第一部分 Python基础篇(80题)
-
为什么学习Python?
- 语言本身简洁,优美,功能超级强大,跨平台,从桌面应用,web开发,自动化测试运维,爬虫,人工智能,大数据处理都能做
-
Python和Java、PHP、C、C#、C++等其他语言的对比?
- C语言由于其底层操作特性和历史的积累,在嵌入式领域是当之无愧的王者
- . PHP跨平台,性能优越,跟Linux/Unix结合比跟Windows结合性能强45%,开发成本低,PHP 5已经有成熟的面向对象体系,适合开发大型项目淘宝网、Yahoo、163、Sina等等大型门户,很多选用PHP来作为他们的开发语言
- JAVA的优点:1.简单性2.面向对象性(面向对象的程度可以达到95%)3.健壮性4.跨平台性5.高性能(自动垃圾回收机制)6.多线程7.动态性8.安全性
- C++的优点:1.可扩展性强3.可移植性4.面向对象的特性5.强大而灵活的表达能力和不输于C的效率6.支持硬件开发
-
简述解释型和编译型编程语言
- 1.编译型语言在程序执行之前,有一个单独的编译过程,将程序翻译成机器语言,以后执行这个程序的时候,就不用再进行翻译了。
- 2.解释型语言,是在运行的时候将程序翻译成机器语言,所以运行速度相对于编译型语言要慢。
- 3.C/C++ 等都是编译型语言,而Java,C#等都是解释型语言。
- 5.脚本语言一般都有相应的脚本引擎来解释执行。 他们一般需要解释器才能运行。JAVASCRIPT,ASP,PHP,PERL,Nuva都是脚本语言。C/C++编译、链接后,可形成独立执行的exe文件。
-
Python解释器种类以及特点?
- CPython:这个解释器是用C语言开发的,所以叫CPython,在命名行下运行python,就是启动CPython解释器,CPython是使用最广的Python解释器。
- Jython:Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。
- IPython:IPython是基于CPython之上的一个交互式解释器,也就是说,IPython只是在交互方式上有所增强,但是执行Python代码的功能和CPython是完全一样的,好比很多国产浏览器虽然外观不同,但内核其实是调用了IE。
-
位和字节的关系?
- 1 计算机存储信息的最小单位,称之为位(bit),音译比特,二进制的一个“0”或一个“1”叫一位。
- 2、计算机存储容量基本单位是字节(Byte),音译为拜特,8个二进制位组成1个字节,一个标准英文字母占一个字节位置,一个标准汉字占二个字节位置。
-
b、B、KB、MB、GB 的关系?
1024B=1K(千)B
1024KB=1M(兆)B
1024MB=1G(吉)B
1024GB=1T(太)B
什么是PEP8?
PEP8是一个编程规范,内容是一些关于如何让你的程序更具可读性的建议。
其主要内容包括代码编排、文档编排、空格的使用、注释、文档描述、命名规范、编码建议等。
请至少列举5个 PEP8 规范(越多越好)。
- 缩进。4个空格的缩进(编辑器都可以完成此功能),不使用Tap,更不能混合使用Tap和空格。
- 每行最大长度79,换行可以使用反斜杠,最好使用圆括号。换行点要在操作符的后边敲回车。
- 类和top-level函数定义之间空两行;类中的方法定义之间空一行;函数内逻辑无关段落之间空一行;其他地方尽量不要再空行。
- 块注释,在一段代码前增加的注释。在‘#’后加一空格。段落之间以只有‘#’的行间隔
- 各种右括号前不要加空格。
- 逗号、冒号、分号前不要加空格。
- 函数的左括号前不要加空格。如Func(1)。
- 序列的左括号前不要加空格。如list[2]。
- 操作符左右各加一个空格,不要为了对齐增加空格。
- 函数默认参数使用的赋值符左右省略空格。
- 不要将多句语句写在同一行,尽管使用‘;’允许。
- if/for/while语句中,即使执行语句只有一句,也必须另起一行。
- 类的方法第一个参数必须是self,而静态方法第一个参数必须是cls。
.什么是pickling和unpickling?
Pickle模块读入任何Python对象,将它们转换成字符串,然后使用dump函数将其转储到一个文件中——这个过程叫做pickling。
反之从存储的字符串文件中提取原始Python对象的过程,叫做unpickling。
-
通过代码实现如下转换:
二进制转换成十进制:v = “0b1111011”
十进制转换成二进制:v = 18
八进制转换成十进制:v = “011”
十进制转换成八进制:v = 30
十六进制转换成十进制:v = “0x12”
十进制转换成十六进制:v = 87
(1)二进制转换成十进制:v = “0b1111011”
#先将其转换为字符串,再使用int函数,指定进制转换为十进制。
print(int("0b1111011",2))
值为123
(2)十进制转换成二进制:v = 18
print("转换为二进制为:", bin(18))
#转换为二进制为: 0b10010
(3)八进制转换成十进制:v = “011”
print(int("011",8))
#9
(4)十进制转换成八进制:v = 30
print("转换为八进制为:", oct(30))
#转换为八进制为: 0o36
(5)十六进制转换成十进制:v = “0x12”
print(int("0x12",16))
#18
(6)十进制转换成十六进制:v = 87
print("转换为十六进制为:", hex(87))
转换为十六进制为: 0x57
如何实现[‘1’,’2’,’3’]变成[1,2,3] ?
a=['1','2','3'] b=[int(i) for i in a] print(b)
输出为:[1, 2, 3]
-
请编写一个函数实现将IP地址转换成一个整数。
如 10.3.9.12 转换规则为:
10 00001010
3 00000011
9 00001001
12 00001100
再将以上二进制拼接起来计算十进制结果:00001010 00000011 00001001 00001100 = ?
-
python递归的最大层数?
def fab(n): if n == 1: return 1 else: return fab(n-1)+ n print (fab(998)) #得到的最大数为998,以后就是报错了,998这个数值莫名想起广告词····

import sys
sys.setrecursionlimit(100000)
def foo(n):
print(n)
n += 1
foo(n)
if __name__ == '__main__':
foo(1)
#得到的最大数字在3922-3929之间浮动,这个是和计算机有关系的,将数字调到足够大了,已经大于系统堆栈,python已经无法支撑到太大的递归崩了。
-
计算题
-
1、求结果
v=dict.fromkeys(['k1','k2'],[])
v['k1'].append(666)
print(v)
v['k1'] = 777
print(v)v=dict.fromkeys(['k1','k2'],[]) v['k1'].append(666) print(v) #{'k2': [666], 'k1': [666]} v['k1'] = 777 print(v) #{'k2': [666], 'k1': 777}2、求结果
def num():
return [lambda x:i*x for i in range(4)]
print(m(2) for m in num())def num(): return [lambda x:i*x for i in range(4)] print(m(2) for m in num())# <generator object <genexpr> at 0x0000000000B2FA40> 为元祖 print(list(m(2) for m in num())) # [6, 6, 6, 6]3、求结果
a、[i%2 for i in range(10)]
b、( i % 2 for i in range(10) )
a=[i%2 for i in range(10) ] print(a) # 因为 [] 为列表 所以会有结果为[0, 1, 0, 1, 0, 1, 0, 1, 0, 1] b=(i%2 for i in range(10)) print(b) # 因为()为元祖 所以会有结果为 <generator object <genexpr> at 0x0000000000645D00> c=list(b) # 将元祖转换格式为列表 print(c) # 打印c,结果为 [0, 1, 0, 1, 0, 1, 0, 1, 0, 1]
4、求结果:
a. 1 or 2
b. 1 and 2
c. 1 < (2==2)
d. 1 < 2 == 2
print(1 or 2) # 1 print(1 and 2) # 2 print(1<(2==2)) # False 因为2==2为True,而True表示为1,False表示为0,所以1<1,结果为False print(1<2==2) # True python是允许连续比较1<2==2意思是1<2且2==2
-
9;求结果:
v1 = 1 or 3
v2 = 1 and 3
v3 = 0 and 2 and 1
v4 = 0 and 2 or 1
v5 = 0 and 2 or 1 or 4
v6 = 0 or Flase and 1
v2 = 1 and 3 #3 v3 = 0 and 2 and 1 #0 v4 = 0 and 2 or 1 #1 v5 = 0 and 2 or 1 or 4 #1 v6 = 0 or False and 1 #False
-
ascii、unicode、utf-8、gbk 区别?
ASCII码使用一个字节编码,所以它的范围基本是只有英文字母、数字和一些特殊符号 ,只有256个字符。
在表示一个Unicode的字符时,通常会用“U+”然后紧接着一组十六进制的数字来表示这一个字符。在基本多文种平面(英文为 Basic Multilingual Plane,简写 BMP。它又简称为“零号平面”, plane 0)里的所有字符,要用四位十六进制数(例如U+4AE0,共支持六万多个字符);在零号平面以外的字符则需要使用五位或六位十六进制数了。旧版的Unicode标准使用相近的标记方法,但却有些微的差异:在Unicode 3.0里使用“U-”然后紧接着八位数,而“U+”则必须随后紧接着四位数。
Unicode能够表示全世界所有的字节
GBK是只用来编码汉字的,GBK全称《汉字内码扩展规范》,使用双字节编码。
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,又称万国码。由Ken Thompson于1992年创建。现在已经标准化为RFC 3629。UTF-8用1到6个字节编码UNICODE字符。用在网页上可以同一页面显示中文简体繁体及其它语言(如英文,日文,韩文)。
-
字节码和机器码的区别?
字节码
字节码是一种中间码
字节码通常指的是已经经过编译,但与特定机器码无关,需要直译器转译后才能成为机器码的中间代码。字节码通常不像源码一样可以让人阅读,而是编码后的数值常量、引用、指令等构成的序列。
字节码主要为了实现特定软件运行和软件环境、硬件环境无关。字节码的实现方式是通过编译器和虚拟机器。编译器将源码编译成字节码,特定平台上的虚拟机器将字节码转译为可以直接执行的指令。字节码的典型应用为Java语言。
总结:字节码是一种中间状态(中间码)的二进制代码(文件)。需要直译器转译后才能成为机器码。
机器码
机器码就是计算机可以直接执行,并且执行速度最快的代码。
用机器语言编写程序,编程人员要首先熟记所用计算机的全部指令代码和代码的涵义。手编程序时,程序员得自己处理每条指令和每一数据的存储分配和输入输出,还得记住编程过程中每步所使用的工作单元处在何种状态。这是一件十分繁琐的工作,编写程序花费的时间往往是实际运行时间的几十倍或几百倍。而且,编出的程序全是些0和1的指令代码。
机器语言是微处理器理解和使用的,用于控制它的操作二进制代码。
8086到Pentium的机器语言指令长度可以从1字节到13字节。
尽管机器语言好像是很复杂的,然而它是有规律的。
存在着多至100000种机器语言的指令。这意味着不能把这些种类全部列出来。
总结:机器码是电脑CPU直接读取运行的机器指令,运行速度最快
-
三元运算规则以及应用场景?
三元运算符的功能与“if...else”流程语句一致,它在一行中书写,代码非常精练、执行效率更高。在PHP程序中恰当地使用三元运算符能够令脚本更为简洁、高效。代码格式如下:
(expr1) ? (expr2) : (expr3);
解释:如果条件“expr1”成立,则执行语句“expr2”,否则执行“expr3”。
实现同样的功能,若使用条件流程语句,就需要书写多行代码:
if(expr1) {
expr2;
} else {
expr3;
}
可见,前面所说的三元运算符之好并非夸张。可是,多数情况下我们只在代码较为简单的时候使用三元运算符,即执行语句只为单句的时候。如:
$a>$b ? print "a大于b" : print "a小于b";
事实上,三元运算符可以扩展使用,当设置的条件成立或不成立,执行语句都可以不止一句,试看以下格式:
(expr1) ? (expr2).(expr3) : (expr4).(expr5);
我们非常明显地看到,多个执行语句可以使用用字符串运算符号(“.”)连接起来,各执行语句用小角括号包围起来以表明它是一个独立而完整的执行语句。这样扩展后它的功能更为逼近“if...else”流程语句。
同时三元运算符还可以嵌套使用。例如,a大于b成立时:如果a小于c,那么x=c-a否则x=a-c;否则a小于b成立时:如果b小于c,那么x=c-b否则x=b-c:
$a>$b ? $x=($a<$c ? $c-$a : $a-$c) : $x=($b<$c ? $c-$b : $b-$c);
嵌套使用的三元运算符可读性不太好,日后对代码的维护极可能存在问题,但比起“if...else”之类的流程语句,在上述情形之下,它的确太简练了,这是它的诱人之处。
对于喜欢偷懒和追求代码简洁的人来说,用三元运算符取代if流程语句应该是绝佳的选择。即使不用考虑“三元”中条件句以外的任意某一“元”,使用三元运算符仍然比if语句简练。以下语句的语法是正确的,它们以小解引号的方式忽略了第二或第三“元”:
$a>$b ? print "Yes" : ""; $a>$b ? '': print 'No';
应该注意的是:在使用三元运算符时,建议使用print语句替代echo语句。
Python自省
这个也是python彪悍的特性.
自省就是面向对象的语言所写的程序在运行时,所能知道对象的类型.简单一句就是运行时能够获得对象的类型.比如type(),dir(),getattr(),hasattr(),isinstance().
-
列举 Python2和Python3的区别?
