数据 new float32array-程序员宅基地
文章浏览阅读1.4w次。缓冲区对象(Buffer Object)是在OpenGL中用于存储和管理数据的一种机制。缓冲区对象可以存储各种类型的数据,例如顶点、纹理坐标、颜色等。在渲染过程中,缓冲区对象中存储的数据可以被复制到渲染管线的不同阶段中,例如顶点着色器、几何着色器和片段着色器等,以完成渲染操作。相比传统的CPU访问内存,缓冲区对象的数据存储和管理更加高效,能够提高OpenGL应用的性能表现。_js 缓冲数据 new float32array
四、数学建模之图与网络模型_图论与网络优化数学建模-程序员宅基地
文章浏览阅读912次。(1)图(Graph):图是数学和计算机科学中的一个抽象概念,它由一组节点(顶点)和连接这些节点的边组成。图可以是有向的(有方向的,边有箭头表示方向)或无向的(没有方向的,边没有箭头表示方向)。图用于表示各种关系,如社交网络、电路、地图、组织结构等。(2)网络(Network):网络是一个更广泛的概念,可以包括各种不同类型的连接元素,不仅仅是图中的节点和边。网络可以包括节点、边、连接线、路由器、服务器、通信协议等多种组成部分。网络的概念在各个领域都有应用,包括计算机网络、社交网络、电力网络、交通网络等。_图论与网络优化数学建模
随便推点
android 加载布局状态封装_adnroid加载数据转圈封装全屏转圈封装-程序员宅基地
文章浏览阅读1.5k次。我们经常会碰见 正在加载中,加载出错, “暂无商品”等一系列的相似的布局,因为我们有很多请求网络数据的页面,我们不可能每一个页面都写几个“正在加载中”等布局吧,这时候将这些状态的布局封装在一起就很有必要了。我们可以将这些封装为一个自定布局,然后每次操作该自定义类的方法就行了。 首先一般来说,从服务器拉去数据之前都是“正在加载”页面, 加载成功之后“正在加载”页面消失,展示数据;如果加载失败,就展示_adnroid加载数据转圈封装全屏转圈封装
阿里云服务器(Alibaba Cloud Linux 3)安装部署Mysql8-程序员宅基地
文章浏览阅读1.6k次,点赞23次,收藏29次。PS: 如果执行sudo grep 'temporary password' /var/log/mysqld.log 后没有报错,也没有任何结果显示,说明默认密码为空,可以直接进行下一步(后面设置密码时直接填写新密码就行)。3.(可选)当操作系统为Alibaba Cloud Linux 3时,执行如下命令,安装MySQL所需的库文件。下面示例中,将创建新的MySQL账号,用于远程访问MySQL。2.依次运行以下命令,创建远程登录MySQL的账号,并允许远程主机使用该账号访问MySQL。_alibaba cloud linux 3
excel离散度图表怎么算_excel离散数据表格-Excel 离散程度分析图表如何做-程序员宅基地
文章浏览阅读7.8k次。EXCEL中数据如何做离散性分析纠错。离散不是均值抄AVEDEV……=AVEDEV(A1:A100)算出来的是A1:A100的平均数。离散是指各项目间指标袭的离散均值(各数值的波动情况),数值较低表明项目间各指标波动幅百度小,数值高表明波动幅度较大。可以用excel中的离散公式为STDEV.P(即各指标平均离散)算出最终度离散度。excel表格函数求一组离散型数据,例如,几组C25的...用exc..._excel数据分析离散
学生时期学习资源同步-JavaSE理论知识-程序员宅基地
文章浏览阅读406次,点赞7次,收藏8次。i < 5){ //第3行。int count;System.out.println ("危险!System.out.println(”真”);System.out.println(”假”);System.out.print(“姓名:”);System.out.println("无匹配");System.out.println ("安全");
linux 性能测试磁盘状态监测:iostat监控学习,包含/proc/diskstats、/proc/stat简单了解-程序员宅基地
文章浏览阅读3.6k次。背景测试到性能、压力时,经常需要查看磁盘、网络、内存、cpu的性能值这里简单介绍下各个指标的含义一般磁盘比较关注的就是磁盘的iops,读写速度以及%util(看磁盘是否忙碌)CPU一般比较关注,idle 空闲,有时候也查看wait (如果wait特别大往往是io这边已经达到了瓶颈)iostatiostat uses the files below to create ..._/proc/diskstat
glReadPixels读取保存图片全黑_glreadpixels 全黑-程序员宅基地
文章浏览阅读2.4k次。问题:在Android上使用 glReadPixel 读取当前渲染数据,在若干机型(华为P9以及魅族某魅蓝手机)上读取数据失败,glGetError()没有抓到错误,但是获取到的数据有误,如果将获取到的数据保存成为图片,得到的图片为黑色。解决方法:glReadPixels实际上是从缓冲区中读取数据,如果使用了双缓冲区,则默认是从正在显示的缓冲(即前缓冲)中读取,而绘制工作是默认绘制到后缓..._glreadpixels 全黑