(1)Print
在 Python 2 中, print 被视为一个语句而不是一个函数,这是一个典型的容易弄混的地方,因为在 Python 中的许多操作都需要括号内的参数来执行。如果在 Python 2 中你想要你的控制台输出 ”Sammy the Shark is my favorite sea creature”,你应该写下这样的 print 语句:
print "Sammy the Shark is my favorite sea creature"
在使用 Python 3 时,print()会被显式地视为一个函数,因此要输出上面相同的字符串,你可以使用这种非常简单且易于使用的函数语法:
print("Sammy the Shark is my favorite sea creature")
这种改变使得 Python 的语法更加一致,并且在不同的 print 函数之间进行切换更加容易。就方便性而言,print()语法也与 Python 2.7 向后兼容,因此您的 Python 3 print()函数可以在任一版本中运行。
(2)整数的除法
在 Python 2 中,您键入的任何不带小数的数字,将被视为整数的编程类型。虽然乍看起来这似乎是一个简单的处理编程类型的方法,但有时候当你试图除以整数以期望获得一个带小数位的答案(称为浮点数),如:
5 / 2 = 2.5
然而,在 Python 2 中,整数是强类型的,并且不会变成带小数位的浮点数,即使这样做具有直观上的意义。
当除法/符号的任一侧的两个数字是整数时,Python 2进行底除法,使得对于商x,返回的数字是小于或等于x的最大整数。这意味着当你写下 5 / 2 来对这两个数字相除时,Python 2.7 将返回最大的小于或等于 2.5 的整数,在这种情形下:
a = 5 / 2 print a #a=2
为解决这个问题,你可以在 5.0 / 2.0 中添加小数位,以得到预期的答案 2.5。
在 Python 3 中,整数除法变得更直观,如
a = 5 / 2 print(a) #a=2.5
你也可以使用 5.0 / 2.0 返回 2.5,但是如果你想做底层划分,你应该使用 “//” 这样的 Python 3 语法,像这样:
b = 5 // 2 print(b) #b=2
在 Python 3 中的这种修改使得整数除法更为直观,并且它的特点是不能向后兼容 Python 2.7。
(3)支持 Unicode
当编程语言处理字符串类型时,也就是一个字符序列,它们可以用几种不同的方式来做,以便计算机将数字转换为字母和其他符号。
Python 2 默认使用 ASCII 字母表,因此当您输入“Hello,Sammy!”时, Python 2 将以 ASCII 格式处理字符串。被限定为在多种扩展形式上的数百个字符,用ASCII 进行字符编码并不是一种非常灵活的方法,特别是使用非英语字符时。
要使用更通用和更强大的Unicode字符编码,这种编码支持超过128,000个跨越现今和历史的脚本和符号集的字符,你必须输入
u“Hello,Sammy!”
, 前缀 u 代表 Unicode。
Python 3 默认使用 Unicode,这节省了程序员多余的开发时间,并且您可以轻松地在程序中直接键入和显示更多的字符。因为 Unicode 支持更强大的语言字符多样性以及 emoji 的显示,所以将它作为默认字符编码来使用,能确保全球的移动设备在您的开发项目中都能得到支持。
如果你希望你的 Python 3 代码向后兼容 Python 2,你可以通过在你的字符串的前面保留 “u” 来实现。
(4)后续发展
Python 3 和 Python 2 之间的最大区别不是语法上的,而是事实上 Python 2.7 将在 2020 年失去后续的支持,Python 3 将继续开发更多的功能和修复更多的错误。
最近的发展包括格式化的字符串,类创建的简单定制,和用一种更干净的句法方式来处理矩阵乘法。
Python 3 的后续开发意味着,开发人员可以对问题被及时解决抱有信心,并且随着时间的推移更多的功能将被添加进来,程序也会变得更加有效。
-
用一行代码实现数值交换:
a = 1
b = 2
a,b=b,a print(a,b) #a=2,b=1
-
Python3和Python2中 int 和 long的区别?
long整数类型被Python3废弃,统一使用int
python2和python3区别?列举5个
1、Python3 使用 print 必须要以小括号包裹打印内容,比如 print('hi')
Python2 既可以使用带小括号的方式,也可以使用一个空格来分隔打印内容,比如 print 'hi'
2、python2 range(1,10)返回列表,python3中返回迭代器,节约内存
3、python2中使用ascii编码,python中使用utf-8编码
4、python2中unicode表示字符串序列,str表示字节序列
python3中str表示字符串序列,byte表示字节序列
5、python2中为正常显示中文,引入coding声明,python3中不需要
6、python2中是raw_input()函数,python3中是input()函数
-
xrange和range的区别?
range 函数说明:range([start,] stop[, step]),根据start与stop指定的范围以及step设定的步长,生成一个序列。
range示例:
>>> range(5) [0, 1, 2, 3, 4] >>> range(1,5) [1, 2, 3, 4] >>> range(0,6,2) [0, 2, 4]
xrange 函数说明:用法与range完全相同,所不同的是生成的不是一个数组,而是一个生成器。
xrange示例:
>>> xrange(5) xrange(5) >>> list(xrange(5)) [0, 1, 2, 3, 4] >>> xrange(1,5) xrange(1, 5) >>> list(xrange(1,5)) [1, 2, 3, 4] >>> xrange(0,6,2) xrange(0, 6, 2) >>> list(xrange(0,6,2)) [0, 2, 4]
由上面的示例可以知道:要生成很大的数字序列的时候,用xrange会比range性能优很多,因为不需要一上来就开辟一块很大的内存空间,这两个基本上都是在循环的时候用:
for i in range(0, 100): print i for i in xrange(0, 100): print i
这两个输出的结果都是一样的,实际上有很多不同,range会直接生成一个list对象:
a = range(0,100) print type(a) print a print a[0], a[1]
输出结果:
<type 'list'> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99] 0 1
而xrange则不会直接生成一个list,而是每次调用返回其中的一个值:
a = xrange(0,100) print type(a) print a print a[0], a[1]
结果如下:
<type 'xrange'> xrange(100) 0
总结:
1.range和xrange都是在循环中使用,输出结果一样。
2.range返回的是一个list对象,而xrange返回的是一个生成器对象(xrange object)。
3.xrange则不会直接生成一个list,而是每次调用返回其中的一个值,内存空间使用极少,因而性能非常好。
注意:Python 3.x已经去掉xrange,全部用range代替。
-
文件操作时:xreadlines和readlines的区别?
二者使用时相同,但返回类型不同,xreadlines返回的是一个生成器,readlines返回的是list
-
列举布尔值为False的常见值?
-
字符串、列表、元组、字典每个常用的5个方法?
字符串
words = 'today is a wonderfulday'
print(words.strip('today'))#如果strip方法指定一个值的话,那么会去掉这两个值
print(words.count('a'))#统计字符串出现的次数
print(words.index('is'))#找下标
print(words.index('z'))#找下标如果元素不找不到的话,会报错
print(words.find('z'))#找下标,如果元素找不到的话,返回-1
print(words.replace('day','DAY'))#字符串替换
print(words.isdigit())#判断字符串是否为纯数字
print(words.islower())#判断字符串是否为小写字母
print(words.isupper())#判断字符串是否为大写字母
print(words.startswith('http'))#判断是否以某个字符串开头
print(words.endswith('.jpg'))#判断是否以某个字符串结尾
print(words.upper())#将字符串变成大写
print(words.lower())#将字符串变成小写
- 移除空白
- 分割
- 长度
- 索引
- 切片
列表
sample_list = ['a',1,('a','b')] #创建列表
sample_list = ['a','b',0,1,3] # Python 列表操作
value_start = sample_list[0] #得到列表中的某一个值
end_value = sample_list[-1] #得到列表中的某一个值
del sample_list[0] #删除列表的第一个值
sample_list[0:0] = ['sample value'] #在列表中插入一个值
list_length = len(sample_list) #得到列表的长度
for element in sample_list: #列表遍历
print(element)
基本操作:
- 索引
- 切片
- 追加
- 删除
- 长度
- 切片
- 循环
- 包含
元祖
#元组也是一个list,他和list的区别是元组的元素无法修改
tuple1 = (2,3,4,5,6,4,7)
print(type(tuple1))
print(tuple1[:7])
print(tuple1[:5:-1])
for i in range(6):
print(tuple1[i])
for i in tuple1:
print(i)
- 索引
- 切片
- 循环
- 长度
- 包含
字典
dict = {'ob1':'computer', 'ob2':'mouse', 'ob3':'printer'}
每一个元素是pair,包含key、value两部分。key是Integer或string类型,value 是任意类型。
键是唯一的,字典只认最后一个赋的键值。
dictionary的方法
D.get(key, 0) #同dict[key],多了个没有则返回缺省值,0。[]没有则抛异常
D.has_key(key) #有该键返回TRUE,否则FALSE
D.keys() #返回字典键的列表
D.values()
D.items()
D.update(dict2) #增加合并字典
D.popitem() #得到一个pair,并从字典中删除它。已空则抛异常
D.clear() #清空字典,同del dict
D.copy() #拷贝字典
D.cmp(dict1,dict2) #比较字典,(优先级为元素个数、键大小、键值大小)
#第一个大返回1,小返回-1,一样返回0
dictionary的复制
dict1 = dict #别名
dict2=dict.copy() #克隆,即另一个拷贝。
常用操作:
- 索引
- 新增
- 删除
- 键、值、键值对
- 循环
- 长度
匿名函数
匿名函数:为了解决那些功能很简单的需求而设计的一句话函数
#这段代码
def calc(n):
return n**n
print(calc(10))
#换成匿名函数
calc = lambda n:n**n
print(calc(10))
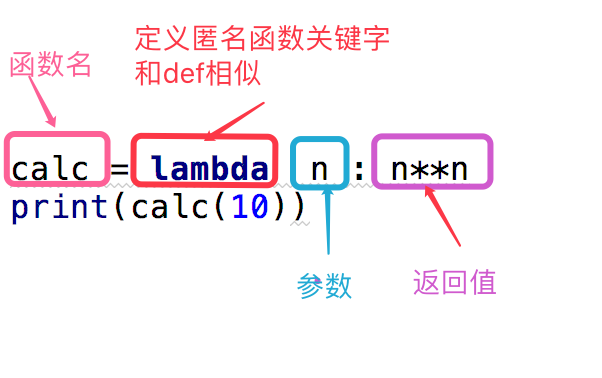
上面是我们对calc这个匿名函数的分析,下面给出了一个关于匿名函数格式的说明
函数名 = lambda 参数 :返回值 #参数可以有多个,用逗号隔开 #匿名函数不管逻辑多复杂,只能写一行,且逻辑执行结束后的内容就是返回值 #返回值和正常的函数一样可以是任意数据类型
我们可以看出,匿名函数并不是真的不能有名字。
匿名函数的调用和正常的调用也没有什么分别。 就是 函数名(参数) 就可以了~~~
-
lambda表达式格式以及应用场景?
lambda表达式,通常是在需要一个函数,但是又不想费神去命名一个函数的场合下使用,也就是指匿名函数。
lambda函数的语法只包含一个语句,如下:
lambda [arg1 [,arg2,.....argn]]:expression
如下实例:
sum = lambda arg1, arg2: arg1 + arg2
#调用sum函数
print "Value of total : ", sum( 10, 20 ) print "Value of total : ", sum( 20, 20 ) 以上实例输出结果:
Value of total : 30
Value of total : 40
Lambda函数能接收任何数量的参数但只能返回一个表达式的值
匿名函数不能直接调用print,因为lambda需要一个表达式
-
pass的作用?
1、空语句 do nothing
if true:
pass #do nothing
else:
pass #do something
2、保证格式完整
def iplaypython():
pass
3、保证语义完整
while True:
pass
-
*arg和**kwarg作用
要想理解*arg和**kwarg的作用,先别着急,通过下面的示例,慢慢思考体会下他们的作用是什么?
*arg
比如现在我有一个最简单的加法(Jiafa)函数:
def Jiafa(x, y):
z = x + y
return z
print(Jiafa(1,2))
这个很简单,一看就知道输出等于3。
那下一个问题是,如果我要算不固定个数的数字相加,那怎么来计算呢?
这时,就使用args和*kwarg,就可以帮助我们解决这种问题。
*args:可以理解为只有一列的表格,长度不固定。
**kwargs:可以理解为字典,长度也不固定。
先说args的作用,还是开篇的案例,我们要算不定长的加法,就可以用args来定义了,当然也可以叫x,y。
def Jiafa(*args):
sum = 0
for i in args:
sum = sum + i
print(sum)
Jiafa(1, 3, 5)
Jiafa(2, 4, 6, 8, )
输出结果,9和20。这个案例很简单,用*args定义就可以引入,相当于定义了不定长度的函数,然后在程序中就可以多次使用。
**kwargs
**kwargs的字典呢?先看一下普通的字典,用一对大括号{}就可以创建字典,比如下面3行程序,就可以编一个字典的程序:
dict = {"system": "系统", "China": "中国", "link": "联接"}
x = input("请输入一个英文单词:")
print(dict.get(x, "本字典里没找到!"))
如果输入正确,会得到答案,否则会显示没找到。
在这个程序里,dict = {"system": "系统", "China": "中国", "link": "联接"}创建了三对“键和值”(key和value),比如“system”是key,“系统”是key对应的值,也叫键值。
还可以写一个测试单词的小软件。
dict = {"system": "系统", "China": "中国", "link": "联接"}
通过Key找value的语句:
y = input("请输入China的中文意思:")
if dict['China'] == y:
print("恭喜你,答对了!")
通过value找Key的语句:
z = input("请输入“系统”的英文单词:")
if list(dict.keys())[list(dict.values()).index("系统")] == z:
print("恭喜你,答对了!")
现在问题来了,如果开始不知道字典里都有哪些内容,需要在程序运程中才知道怎么办?这个时候就可以用kwargs来定义了。我们先用kwargs来定义一个函数,函数内容先都不用写,再看看下面的小程序:
def dict(**kwargs):
return kwargs
mydict = dict(system="系统", China="中国", link="联接")
x = input("请输入单词:")
if x in mydict.keys():
print("中文意思:", mydict[x])
else:
print("抱歉,没找到。")
用字典也可以达成这样的功能,使用in……keys(),就是判断这个key是不是存在,如果存在就返回它的值。 同样,用**kwargs传递数据的功能,还可以设计一个用户登录的程序:
def dict(**kwargs):
return kwargs
userdict = dict(user1="1234", user2="5678")
x = input("请输入用户名:")
if x in userdict.keys():
y = input("请输入密码:")
if userdict[x] == y:
print("完全正确")
else:
print("密码错误!")
else:
print("用户不存在!")
所以从以上的示例可以看到*arg和**kwarg的作用为:
1、函数调用里的*arg和**kwarg:
(1)*arg:元组或列表“出现”
**kwarg:字典“出没”
(2)分割参数
2、函数定义时传的*arg /**kwarg:
(1)接收参数
-
is和==的区别
is是对比地址,==是对比值
>>> a = 'cheesezh' >>> b = 'cheesezh' >>> a == b True
is也被叫做同一性运算符,这个运算符比较判断的是对象间的唯一身份标识,也就是id是否相同。通过对下面几个list间的比较,你就会明白is同一性运算符的工作原理:
例2:
>>> x = y = [4,5,6] >>> z = [4,5,6] >>> x == y True >>> x == z True >>> x is y True >>> x is z False >>> >>> print id(x) 3075326572 >>> print id(y) 3075326572 >>> print id(z) 3075328140
前三个例子都是True,这什么最后一个是False呢?x、y和z的值是相同的,所以前两个是True没有问题。至于最后一个为什么是False,看看三个对象的id分别是什么就会明白了。
下面再来看一个例子,例3中同一类型下的a和b的(a==b)都是为True,而(a is b)则不然。
>>> a = 1 #a和b为数值类型
>>> b = 1
>>> a is b
True
>>> id(a)
14318944
>>> id(b)
14318944
>>> a = 'cheesezh' #a和b为字符串类型
>>> b = 'cheesezh'
>>> a is b
True
>>> id(a)
42111872
>>> id(b)
42111872
>>> a = (1,2,3) #a和b为元组类型
>>> b = (1,2,3)
>>> a is b
False
>>> id(a)
15001280
>>> id(b)
14790408
>>> a = [1,2,3] #a和b为list类型
>>> b = [1,2,3]
>>> a is b
False
>>> id(a)
42091624
>>> id(b)
42082016
>>> a = {'cheese':1,'zh':2} #a和b为dict类型
>>> b = {'cheese':1,'zh':2}
>>> a is b
False
>>> id(a)
42101616
>>> id(b)
42098736
>>> a = set([1,2,3])#a和b为set类型
>>> b = set([1,2,3])
>>> a is b
False
>>> id(a)
14819976
>>> id(b)
14822256
通过例3可看出,is同一性运算符只有数值型和字符串型的情况下,a is b才为True,当a和b是tuple(元祖),list,dict或set型时,a is b为False。
-
简述Python的深浅拷贝以及应用场景?
深浅拷贝用法来自copy模块。
导入模块:import copy
浅拷贝:copy.copy
深拷贝:copy.deepcopy
字面理解:浅拷贝指仅仅拷贝数据集合的第一层数据,深拷贝指拷贝数据集合的所有层。所以对于只有一层的数据集合来说深浅拷贝的意义是一样的,比如字符串,数字,还有仅仅一层的字典、列表、元祖等.
对于以下数据深浅拷贝的意义是一样的(因为数据类型中只有一层):
name = 'beijing' #字符串
age = 12 #数字
list1 = [1,2,3,4] #列表
dic1 = {'name':'beijing','age':20} #字典
从内存地址来理解深浅拷贝:
深浅拷贝:
字符串,数字的深浅拷贝
>>> import copy >>> name="hahah" #字符串 >>> name1=copy.copy(name) >>> >>> name2=copy.deepcopy(name) >>> print(id(name),id(name1),id(name2)) 11577192 11577192 11577192 >>> sum=111 #数字 >>> sum1=copy.copy(sum) >>> >>> sum2=copy.deepcopy(sum) >>> print(id(sum),id(sum1),id(sum2)) 503865568 503865568 503865568
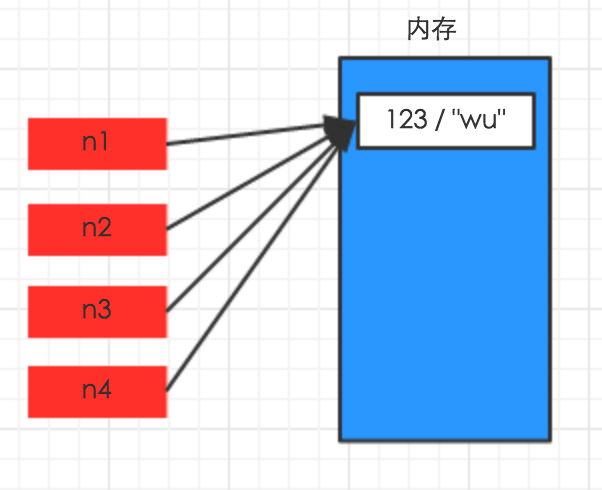
如上图,对于数字和字符串的深浅拷贝都只是将变量的索引指向了原来的内存地址,例如在sum,sum1,sum2三个变量中,无论修改任意其中一个变量,只是将其指向了另一个内存地址,其他两个变量不会变,字符串同理。因此,对于 数字 和 字符串 而言,赋值、浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址。
字典(列表)的深浅拷贝
赋值:
import copy
n1 = {'k1':'wu','k2':123,'k3':['alex',678]}
n2 = n1
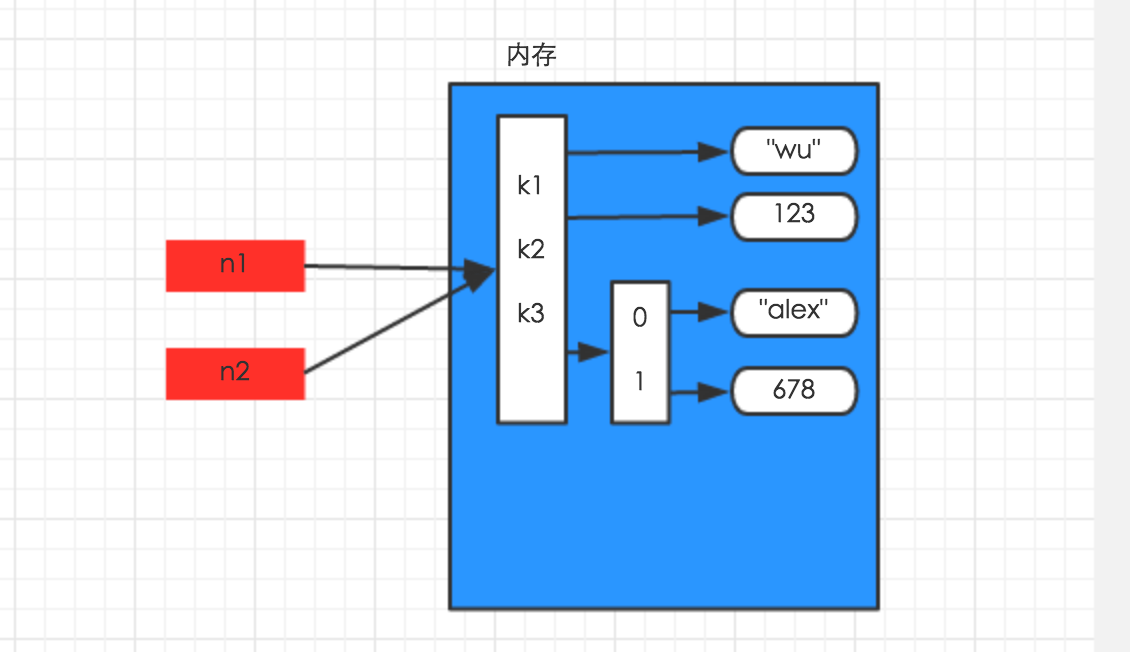
浅拷贝:
import copy
n1 = {'k1':'wu','k2':123,'k3':['alex',678]}
n3 = copy.copy(n1)
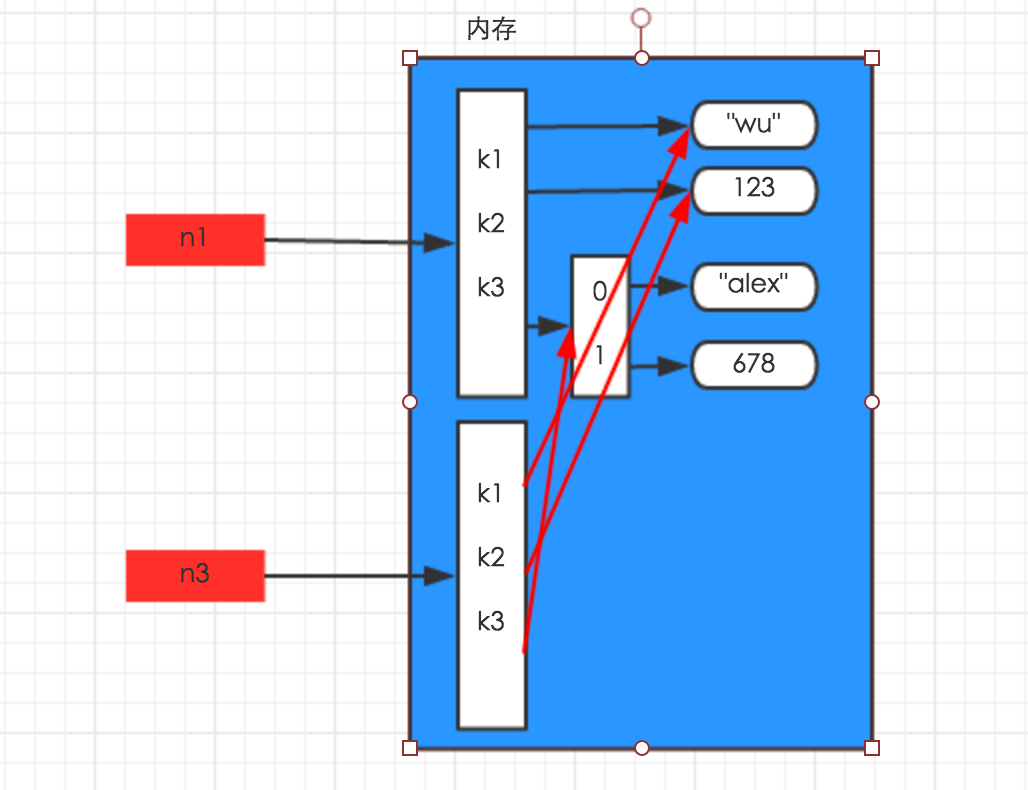
深拷贝:
import copy
n1 = {'k1':'wu','k2':123,'k3':['alex',678]}
n4 = copy.deepcopy(n1)
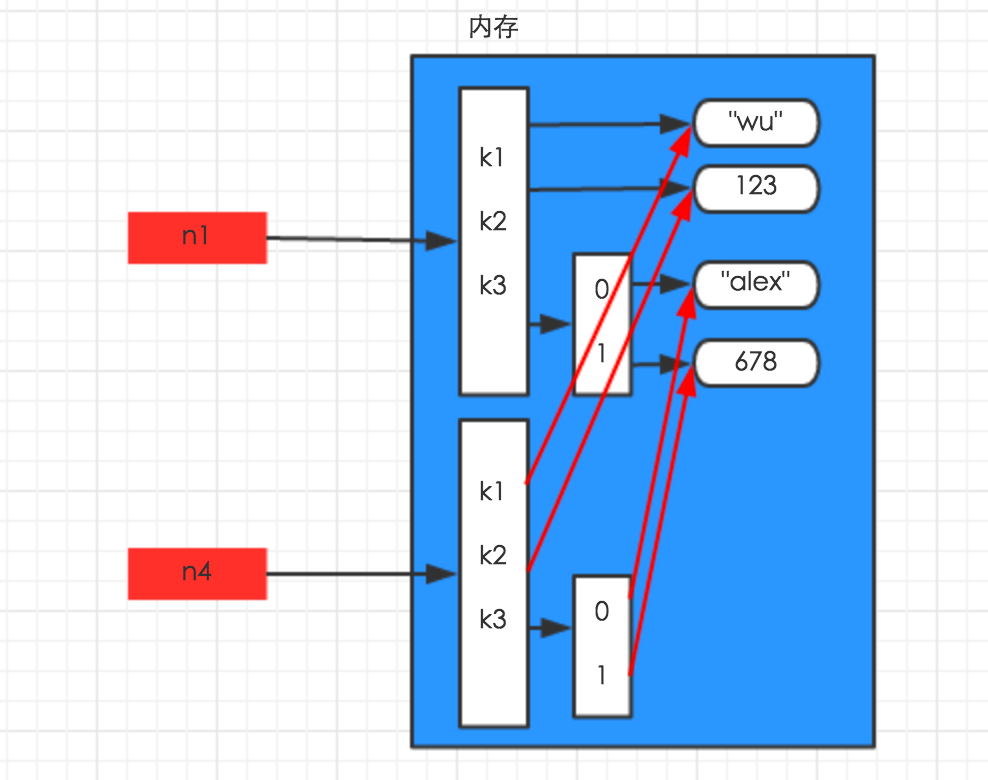
深浅拷贝的应用场景
比如在CMDB系统中,我们定义了一个报警模版call给所有的服务器使用,此时有一批特殊应用的服务器需要不通的报警参数,我们既不想单独新建模版来一个一个添加报警参数,又不想修改默认模版而影响其他机器的报警阈值。此时我们就需要用深拷贝来完成。示例如下:
默认模版:
call = {
'cpu':80,
'mem':80,
'disk':80
}
此时的特殊模版需求是cpu报警阀值要改成75,而不影响默认模版使用
代码如下:
import copy
#默认模版
call = {
'cpu':[80,],
'mem':[80,],
'disk':[80,]
}
#新模板
new_call = copy.deepcopy(call)
#修改新模版
new_call['cpu'] = 75
#查看新旧模版的值
print('新的模版为:%s' %(new_call))
print('默认模版为:%s' %(call))
#打印结果:
#新的模版为:{'mem': 80, 'disk': 80, 'cpu': 75}
#默认模版为:{'mem': 80, 'disk': 80, 'cpu': 80}
#上面的代码显示我们只改了新的模版,而默认模版并没有修改,并且我们用了copy而不是单独新建模版。
假设我们用浅copy来做结果是这样的:
import copy
#默认模版
call = {
'cpu':[80,],
'mem':[80,],
'disk':[80,]
}
#新模板
new_call = copy.copy(call)
#修改新模版
new_call['cpu'] = 75
#查看新旧模版的值
print('新的模版为:%s' %(new_call))
print('默认模版为:%s' %(call))
#打印的结果:
#新的模版为:{'mem': [80], 'disk': [80], 'cpu': [75]}
#默认模版为:{'mem': [80], 'disk': [80], 'cpu': [75]}
#默认模版和新模版都被修改了,显然这不是我们要的结果
分析原因:深拷贝的时候python将字典的所有数据在内存中新建了一份,所以如果你修改新的模版的时候老模版不会变。相反,在浅copy 的时候,python仅仅将最外层的内容在内存中新建了一份出来,字典第二层的列表并没有在内存中新建,所以你修改了新模版,默认模版也被修改了。
-
Python垃圾回收机制?
Python中的垃圾回收是以引用计数为主,标记-清除和分代收集为辅。
引用计数:Python在内存中存储每个对象的引用计数,如果计数变成0,该对象就会消失,分配给该对象的内存就会释放出来。
标记-清除:一些容器对象,比如list、dict、tuple,instance等可能会出现引用循环,对于这些循环,垃圾回收器会定时回收这些循环(对象之间通过引用(指针)
连在一起,构成一个有向图,对象构成这个有向图的节点,而引用关系构成这个有向图的边)。
分代收集:Python把内存根据对象存活时间划分为三代,对象创建之后,垃圾回收器会分配它们所属的代。每个对象都会被分配一个代,而被分配更年轻的代是被优先处理的,因此越晚创建的对象越容易被回收。
-
Python的可变类型和不可变类型?
Python的每个对象都分为可变和不可变
可变:列表、字典
不可变:数字、字符串、元祖
对不可变类型的变量重新赋值,实际上是重新创建一个不可变类型的对象,并将原来的变量重新指向新创建的对象(如果没有其他变量引用原有对象的话(即引用计数为0),原有对象就会被回收)。
不可变类型
以int类型为例:实际上 i += 1 并不是真的在原有的int对象上+1,而是重新创建一个value为6的int对象,i引用自这个新的对象。
>>> i = 5 >>> i += 1 >>> i 6 >>> id(i) 140243713967984 # 通过id函数查看变量i的内存地址进行验证(使用hex(id(i)) 可以查看16进制的内存地址) >>> i += 1 >>> i 7 >>> id(i) 140243713967960
可以看到执行 i += 1 时,内存地址都会变化,因为int 类型是不可变的。
再改改代码,但多个int类型的变量值相同时,看看它们内存地址是否相同。
>>> i = 5 >>> j = 5 >>> id(i) 140656970352216 >>> id(j) 140656970352216 >>> k = 5 >>> id(k) 140656970352216 >>> x = 6 >>> id(x) 140656970352192 >>> y = 6 >>> id(y) 140656970352192 >>> z = 6 >>> id(z) 140656970352192
对于不可变类型int,无论创建多少个不可变类型,只要值相同,都指向同个内存地址。同样情况的还有比较短的字符串。
对于其他类型则不同,以浮点类型为例,从代码运行结果可以看出它是个不可变类型:对i的值进行修改后,指向新的内存地址。
>>> i = 1.5 >>> id(i) 140675668569024 >>> i = i + 1.7 >>> i 3.2 >>> id(i) 140675668568976
修改代码声明两个相同值的浮点型变量,查看它们的id,发现它们并不是指向同个内存地址,这点和int类型不同(这方面涉及Python内存管理机制,Python对int类型和较短的字符串进行了缓存,无论声明多少个值相同的变量,实际上都指向同个内存地址。)
>>> i = 2.5 >>> id(i) 140564351733040 >>> j = 2.5 >>> id(j) 140564351733016
可变类型
可变类型的话,以list为例。list在append之后,还是指向同个内存地址,因为list是可变类型,可以在原处修改。
>>> a = [1, 2, 3] >>> id(a) 4385327224 >>> a.append(4) >>> id(a) 4385327224
改改代码,当存在多个值相同的不可变类型变量时,看看它们是不是跟可变类型一样指向同个内存地址
>>> a = [1, 2, 3] >>> id(a) 4435060856 >>> b = [1, 2, 3] >>> id(b) 4435102392
从运行结果可以看出,虽然a、b的值相同,但是指向的内存地址不同。我们也可以通过b = a 的赋值语句,让他们指向同个内存地址:
>>> a = [1, 2, 3] >>> id(a) 4435060856 >>> b = [1, 2, 3] >>> id(b) 4435102392 >>> b = a >>> id(b) 4435060856
这个时候需要注意,因为a、b指向同个内存地址,而a、b的类型都是List,可变类型,对a、b任意一个List进行修改,都会影响另外一个List的值。
>>> a = [1, 2, 3] >>> id(a) #4435060856 >>> b = [1, 2, 3] >>> id(b) #4435102392 >>> b = a >>> id(b) #4435060856 >>> b.append(4) >>> a [1, 2, 3, 4] >>> b [1, 2, 3, 4] >>> id(a) #4435060856 >>> id(b) #4435060856
代码中,b变量append(4),对a变量也是影响的。输出他们的内存地址,还是指向同个内存地址。
总结:
1、对于不可变类型,无论创建多少个不可变类型,只要值相同,都指向同个内存地址(若值不同,那么一定指向不同的内存地址)。
2、对于可变类型,无论创建多少个可变类型,只要值相同,都不指向同个内存地址(除非进行复制操作,那么他们将会指向同一个地址)。
Python是如何进行类型转换的?

-
列举常见的内置函数?
作用域相关
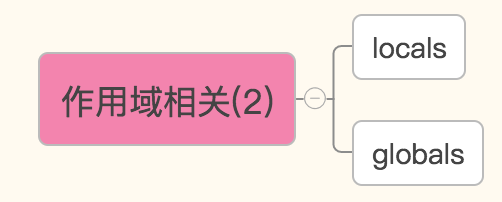
基于字典的形式获取局部变量和全局变量
globals()——获取全局变量的字典
locals()——获取执行本方法所在命名空间内的局部变量的字典
其他
字符串类型代码的执行
http://www.cnblogs.com/Eva-J/articles/7266087.html
输入输出相关:
input() 输入
s = input("请输入内容 : ") #输入的内容赋值给s变量
print(s) #输入什么打印什么。数据类型是str
print() 输出

f = open('tmp_file','w')
print(123,456,sep=',',file = f,flush=True)
# 打印进度条
import time
for i in range(0,101,2):
time.sleep(0.1)
char_num = i//2 #打印多少个'*'
per_str = '\r%s%% : %s\n' % (i, '*' * char_num) if i == 100 else '\r%s%% : %s'%(i,'*'*char_num)
print(per_str,end='', flush=True)
#小越越 : \r 可以把光标移动到行首但不换行
数据类型相关:
type(o) 返回变量o的数据类型
内存相关:
id(o) o是参数,返回一个变量的内存地址
hash(o) o是参数,返回一个可hash变量的哈希值,不可hash的变量被hash之后会报错。
t = (1,2,3) l = [1,2,3] print(hash(t)) #可hash print(hash(l)) #会报错 ''' 结果: TypeError: unhashable type: 'list' '''
*每一次执行程序,内容相同的变量hash值在这一次执行过程中不会发生改变。
文件操作相关
open() 打开一个文件,返回一个文件操作符(文件句柄)
操作文件的模式有r,w,a,r+,w+,a+ 共6种,每一种方式都可以用二进制的形式操作(rb,wb,ab,rb+,wb+,ab+)
可以用encoding指定编码.
模块操作相关
__import__导入一个模块
import time
os = __import__('os')
print(os.path.abspath('.'))
帮助方法
在控制台执行help()进入帮助模式。可以随意输入变量或者变量的类型。输入q退出
或者直接执行help(o),o是参数,查看和变量o有关的操作。。。
和调用相关
callable(o),o是参数,看这个变量是不是可调用。
如果o是一个函数名,就会返回True
callable实例
def func():pass print(callable(func)) #参数是函数名,可调用,返回True print(callable(123)) #参数是数字,不可调用,返回False
查看参数所属类型的所有内置方法
dir() 默认查看全局空间内的属性,也接受一个参数,查看这个参数内的方法或变量
查看某变量/数据类型的内置方法
print(dir(list)) #查看列表的内置方法 print(dir(int)) #查看整数的内置方法
和数字相关
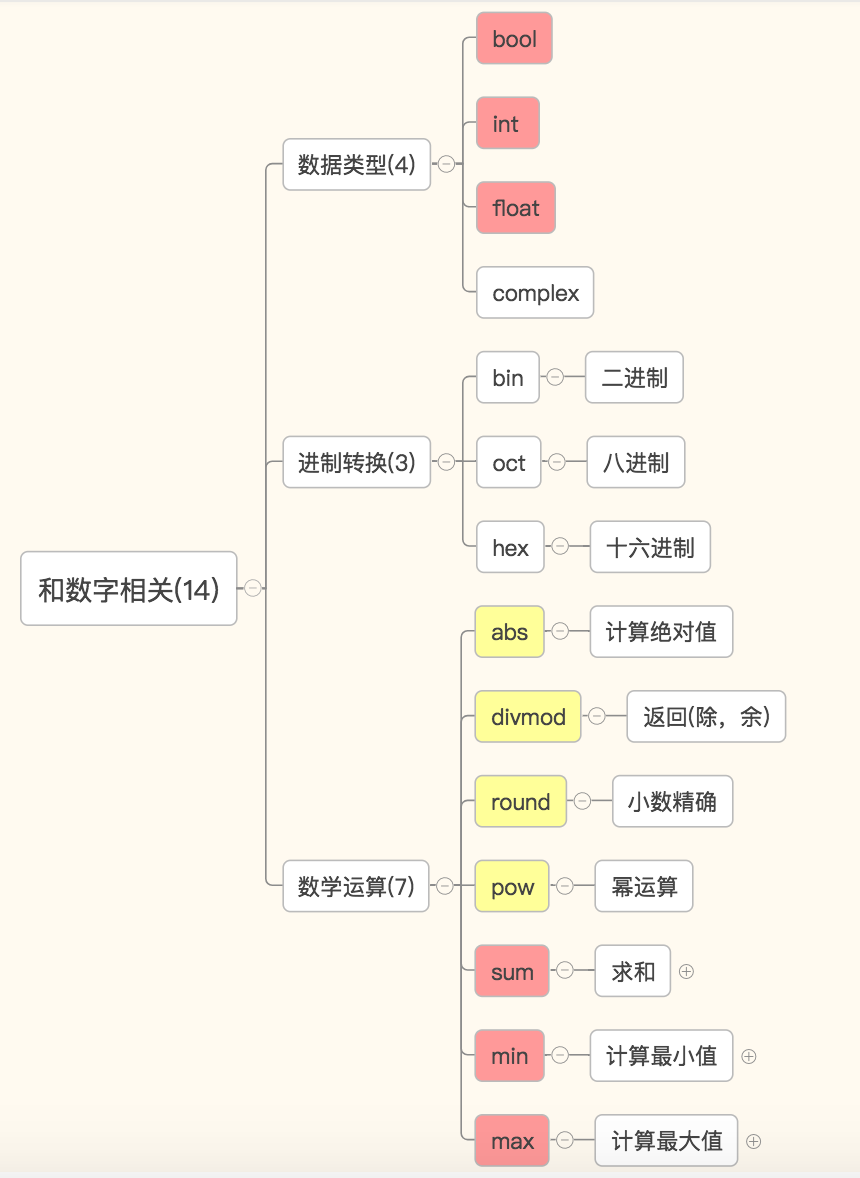
数字——数据类型相关:bool,int,float,complex
数字——进制转换相关:bin,oct,hex
数字——数学运算:abs,divmod,min,max,sum,round,pow
和数据结构相关
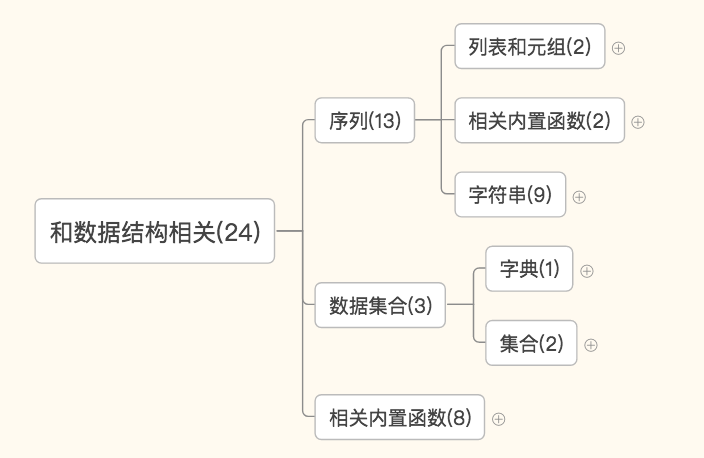
序列——列表和元组相关的:list和tuple
序列——字符串相关的:str,format,bytes,bytearry,memoryview,ord,chr,ascii,repr
bytearray
ret = bytearray('alex',encoding='utf-8')
print(id(ret))
print(ret[0])
ret[0] = 65
print(ret)
print(id(ret))
memoryview
ret = memoryview(bytes('你好',encoding='utf-8'))
print(len(ret))
print(bytes(ret[:3]).decode('utf-8'))
print(bytes(ret[3:]).decode('utf-8'))
序列:reversed,slice
reversed
l = (1,2,23,213,5612,342,43) print(l) print(list(reversed(l)))
slice
l = (1,2,23,213,5612,342,43) sli = slice(1,5,2) print(l[sli])
数据集合——字典和集合:dict,set,frozenset
数据集合:len,sorted,enumerate,all,any,zip,filter,map
filter
filter()函数接收一个函数 f 和一个list,这个函数 f 的作用是对每个元素进行判断,返回 True或 False,filter()根据判断结果自动过滤掉不符合条件的元素,返回由符合条件元素组成的新list。
例如,要从一个list [1, 4, 6, 7, 9, 12, 17]中删除偶数,保留奇数,首先,要编写一个判断奇数的函数:
def is_odd(x):
return x % 2 == 1
然后,利用filter()过滤掉偶数:
>>>filter(is_odd, [1, 4, 6, 7, 9, 12, 17])
结果:
[1, 7, 9, 17]
利用filter(),可以完成很多有用的功能,例如,删除 None 或者空字符串:
def is_not_empty(s):
return s and len(s.strip()) > 0
>>>filter(is_not_empty, ['test', None, '', 'str', ' ', 'END'])
结果:
['test', 'str', 'END']
注意: s.strip(rm) 删除 s 字符串中开头、结尾处的 rm 序列的字符。
当rm为空时,默认删除空白符(包括'\n', '\r', '\t', ' '),如下:
>>> a = ' 123'
>>> a.strip()
'123'
>>> a = '\t\t123\r\n'
>>> a.strip()
'123'
map
Python中的map函数应用于每一个可迭代的项,返回的是一个结果list。如果有其他的可迭代参数传进来,map函数则会把每一个参数都以相应的处理函数进行迭代处理。map()函数接收两个参数,一个是函数,一个是序列,map将传入的函数依次作用到序列的每个元素,并把结果作为新的list返回。
有一个list, L = [1,2,3,4,5,6,7,8],我们要将f(x)=x^2作用于这个list上,那么我们可以使用map函数处理。
>>> L = [1,2,3,4,] >>> def pow2(x): ... return x*x ... >>> map(pow2,L) [1, 4, 9, 16]
sorted方法:
对给定的List L进行排序,
方法1.用List的成员函数sort进行排序,在本地进行排序,不返回副本
方法2.用built-in函数sorted进行排序(从2.4开始),返回副本,原始输入不变
--------------------------------sorted---------------------------------------
sorted(iterable, key=None, reverse=False)
Return a new list containing all items from the iterable in ascending order.
A custom key function can be supplied to customise the sort order, and the
reverse flag can be set to request the result in descending order.
-----------------------------------------------------------------------------
参数说明:
iterable:是可迭代类型;
key:传入一个函数名,函数的参数是可迭代类型中的每一项,根据函数的返回值大小排序;
reverse:排序规则. reverse = True 降序 或者 reverse = False 升序,有默认值。
返回值:有序列表
列表按照绝对值排序
l1 = [1,3,5,-2,-4,-6] l2 = sorted(l1,key=abs) print(l1) print(l2)
列表按照每一个元素的len排序
列表按照每一个元素的长度排序
l = [[1,2],[3,4,5,6],(7,),'123'] print(sorted(l,key=len))
请务必重点掌握:
其他:input,print,type,hash,open,import,dir
str类型代码执行:eval,exec
数字:bool,int,float,abs,divmod,min,max,sum,round,pow
序列——列表和元组相关的:list和tuple
序列——字符串相关的:str,bytes,repr
序列:reversed,slice
数据集合——字典和集合:dict,set,frozenset
数据集合:len,sorted,enumerate,zip,filter,map
-
filter、map、reduce的作用?
通俗的说..都是用在一堆数据(比如一个列表)上..
map是用同样方法把所有数据都改成别的..字面意思是映射..比如把列表的每个数都换成其平方..
reduce是用某种方法依次把所有数据丢进去最后得到一个结果..字面意思是化简..比如计算一个列表所有数的和的过程,就是维持一个部分和然后依次把每个数加进去..
filter是筛选出其中满足某个条件的那些数据..字面意思是过滤..比如挑出列表中所有奇数..
>>> map(lambda x:x*x,[0,1,2,3,4,5,6]) [0, 1, 4, 9, 16, 25, 36] >>> reduce(lambda x,y:x+y,[0,1,2,3,4,5,6]) 21 >>> filter(lambda x:x&1,[0,1,2,3,4,5,6]) [1, 3, 5]
-
-
一行代码实现9*9乘法表
-
print ('\n'.join([' '.join(['%s*%s=%-2s' % (y,x,x*y) for y in range(1,x+1)]) for x in range(1,10)]))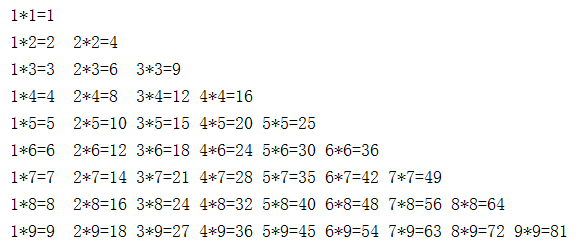
-
如何安装第三方模块?以及用过哪些第三方模块?
-
在Python中,安装第三方模块,是通过setuptools这个工具完成的。Python有两个封装了setuptools的包管理工具:easy_install和pip。目前官方推荐使用pip
如果你正在使用Mac或Linux,安装pip本身这个步骤就可以跳过了。
如果你正在使用Windows,确保安装时勾选了pip和Add python.exe to Path。
在命令提示符窗口下尝试运行pip,如果Windows提示未找到命令,可以重新运行安装程序添加pip。
现在,让我们来安装一个第三方库——Python Imaging Library,这是Python下非常强大的处理图像的工具库。一般来说,第三方库都会在Python官方的pypi.python.org网站注册,要安装一个第三方库,必须先知道该库的名称,可以在官网或者pypi上搜索,比如Python Imaging Library的名称叫PIL,因此,安装Python Imaging Library的命令就是:
pip install PIL
耐心等待下载并安装后,就可以使用PIL了。
有了PIL,处理图片易如反掌。随便找个图片生成缩略图:
>>> import Image >>> im = Image.open('test.png') >>> print im.format, im.size, im.mode PNG (400, 300) RGB >>> im.thumbnail((200, 100)) >>> im.save('thumb.jpg', 'JPEG')
其他常用的第三方库还有MySQL的驱动:MySQL-python,用于科学计算的NumPy库:numpy,用于生成文本的模板工具Jinja2,等等。
模块搜索路径
当我们试图加载一个模块时,Python会在指定的路径下搜索对应的.py文件,如果找不到,就会报错:
>>> import mymodule Traceback (most recent call last): File "<stdin>", line 1, in <module> ImportError: No module named mymodule
默认情况下,Python解释器会搜索当前目录、所有已安装的内置模块和第三方模块,搜索路径存放在sys模块的path变量中:
>>> import sys >>> sys.path ['', '/Library/Python/2.7/site-packages/pycrypto-2.6.1-py2.7-macosx-10.9-intel.egg', '/Library/Python/2.7/site-packages/PIL-1.1.7-py2.7-macosx-10.9-intel.egg', ...]
如果我们要添加自己的搜索目录,有两种方法:
一是直接修改sys.path,添加要搜索的目录:
这种方法是在运行时修改,运行结束后失效。
第二种方法是设置环境变量PYTHONPATH,该环境变量的内容会被自动添加到模块搜索路径中。设置方式与设置Path环境变量类似。注意只需要添加你自己的搜索路径,Python自己本身的搜索路径不受影响。
-
至少列举8个常用模块都有那些?
1、Django
2、pip
3、pillow-python
4、pygame
5、pyMysql
6、pytz
7、opencv-python
8、numpy
-
re的match和search区别?
-
-
1、match()函数只检测RE是不是在string的开始位置匹配,search()会扫描整个string查找匹配;
-
2、也就是说match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回none。
3、例如:import re print(re.match('super', 'superstition').span()) # (0,5) print(re.match('super', 'insuperable')) # None4、search()会扫描整个字符串并返回第一个成功的匹配:
例如:import re print(re.search('super', 'superstition').span()) #(0,5) print(re.search('super', 'insuperable')) # <_sre.SRE_Match object; span=(2, 7), match='super'>5、其中span函数定义如下,返回位置信息:
span([group]):
返回(start(group), end(group))。
-
-
什么是正则的贪婪匹配?
1、贪婪匹配
总是尝试匹配尽可能多的字符
2、非贪婪匹配
是尝试匹配尽可能少的字符
import re
secret_code = 'hadkfalifexxIxxfasdjifja134xxlovexx23345sdfxxyouxx8dfse'
b = re.findall('xx.*xx',secret_code) # 贪婪匹配
print (b) # ['xxIxxfasdjifja134xxlovexx23345sdfxxyouxx']
c = re.findall('xx.*?xx',secret_code) # 非贪婪匹配
print(c) # ['xxIxx', 'xxlovexx', 'xxyouxx']
贪婪格式:xx.*xx
非贪婪格式:xx.*?xx
区别重点在:.* 和 .*?
Python里面如何实现tuple和list的转换
-
- #From list to Tuple
- tuple(a_list)
- #From Tuple to List
- def to_list(t):
- return [i if not isinstance(i,tuple) else to_list(i) for i in t]
-
def func(a,b=[]) 这种写法有什么坑?
那我们先通过程序看看这个函数有什么坑吧!
def func(a,b=[]):
b.append(a)
print(b)
func(1)
func(1)
func(1)
func(1)
看下结果
[1]
[1, 1]
[1, 1, 1]
[1, 1, 1, 1]
函数的第二个默认参数是一个list,当第一次执行的时候实例化了一个list,第二次执行还是用第一次执行的时候实例化的地址存储,所以三次执行的结果就是 [1, 1, 1] ,想每次执行只输出[1] ,默认参数应该设置为None。
-
如何实现 “1,2,3” 变成 [‘1’,’2’,’3’] ?
"1,2,3".split(',')
"1,2,3".split(',')
-
如何实现[‘1’,’2’,’3’]变成[1,2,3] ?
a=['1','2','3'] b=[int(i) for i in a] print(b)
输出为:[1, 2, 3]
-
比较: a = [1,2,3] 和 b = [(1),(2),(3) ] 以及 b = [(1,),(2,),(3,) ] 的区别?
-
如何用一行代码生成[1,4,9,16,25,36,49,64,81,100] ?
y = [x*x for x in range (1,11)]
print(y)
输出为:[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
方法二:
[i*i for i in range(11)]
输出为:[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
-
一行代码实现删除列表中重复的值 ?
使用set()方法!
list0=['b','c', 'd','b','c','a','a'] print(sorted(set(list0),key=list0.index)) # sorted output
-
如何在函数中设置一个全局变量 ?
在函数的内部,通过global声明,使在函数内部中设置一个全局变量,这个全局变量可以在任意的函数中进行调用!
SOLR_URL='http://solr.org'
def tt():
global SOLR_URL
SOLR_URL=SOLR_URL+'#aa'
def aa():
if __name__=='__main__':
tt()
print(SOLR_URL)
aa() # http://solr.org#aa
-
logging模块的作用?以及应用场景?
通过log的分析,可以方便用户了解系统或软件、应用的运行情况;如果你的应用log足够丰富,也可以分析以往用户的操作行为、类型喜好、地域分布或其他更多信息;如果一个应用的log同时也分了多个级别,那么可以很轻易地分析得到该应用的健康状况,及时发现问题并快速定位、解决问题,补救损失。
简单来讲就是,我们通过记录和分析日志可以了解一个系统或软件程序运行情况是否正常,也可以在应用程序出现故障时快速定位问题。比如,做运维的同学,在接收到报警或各种问题反馈后,进行问题排查时通常都会先去看各种日志,大部分问题都可以在日志中找到答案。再比如,做开发的同学,可以通过IDE控制台上输出的各种日志进行程序调试。对于运维老司机或者有经验的开发人员,可以快速的通过日志定位到问题的根源。可见,日志的重要性不可小觑。日志的作用可以简单总结为以下3点:
- 程序调试
- 了解软件程序运行情况,是否正常
- 软件程序运行故障分析与问题定位
如果应用的日志信息足够详细和丰富,还可以用来做用户行为分析,如:分析用户的操作行为、类型洗好、地域分布以及其它更多的信息,由此可以实现改进业务、提高商业利益。
logging模块默认定义了以下几个日志等级,它允许开发人员自定义其他日志级别,但是这是不被推荐的,尤其是在开发供别人使用的库时,因为这会导致日志级别的混乱。
| 日志等级(level) | 描述 |
|---|---|
| DEBUG | 最详细的日志信息,典型应用场景是 问题诊断 |
| INFO | 信息详细程度仅次于DEBUG,通常只记录关键节点信息,用于确认一切都是按照我们预期的那样进行工作 |
| WARNING | 当某些不期望的事情发生时记录的信息(如,磁盘可用空间较低),但是此时应用程序还是正常运行的 |
| ERROR | 由于一个更严重的问题导致某些功能不能正常运行时记录的信息 |
| CRITICAL | 当发生严重错误,导致应用程序不能继续运行时记录的信息 |
开发应用程序或部署开发环境时,可以使用DEBUG或INFO级别的日志获取尽可能详细的日志信息来进行开发或部署调试;应用上线或部署生产环境时,应该使用WARNING或ERROR或CRITICAL级别的日志来降低机器的I/O压力和提高获取错误日志信息的效率。日志级别的指定通常都是在应用程序的配置文件中进行指定的。
说明:
- 上面列表中的日志等级是从上到下依次升高的,即:DEBUG < INFO < WARNING < ERROR < CRITICAL,而日志的信息量是依次减少的;
- 当为某个应用程序指定一个日志级别后,应用程序会记录所有日志级别大于或等于指定日志级别的日志信息,而不是仅仅记录指定级别的日志信息,nginx、php等应用程序以及这里要提高的python的logging模块都是这样的。同样,logging模块也可以指定日志记录器的日志级别,只有级别大于或等于该指定日志级别的日志记录才会被输出,小于该等级的日志记录将会被丢弃。
- 可以参考该人的博客:https://www.cnblogs.com/yyds/p/6901864.html
-
请用代码简答实现stack 。
栈和队列是两种基本的数据结构,同为容器类型。两者根本的区别在于:
stack:后进先出
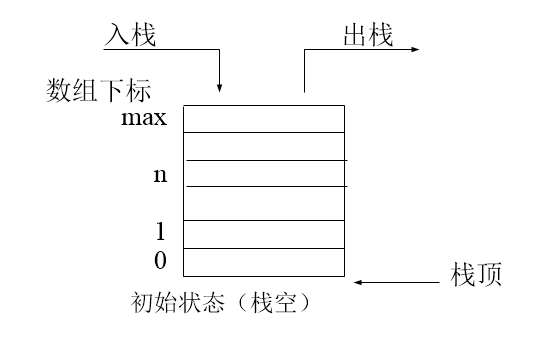
queue:先进先出

PS:stack和queue是不能通过查询具体某一个位置的元素而进行操作的。但是他们的排列是按顺序的
对于stack我们可以使用python内置的list实现,因为list是属于线性数组,在末尾插入和删除一个元素所使用的时间都是O(1),这非常符合stack的要求。当然,我们也可以使用链表来实现。
stack的实现代码(使用python内置的list),实现起来是非常的简单,就是list的一些常用操作
class Stack(object):
def __init__(self):
self.stack = []
def push(self, value): # 进栈
self.stack.append(value)
def pop(self): #出栈
if self.stack:
self.stack.pop()
else:
raise LookupError('stack is empty!')
def is_empty(self): # 如果栈为空
return bool(self.stack)
def top(self):
#取出目前stack中最新的元素
return self.stack[-1]
我们定义如下的链表来实现队列数据结构:
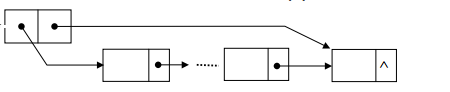
定义一个头结点,左边指向队列的开头,右边指向队列的末尾,这样就可以保证我们插入一个元素和取出一个元素都是O(1)的操作,使用这种链表实现stack也是非常的方便。实现代码如下:
class Head(object):
def __init__(self):
self.left = None
self.right = None
class Node(object):
def __init__(self, value):
self.value = value
self.next = None
class Queue(object):
def __init__(self):
#初始化节点
self.head = Head()
def enqueue(self, value):
#插入一个元素
newnode = Node(value)
p = self.head
if p.right:
#如果head节点的右边不为None
#说明队列中已经有元素了
#就执行下列的操作
temp = p.right
p.right = newnode
temp.next = newnode
else:
#这说明队列为空,插入第一个元素
p.right = newnode
p.left = newnode
def dequeue(self):
#取出一个元素
p = self.head
if p.left and (p.left == p.right):
#说明队列中已经有元素
#但是这是最后一个元素
temp = p.left
p.left = p.right = None
return temp.value
elif p.left and (p.left != p.right):
#说明队列中有元素,而且不止一个
temp = p.left
p.left = temp.next
return temp.value
else:
#说明队列为空
#抛出查询错误
raise LookupError('queue is empty!')
def is_empty(self):
if self.head.left:
return False
else:
return True
def top(self):
#查询目前队列中最早入队的元素
if self.head.left:
return self.head.left.value
else:
raise LookupError('queue is empty!')
-
常用字符串格式化哪几种?
Python的字符串格式化常用的有三种!-
第一种:最方便的
缺点:需一个个的格式化
print('hello %s and %s'%('df','another df'))
第二种:最好用的
优点:不需要一个个的格式化,可以利用字典的方式,缩短时间
print('hello %(first)s and %(second)s'%{'first':'df' , 'second':'another df'})
第三种:最先进的
优点:可读性强
print('hello {first} and {second}'.format(first='df',second='another df'))
-
简述 生成器、迭代器、可迭代对象 以及应用场景?
迭代器:是访问集合元素的一种方式,从集合的第一个元素开始访问,直到所有元素被访问结束。其优点是不需要事先准备好整个迭代过程中的所有元素,仅在迭代到某个元素时才开始计算该元素。适合遍历比较巨大的集合。__iter__():方法返回迭代器本身, __next__():方法用于返回容器中下一个元素或数据。
生成器:带有yield的函数不再是一个普通函数,而是一个生成器。当函数被调用时,返回一个生成器对象。不像一般函数在生成值后退出,生成器函数在生成值后会自动挂起并暂停他们的执行状态。
'''迭代器'''
print('for x in iter([1, 2, 3, 4, 5]):') for x in iter([1, 2, 3, 4, 5]): print(x) '''生成器''' def myyield(n): while n>0: print("开始生成...:") yield n print("完成一次...:") n -= 1 for i in myyield(4): print("遍历得到的值:",i)
-
用Python实现一个二分查找的函数
data = [1, 3, 6, 7, 9, 12, 14, 16, 17, 18, 20, 21, 22, 23, 30, 32, 33, 35]
def binary_search(dataset,find_num):
if len(dataset) > 1:
mid = int(len(dataset) / 2)
if dataset[mid] == find_num: # find it
print("找到数字", dataset[mid])
elif dataset[mid] > find_num: # 找的数在mid左面
print("\033[31;1m找的数在mid[%s]左面\033[0m" % dataset[mid])
return binary_search(dataset[0:mid], find_num)
else: # 找的数在mid右面
print("\033[32;1m找的数在mid[%s]右面\033[0m" % dataset[mid])
return binary_search(dataset[mid + 1:], find_num)
else:
if dataset[0] == find_num: # find it
print("找到数字啦", dataset[0])
else:
print("没的分了,要找的数字[%s]不在列表里" % find_num)
binary_search(data,20)

-
谈谈你对闭包的理解?
再说说闭包之前,先说一说什么是外函数,什么是内函数?
外函数:函数A的内部定义了函数B,那么函数A就叫做外函数
内函数:函数B就叫做内函数
什么是闭包?
在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用。这样就构成了一个闭包。

一般情况下,在我们认知当中,如果一个函数结束,函数的内部所有东西都会释放掉,还给内存,局部变量都会消失。但是闭包是一种特殊情况,如果外函数在结束的时候发现有自己的临时变量将来会在内部函数中用到,就把这个临时变量绑定给了内部函数,然后自己再结束。
def outer(a):
b = 10
def inner():
print(a+b)
return inner
if __name__ == '__main__':
demo = outer(5)
demo()
demo2 = outer(7)
demo2()
-
os和sys模块的作用?
ys模块主要是用于提供对python解释器相关的操作
函数
- sys.argv #命令行参数List,第一个元素是程序本身路径
- sys.path #返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
- sys.modules.keys() #返回所有已经导入的模块列表
- sys.modules #返回系统导入的模块字段,key是模块名,value是模块
- sys.exc_info() #获取当前正在处理的异常类,exc_type、exc_value、exc_traceback当前处理的异常详细信息
- sys.exit(n) #退出程序,正常退出时exit(0)
- sys.hexversion #获取Python解释程序的版本值,16进制格式如:0x020403F0
- sys.version #获取Python解释程序的版本信息
- sys.platform #返回操作系统平台名称
- sys.maxint # 最大的Int值
- sys.stdout #标准输出
- sys.stdout.write('aaa') #标准输出内容
- sys.stdout.writelines() #无换行输出
- sys.stdin #标准输入
- sys.stdin.read() #输入一行
- sys.stderr #错误输出
- sys.exc_clear() #用来清除当前线程所出现的当前的或最近的错误信息
- sys.exec_prefix #返回平台独立的python文件安装的位置
- sys.byteorder #本地字节规则的指示器,big-endian平台的值是'big',little-endian平台的值是'little'
- sys.copyright #记录python版权相关的东西
- sys.api_version #解释器的C的API版本
- sys.version_info #'final'表示最终,也有'candidate'表示候选,表示版本级别,是否有后继的发行
- sys.getdefaultencoding() #返回当前你所用的默认的字符编码格式
- sys.getfilesystemencoding() #返回将Unicode文件名转换成系统文件名的编码的名字
- sys.builtin_module_names #Python解释器导入的内建模块列表
- sys.executable #Python解释程序路径
- sys.getwindowsversion() #获取Windows的版本
- sys.stdin.readline() #从标准输入读一行,sys.stdout.write(
a
) 屏幕输出a - sys.setdefaultencoding(name) #用来设置当前默认的字符编码(详细使用参考文档)
- sys.displayhook(value) #如果value非空,这个函数会把他输出到sys.stdout(详细使用参考文档)
常用功能
sys.arg 获取位置参数
print(sys.argv)
执行该脚本,加参数的打印结果
python3 m_sys.py 1 2 3 4 5
['m_sys.py', '1', '2', '3', '4', '5']
可以发现 sys.arg返回的是整个位置参数,类似于shell的$0 $1...
sys.exit(n) 程序退出,n是退出是返回的对象
sys.version 获取python版本
>>> sys.version
'3.5.1 (v3.5.1:37a07cee5969, Dec 5 2015, 21:12:44) \n[GCC 4.2.1 (Apple Inc. build 5666) (dot 3)]'
sys.path 返回模块的搜索路径列表,可通过添加自定义路径,来添加自定义模块
>>> sys.path
['', '/Library/Frameworks/Python.framework/Versions/3.5/lib/python35.zip', '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5', '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/plat-darwin', '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/lib-dynload', '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages']
sys.platform 返回当前系统平台 linux平台返回linux,windows平台返回win32,MAC返回darwin
>>> sys.platform
'darwin
sys.stdout.write() 输出内容
>>> sys.stdout.write('asd')
asd3
>>> sys.stdout.write('asd')
asd3
>>> sys.stdout.write('as')
as2
应用:
进度条:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
#pyversion:python3.5
#owner:fuzj
"""
sys 和python解析器相关
"""
import sys
import time
def view_bar(num,total):
rate = num / total
rate_num = int(rate * 100)
#r = '\r %d%%' %(rate_num)
r = '\r%s>%d%%' % ('=' * rate_num, rate_num,)
sys.stdout.write(r)
sys.stdout.flush
if __name__ == '__main__':
for i in range(0, 101):
time.sleep(0.1)
view_bar(i, 100)
效果:
====================================================================================================>100%
os模块
OS模块是Python标准库中的一个用于访问操作系统功能的模块,使用OS模块中提供的接口,可以实现跨平台访问
用于提供系统级别的操作
- os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
- os.chdir(
dirname
) 改变当前脚本工作目录;相当于shell下cd - os.curdir 返回当前目录: ('.')
- os.pardir 获取当前目录的父目录字符串名:('..')
- os.makedirs('dir1/dir2') 可生成多层递归目录
- os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
- os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
- os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
- os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
- os.remove() 删除一个文件
- os.rename(
oldname
,new
) 重命名文件/目录 - os.stat('path/filename') 获取文件/目录信息
- os.sep 操作系统特定的路径分隔符,win下为
\
,Linux下为/
- os.linesep 当前平台使用的行终止符,win下为
\t\n
,Linux下为\n
- os.pathsep 用于分割文件路径的字符串
- os.name 字符串指示当前使用平台。win->'nt'; Linux->'posix'
- os.system(
bash command
) 运行shell命令,直接显示 - os.environ 获取系统环境变量
- os.path.abspath(path) 返回path规范化的绝对路径
- os.path.split(path) 将path分割成目录和文件名二元组返回
- os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
- os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
- os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
-
os.path.lexists #路径存在则返回True,路径损坏也返回True
- os.path.isabs(path) 如果path是绝对路径,返回True
- os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
- os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
- os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
- os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
- os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
- os.path.commonprefix(list) #返回list(多个路径)中,所有path共有的最长的路径。
-
os.path.expanduser(path) #把path中包含的"~"和"~user"转换成用户目录
- os.path.expandvars(path) #根据环境变量的值替换path中包含的”$name”和”${name}”
- os.access('pathfile',os.W_OK) 检验文件权限模式,输出True,False
- os.chmod('pathfile',os.W_OK) 改变文件权限模式
-
如何生成一个随机数?
答:random模块
随机整数:random.randint(a,b):返回随机整数x,a<=x<=b
random.randrange(start,stop,[,step]):返回一个范围在(start,stop,step)之间的随机整数,不包括结束值。
随机实数:random.random( ):返回0到1之间的浮点数
random.uniform(a,b):返回指定范围内的浮点数。
import random # 随机模块 data = list(range(10)) print(data) # 打印有序的列表 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] random.shuffle(data) # 使有序变为无序 print(data) # 打印无序的列表 [4, 2, 5, 1, 6, 3, 9, 8, 0, 7]
-
如何使用python删除一个文件?
若想利用python删除windows里的文件,这里需要使用os模块!那接下来就看看利用os模块是如何删除文件的!
具体实现方法如下!
os.remove(path)
删除文件 path. 如果path是一个目录, 抛出 OSError错误。如果要删除目录,请使用rmdir().
remove() 同 unlink() 的功能是一样的
在Windows系统中,删除一个正在使用的文件,将抛出异常。在Unix中,目录表中的记录被删除,但文件的存储还在。
import os
my_file = 'D:/text.txt' # 文件路径
if os.path.exists(my_file): # 如果文件存在
#删除文件,可使用以下两种方法。
os.remove(my_file) # 则删除
#os.unlink(my_file)
else:
print('no such file:%s'%my_file)
os.removedirs(path)
递归地删除目录。类似于rmdir(), 如果子目录被成功删除, removedirs() 将会删除父目录;但子目录没有成功删除,将抛出错误。
例如, os.removedirs(“foo/bar/baz”) 将首先删除baz目录,然后再删除bar和 foo, 如果他们是空的话,则子目录不能成功删除,将抛出 OSError异常
os.rmdir(path)
删除目录 path,要求path必须是个空目录,否则抛出OSError错误
import os
for root, dirs, files in os.walk(top, topdown=False):
for name in files:
os.remove(os.path.join(root, name))
for name in dirs:
os.rmdir(os.path.join(root, name))
方法2:
代码如下:
import shutil shutil.rmtree()
-
谈谈你对面向对象的理解?
什么是封装?
所谓的面向对象就是将我们的程序模块化,对象化,把具体事物的特性属性和通过这些属性来实现一些动作的具体方法放到一个类里面,这就是封装。封装是我们所说的面相对象编程的特征之一。除此之外还有继承和多态。
什么是继承?
继承有点类似与我们生物学上的遗传,就是子类的一些特征是来源于父类的,儿子遗传了父亲或母亲的一些性格,或者相貌,又或者是运动天赋。有点种瓜得瓜种豆得豆的意思。面向对象里的继承也就是父类的相关的属性,可以被子类重复使用,子类不必再在自己的类里面重新定义一回,父类里有点我们只要拿过来用就好了。而对于自己类里面需要用到的新的属性和方法,子类就可以自己来扩展了。
什么是多态?
我们在有一些方法在父类已经定义好了,但是子类我们自己再用的时候,发现,其实,我们的虽然都是计算工资的,但是普通员工的工资计算方法跟经理的计算方法是不一样的,所以这个时候,我们就不能直接调用父类的这个计算工资的方法了。这个时候我们就需要用到面向对象的另一个特性,多态。我们要在子类里面把父类里面定义计算工资的方法在子类里面重新实现一遍。多态包含了重载和重写。
什么是重写?
重写很简单就是把子类从父亲类里继承下来的方法重新写一遍,这样,父类里相同的方法就被覆盖了,当然啦,你还是可以通过super.CaculSalary方法来调用父类的工资计算方法。
什么是重载?
重载就是类里面相同方法名,不同形参的情况,可以是形参类型不同或者形参个数不同,或者形参顺序不同,但是不能使返回值类型不同。
-
Python面向对象中的继承有什么特点?
继承的优点:
1、建造系统中的类,避免重复操作。
2、新类经常是基于已经存在的类,这样就可以提升代码的复用程度。
继承的特点:
1、在继承中基类的构造(__init__()方法)不会被自动调用,它需要在其派生类的构造中亲自专门调用。有别于C#
2、在调用基类的方法时,需要加上基类的类名前缀,且需要带上self参数变量。区别于在类中调用普通函数时并不需要带上self参数
3、Python总是首先查找对应类型的方法,如果它不能在派生类中找到对应的方法,它才开始到基类中逐个查找。(先在本类中查找调用的方法,找不到才去基类中找)。
-
面向对象深度优先和广度优先是什么?
-
面向对象中super的作用?
什么是super?
super() 函数是用于调用父类(超类)的一个方法。
super 是用来解决多重继承问题的,直接用类名调用父类方法在使用单继承的时候没问题,但是如果使用多继承,会涉及到查找顺序(MRO)、重复调用(钻石继承)等种种问题。
MRO 就是类的方法解析顺序表, 其实也就是继承父类方法时的顺序表。
语法
以下是 super() 方法的语法:
super(type[, object-or-type])
参数
·type -- 类。
·object-or-type -- 类,一般是 self
Python3.x 和 Python2.x 的一个区别是: Python 3 可以使用直接使用 super().xxx 代替 super(Class, self).xxx :
Python3.x 实例:
class A:
pass
class B(A):
def add(self, x):
super().add(x)
Python2.x 实例:
class A(object): # Python2.x 记得继承 object
pass
class B(A):
def add(self, x):
super(B, self).add(x)
具体应用示例:
举个例子
class Foo:
def bar(self, message):
print(message)
>>> Foo().bar("Hello, Python.")
Hello, Python.
当存在继承关系的时候,有时候需要在子类中调用父类的方法,此时最简单的方法是把对象调用转换成类调用,需要注意的是这时self参数需要显式传递,例如:
class FooParent:
def bar(self, message):
print(message)
class FooChild(FooParent):
def bar(self, message):
FooParent.bar(self, message)
>>> FooChild().bar("Hello, Python.")
Hello, Python.
这样做有一些缺点,比如说如果修改了父类名称,那么在子类中会涉及多处修改,另外,Python是允许多继承的语言,如上所示的方法在多继承时就需要重复写多次,显得累赘。为了解决这些问题,Python引入了super()机制,例子代码如下:
class FooParent:
def bar(self, message):
print(message)
class FooChild(FooParent):
def bar(self, message):
super(FooChild, self).bar(message)
>>> FooChild().bar("Hello, Python.")
Hello, Python
表面上看 super(FooChild, self).bar(message)方法和FooParent.bar(self, message)方法的结果是一致的,实际上这两种方法的内部处理机制大大不同,当涉及多继承情况时,就会表现出明显的差异来,直接给例子:
代码一:
class A:
def __init__(self):
print("Enter A")
print("Leave A")
class B(A):
def __init__(self):
print("Enter B")
A.__init__(self)
print("Leave B")
class C(A):
def __init__(self):
print("Enter C")
A.__init__(self)
print("Leave C")
class D(A):
def __init__(self):
print("Enter D")
A.__init__(self)
print("Leave D")
class E(B, C, D):
def __init__(self):
print("Enter E")
B.__init__(self)
C.__init__(self)
D.__init__(self)
print("Leave E")
E()
结果为:
Enter E
Enter B
Enter A
Leave A
Leave B
Enter C
Enter A
Leave A
Leave C
Enter D
Enter A
Leave A
Leave D
Leave E
执行顺序很好理解,唯一需要注意的是公共父类A被执行了多次。
代码二:
class A:
def __init__(self):
print("Enter A")
print("Leave A")
class B(A):
def __init__(self):
print("Enter B")
super(B, self).__init__()
print("Leave B")
class C(A):
def __init__(self):
print("Enter C")
super(C, self).__init__()
print("Leave C")
class D(A):
def __init__(self):
print("Enter D")
super(D, self).__init__()
print("Leave D")
class E(B, C, D):
def __init__(self):
print("Enter E")
super(E, self).__init__()
print("Leave E")
E()
结果:
Enter E
Enter B
Enter C
Enter D
Enter A
Leave A
Leave D
Leave C
Leave B
Leave E
在super机制里可以保证公共父类仅被执行一次,至于执行的顺序,是按照MRO(Method Resolution Order):方法解析顺序 进行的。
-
是否使用过functools中的函数?其作用是什么?
functools模块介绍
functools用于高阶函数:指那些作用于函数或者返回其他函数的函数。通常情况下,只要是可以被当做函数调用的对象就是这个模块的目标。
functools模块的功能
python 中提供一种用于对函数固定属性的函数(与数学上的偏函数不一样)
# 通常会返回10进制
int('12345') # print 12345
# 使用参数 返回 8进制
int('11111', 8) # print 4681
每次都得添加参数比较麻烦, functools提供了partial的方法
import functools
foo = functools.partial(int, base=8)
foo('11111') # print 4681
通过这种方法生成一个固定参数的新函数
def int2(x, base=2): return int(x, base)
这样,我们转换二进制就非常方便了:
>>> int2('1000000')
64
>>> int2('1010101')
85
functools.partial就是帮助我们创建一个偏函数的,不需要我们自己定义int2(),可以直接使用下面的代码创建一个新的函数int2:
>>> import functools
>>> int2 = functools.partial(int, base=2)
>>> int2('1000000')
64
>>> int2('1010101')
85
所以,简单总结functools.partial的作用就是,把一个函数的某些参数给固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单。
注意到上面的新的int2函数,仅仅是把base参数重新设定默认值为2,但也可以在函数调用时传入其他值:
>>> int2('1000000', base=10)
1000000
最后,创建偏函数时,实际上可以接收函数对象、*args和**kwargs这3个参数,当传入:
int2 = functools.partial(int, base=2)
实际上固定了int()函数的关键字参数base,也就是:
int2('10010')
相当于:
kw = { 'base': 2 }
int('10010', **kwargs)
当传入:
max2 = functools.partial(max, 10)
实际上会把10作为*args的一部分自动加到左边,也就是:
max2(5, 6, 7)
相当于:
args = (10, 5, 6, 7) max(*args)
-
列举面向对象中带双下划线的特殊方法,如:__new__、__init__
__new__和__init__的区别
这个__new__确实很少见到,先做了解吧.
__new__是一个静态方法,而__init__是一个实例方法.__new__方法会返回一个创建的实例,而__init__什么都不返回.- 只有在
__new__返回一个cls的实例时后面的__init__才能被调用. - 当创建一个新实例时调用
__new__,初始化一个实例时用__init__.
-
如何判断是函数还是方法?
函数:
函数是封装了一些独立的功能,可以直接调用,python内置了许多函数,同时可以自建函数来使用。
方法:
方法和函数类似,同样封装了独立的功能,但是方法是需要通过对象来调用的,表示针对这个对象要做的操作,使用时采用点方法。
-
单例模式
-
单例模式是一种常用的软件设计模式。在它的核心结构中只包含一个被称为单例类的特殊类。通过单例模式可以保证系统中一个类只有一个实例而且该实例易于外界访问,从而方便对实例个数的控制并节约系统资源。如果希望在系统中某个类的对象只能存在一个,单例模式是最好的解决方案。
__new__()在__init__()之前被调用,用于生成实例对象。利用这个方法和类的属性的特点可以实现设计模式的单例模式。单例模式是指创建唯一对象,单例模式设计的类只能实例 这个绝对常考啊.绝对要记住1~2个方法,当时面试官是让手写的.1 使用
__new__方法class Singleton(object): def __new__(cls, *args, **kw): if not hasattr(cls, '_instance'): orig = super(Singleton, cls) cls._instance = orig.__new__(cls, *args, **kw) return cls._instance class MyClass(Singleton): a = 12 共享属性
创建实例时把所有实例的
__dict__指向同一个字典,这样它们具有相同的属性和方法.class Borg(object): _state = {} def __new__(cls, *args, **kw): ob = super(Borg, cls).__new__(cls, *args, **kw) ob.__dict__ = cls._state return ob class MyClass2(Borg): a = 13 装饰器版本
def singleton(cls): instances = {} def getinstance(*args, **kw): if cls not in instances: instances[cls] = cls(*args, **kw) return instances[cls] return getinstance @singleton class MyClass: ...4 import方法
作为python的模块是天然的单例模式
# mysingleton.py class My_Singleton(object): def foo(self): pass my_singleton = My_Singleton() # to use from mysingleton import my_singleton my_singleton.foo() -
静态方法和类方法区别?
Python 除了拥有实例方法外,还拥有静态方法和类方法,跟Java相比需要理解这个类方法的含义。
class Foo(object):
def test(self): #定义了实例方法
print("object")
@classmethod # 装饰器
def test2(clss): #定义了类方法
print("class")
@staticmethod # 装饰器
def test3(): #定义了静态方法
print("static")
实例方法访问方式:
ff=Foo() ff.test();//通过实例调用 Foo.test(ff)//直接通过类的方式调用,但是需要自己传递实例引用
类方法访问方式:
Foo.test2();
如果Foo有了子类并且子类覆盖了这个类方法,最终调用会调用子类的方法并传递的是子类的类对象。
class Foo2(Foo):
@classmethod
def test2(self):
print(self)
print("foo2 object")
f2=Foo2()
print(f2.test2())
输出结果:
<class '__main__.Foo2'>
foo2 object
None
静态方法调用方式:
Foo.test3();//直接静态方式调用
总结:
其实通过以上可以看出:
实例方法,类方法,静态方法都可以通过实例或者类调用,只不过实例方法通过类调用时需要传递实例的引用(python 3可以传递任意对象,其他版本会报错)。
三种方法从不同层次上来对方法进行了描述:实例方法针对的是实例,类方法针对的是类,他们都可以继承和重新定义,而静态方法则不能继承,可以认为是全局函数。
-
Python中单下划线和双下划线
>>> class MyClass():
... def __init__(self): ... self.__superprivate = "Hello" ... self._semiprivate = ", world!" ... >>> mc = MyClass() >>> print mc.__superprivate Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: myClass instance has no attribute '__superprivate' >>> print mc._semiprivate , world! >>> print mc.__dict__ {
'_MyClass__superprivate': 'Hello', '_semiprivate': ', world!'}
__foo__:一种约定,Python内部的名字,用来区别其他用户自定义的命名,以防冲突,就是例如__init__(),__del__(),__call__()这些特殊方法
_foo:一种约定,用来指定变量私有.程序员用来指定私有变量的一种方式.不能用from module import * 导入,其他方面和公有一样访问;
__foo:这个有真正的意义:解析器用_classname__foo来代替这个名字,以区别和其他类相同的命名,它无法直接像公有成员一样随便访问,通过对象名._类名__xxx这样的方式可以访问.
或者: http://www.zhihu.com/question/19754941
-
read,readline和readlines
- read 读取整个文件
- readline 读取下一行,使用生成器方法
- readlines 读取整个文件到一个迭代器以供我们遍历
列举面向对象中的特殊成员以及应用场景
1. __doc__ 描述类的信息
class Foo(object): # 单引号和双引号都可以 """这里描述类的信息""" def func(self): pass print(Foo.__doc__)
显示的结果:
2. __call__ 对象后面加括号,触发执行
# __call__方法的执行是由对象加括号触发的,即:对象()或者 类()()
class Foo(object):
def __call__(self, *args, **kwargs):
print("running call", args, kwargs)
foo = Foo()
foo(1, 2, 3, name = "UserPython")
Foo()(1, 2, 3, name = "UserPython")
显示的结果:
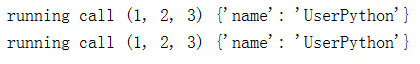
3. __dict__ 查看类或对象中的所有成员
class Foo(object):
def __init__(self, name, age):
self.name = name
self.age = age
foo = Foo("UserPython", 17)
print(Foo.__dict__) #打印类里的所有属性,不包括实例属性
print(foo.__dict__) #打印所有实例属性,不包括类属性
显示的结果:
{'__weakref__': <attribute '__weakref__' of 'Foo' objects>, '__init__': <function Foo.__init__ at 0x0000000000BB0730>, '__dict__': <attribute '__dict__' of 'Foo' objects>, '__module__': '__main__', '__doc__': None}
{'name': 'UserPython', 'age': 17}
4. __str__ 如果一个类中定义了__str__方法,那么在打印对象时,默认输出该方法的返回值
class Foo(object):
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return "<obj:%s>" % self.name
foo = Foo("UserPython", 17)
print(foo) #>>><obj:UserPython>
显示的效果为:
<obj:UserPython>
5. __getitem__ 、 __setitem__ 、__delitem__ 用于索引操作,如字典。分别表示获取、设置、删除数据
class Foo(object):
def __getitem__(self, key):
print("__getitem__", key)
def __setitem__(self, key, value):
print("__setitem__", key, value)
def __delitem__(self, key):
print("__delitem__", key)
foo = Foo()
foo["name"] = "UserPython" #>>>__setitem__ name UserPython 触发__setitem__
foo["name"] #>>>__getitem__ name 触发__getitem__
del foo["name"] #>>>__delitem__ name 触发__delitem__
显示的结果为:

6. __new__ 、__metaclass__
class Foo(object):
def __init__(self, name):
self.name = name
foo = Foo("UserPython")
'''''
上述代码中,foo是通过Foo类实例化的对象,其实,不仅foo是一个对象,Foo类本身也是一个对象,因为在Python中一切事物都是对象。
如果按照一切事物都是对象的理论:foo对象时通过执行Foo类的构造方法创建,那么Foo类对象应该也是通过执行某个类的构造方法创建。
'''
print(type(foo))
print(type(Foo))
# 所以,foo对象是Foo类的一个实例,Foo类对象是type类的一个实例,即:Foo类对象是通过type类的构造方法创建。那么,创建类就可以有两种方式了
显示的结果为:

# 普通方式
class Foo(object):
def func(self):
print("hello UserPython")
# 特殊方式
def func(self):
print("hello %s" % self.name)
def __init__(self, name, age): #构造方法
self.name = name
self.age = age
# 创建了一个type类,然后用type类实例化了一个Foo类,由于Foo本身是一个类,所以Foo又实例化了一个对象foo
Foo = type('Foo', (object, ), {"func" : func, "__init__" : __init__})
foo = Foo("UserPython", 19)
foo.func()
print(type(Foo))
显示的结果为:

-
1、2、3、4、5 能组成多少个互不相同且无重复的三位数
-
什么是反射?以及应用场景?
对编程语言比较熟悉的朋友,应该知道“反射”这个机制。Python作为一门动态语言,当然不会缺少这一重要功能。然而,在网络上却很少见到有详细或者深刻的剖析论文。下面结合一个web路由的实例来阐述python的反射机制的使用场景和核心本质。
一、前言
def f1():
print("f1是这个函数的名字!")
s = "f1"
print("%s是个字符串" % s)
在上面的代码中,我们必须区分两个概念,f1和“f1"。前者是函数f1的函数名,后者只是一个叫”f1“的字符串,两者是不同的事物。我们可以用f1()的方式调用函数f1,但我们不能用"f1"()的方式调用函数。说白了就是,不能通过字符串来调用名字看起来相同的函数!
二、web实例
考虑有这么一个场景,根据用户输入的url的不同,调用不同的函数,实现不同的操作,也就是一个url路由器的功能,这在web框架里是核心部件之一。下面有一个精简版的示例:
首先,有一个commons模块,它里面有几个函数,分别用于展示不同的页面,代码如下:
def login():
print("这是一个登陆页面!")
def logout():
print("这是一个退出页面!")
def home():
print("这是网站主页面!")
其次,有一个visit模块,作为程序入口,接受用户输入,展示相应的页面,代码如下:(这段代码是比较初级的写法)
import commons
def run():
inp = input("请输入您想访问页面的url: ").strip()
if inp == "login":
commons.login()
elif inp == "logout":
commons.logout()
elif inp == "home":
commons.home()
else:
print("404")
if __name__ == '__main__':
run()
我们运行visit.py,输入:home,页面结果如下:
请输入您想访问页面的url: home
这是网站主页面!
这就实现了一个简单的WEB路由功能,根据不同的url,执行不同的函数,获得不同的页面。
然而,让我们考虑一个问题,如果commons模块里有成百上千个函数呢(这非常正常)?。难道你在visit模块里写上成百上千个elif?显然这是不可能的!那么怎么破?
三、反射机制
仔细观察visit中的代码,我们会发现用户输入的url字符串和相应调用的函数名好像!如果能用这个字符串直接调用函数就好了!但是,前面我们已经说了字符串是不能用来调用函数的。为了解决这个问题,python为我们提供一个强大的内置函数:getattr!我们将前面的visit修改一下,代码如下:
import commons
def run():
inp = input("请输入您想访问页面的url: ").strip()
func = getattr(commons,inp)
func()
if __name__ == '__main__':
run()
首先说明一下getattr函数的使用方法:它接收2个参数,前面的是一个对象或者模块,后面的是一个字符串,注意了!是个字符串!
例子中,用户输入储存在inp中,这个inp就是个字符串,getattr函数让程序去commons这个模块里,寻找一个叫inp的成员(是叫,不是等于),这个过程就相当于我们把一个字符串变成一个函数名的过程。然后,把获得的结果赋值给func这个变量,实际上func就指向了commons里的某个函数。最后通过调用func函数,实现对commons里函数的调用。这完全就是一个动态访问的过程,一切都不写死,全部根据用户输入来变化。
执行上面的代码,结果和最开始的是一样的。
这就是python的反射,它的核心本质其实就是利用字符串的形式去对象(模块)中操作(查找/获取/删除/添加)成员,一种基于字符串的事件驱动!
这段话,不一定准确,但大概就是这么个意思。
四、进一步完善
上面的代码还有个小瑕疵,那就是如果用户输入一个非法的url,比如jpg,由于在commons里没有同名的函数,肯定会产生运行错误,具体如下:
请输入您想访问页面的url: jpg Traceback (most recent call last): File "F:/Python/pycharm/s13/reflect/visit.py", line 16, in <module> run() File "F:/Python/pycharm/s13/reflect/visit.py", line 11, in run func = getattr(commons,inp) AttributeError: module 'commons' has no attribute 'jpg'
那怎么办呢?其实,python考虑的很全面了,它同样提供了一个叫hasattr的内置函数,用于判断commons中是否具有某个成员。我们将代码修改一下:
import commons
def run():
inp = input("请输入您想访问页面的url: ").strip()
if hasattr(commons,inp):
func = getattr(commons,inp)
func()
else:
print("404")
if __name__ == '__main__':
run()
通过hasattr的判断,可以防止非法输入错误,并将其统一定位到错误页面。
其实,研究过python内置函数的朋友,应该注意到还有delattr和setattr两个内置函数。从字面上已经很好理解他们的作用了。
python的四个重要内置函数:getattr、hasattr、delattr和setattr较为全面的实现了基于字符串的反射机制。他们都是对内存内的模块进行操作,并不会对源文件进行修改。
五、动态导入模块
上面的例子是在某个特定的目录结构下才能正常实现的,也就是commons和visit模块在同一目录下,并且所有的页面处理函数都在commons模块内。如下图:
但在现实使用环境中,页面处理函数往往被分类放置在不同目录的不同模块中,也就是如下图:
难道我们要在visit模块里写上一大堆的import 语句逐个导入account、manage、commons模块吗?要是有1000个这种模块呢?
刚才我们分析完了基于字符串的反射,实现了动态的函数调用功能,我们不禁会想那么能不能动态导入模块呢?这完全是可以的!
python提供了一个特殊的方法:__import__(字符串参数)。通过它,我们就可以实现类似的反射功能。__import__()方法会根据参数,动态的导入同名的模块。
我们再修改一下上面的visit模块的代码。
def run():
inp = input("请输入您想访问页面的url: ").strip()
modules, func = inp.split("/")
obj = __import__(modules)
if hasattr(obj, func):
func = getattr(obj, func)
func()
else:
print("404")
if __name__ == '__main__':
run()
运行一下:
请输入您想访问页面的url: commons/home
这是网站主页面!
请输入您想访问页面的url: account/find
这是一个查找功能页面!
我们来分析一下上面的代码:
首先,我们并没有定义任何一行import语句;
其次,用户的输入inp被要求为类似“commons/home”这种格式,其实也就是模拟web框架里的url地址,斜杠左边指向模块名,右边指向模块中的成员名。
然后,modules,func = inp.split("/")处理了用户输入,使我们获得的2个字符串,并分别保存在modules和func变量里。
接下来,最关键的是obj = __import__(modules)这一行,它让程序去导入了modules这个变量保存的字符串同名的模块,并将它赋值给obj变量。
最后的调用中,getattr去modules模块中调用func成员的含义和以前是一样的。
总结:通过__import__函数,我们实现了基于字符串的动态的模块导入。
同样的,这里也有个小瑕疵!
如果我们的目录结构是这样的:
那么在visit的模块调用语句中,必须进行修改,我们想当然地会这么做:
def run():
inp = input("请输入您想访问页面的url: ").strip()
modules, func = inp.split("/")
obj = __import__("lib." + modules) #注意字符串的拼接
if hasattr(obj, func):
func = getattr(obj, func)
func()
else:
print("404")
if __name__ == '__main__':
run()
改了这么一个地方:obj = __import__("lib." + modules),看起来似乎没什么问题,和import lib.commons的传统方法类似,但实际上运行的时候会有错误。
请输入您想访问页面的url: commons/home
404
请输入您想访问页面的url: account/find
404
为什么呢?因为对于lib.xxx.xxx.xxx这一类的模块导入路径,__import__默认只会导入最开头的圆点左边的目录,也就是“lib”。我们可以做个测试,在visit同级目录内新建一个文件,代码如下:
obj = __import__("lib.commons")
print(obj)
执行结果:
<module 'lib' (namespace)>
这个问题怎么解决呢?加上fromlist = True参数即可!
def run():
inp = input("请输入您想访问页面的url: ").strip()
modules, func = inp.split("/")
obj = __import__("lib." + modules, fromlist=True) # 注意fromlist参数
if hasattr(obj, func):
func = getattr(obj, func)
func()
else:
print("404")
if __name__ == '__main__':
run()
至此,动态导入模块的问题基本都解决了,只剩下最后一个,那就是万一用户输入错误的模块名呢?比如用户输入了somemodules/find,由于实际上不存在somemodules这个模块,必然会报错!那有没有类似上面hasattr内置函数这么个功能呢?答案是没有!碰到这种,你只能通过异常处理来解决。
六、最后的思考
可能有人会问python不是有两个内置函数exec和eval吗?他们同样能够执行字符串。比如:
exec("print('haha')")
结果:
haha
那么直接使用它们不行吗?非要那么费劲地使用getattr, __import__干嘛?
其实,在上面的例子中,围绕的核心主题是如何利用字符串驱动不同的事件,比如导入模块、调用函数等等,这些都是python的反射机制,是一种编程方法、设计模式的体现,凝聚了高内聚、松耦合的编程思想,不能简单的用执行字符串来代替。当然,exec和eval也有它的舞台,在web框架里也经常被使用。
-
metaclass作用?以及应用场景?
用尽量多的方法实现单例模式
一、模块单例
Python 的模块就是天然的单例模式,因为模块在第一次导入时,会生成 .pyc 文件,当第二次导入时,就会直接加载 .pyc 文件,而不会再次执行模块代码。
#foo1.py
class Singleton(object):
def foo(self):
pass
singleton = Singleton()
#foo.py
from foo1 import singleton
直接在其他文件中导入此文件中的对象,这个对象即是单例模式的对象
二、静态变量方法
先执行了类的__new__方法(我们没写时,默认调用object.__new__),实例化对象;然后再执行类的__init__方法,对这个对象进行初始化,所有我们可以基于这个,实现单例模式。
class Singleton(object):
def __new__(cls,a):
if not hasattr(cls, '_instance'):
cls._instance = object.__new__(cls)
return cls._instance
def __init__(self,a):
self.a = a
def aa(self):
print(self.a)
a = Singleton("a")
变种:利用类的静态方法或者类方法,实现对函数初始化的控制。该方法需要手动调用静态方法实现实例。本质上是手动版的__new__方法。
三、元类方法
此方法是在__new__方法的更上层对实例化过程进行控制。
原理:执行元类的 元类的__new__方法和__init__方法用来实例化类对象,__call__ 方法用来对实例化的对象的实例即类的对象进行控制。__call__方法会调用实例类的 __new__方法,用于创建对象。返回对象给__call__方法,然后调用类对象的 __init__方法,用于对对象初始化。
class Singleton1(type):
def __init__(self, *args, **kwargs):
self.__instance = None
super(Singleton1,self).__init__(*args, **kwargs)
def __call__(self, *args, **kwargs):
if self.__instance is None:
self.__instance = super(Singleton1,self).__call__(*args, **kwargs)
return self.__instance
class Singleton2(type):
_inst = {}
def __call__(cls, *args, **kwargs):
print(cls)
if cls not in cls._inst:
cls._inst[cls] = super(Singleton2, cls).__call__(*args)
return cls._inst[cls]
class C(metaclass=Singleton1):
pass
四、装饰器
原理:装饰器用来控制类调用__call__方法。
def singleton(cls, *args, **kw):
instance = {}
def _singleton(args):
if cls not in instance:
instance[cls] = cls(*args, **kw)
return instance[cls]
return _singleton
@singleton
class A:
pass
-
python中的作用域
Python 中,一个变量的作用域总是由在代码中被赋值的地方所决定的。
当 Python 遇到一个变量的话他会按照这样的顺序进行搜索:
本地作用域(Local)→当前作用域被嵌入的本地作用域(Enclosing locals)→全局/模块作用域(Global)→内置作用域(Built-in)
-
闭包
闭包(closure)是函数式编程的重要的语法结构。闭包也是一种组织代码的结构,它同样提高了代码的可重复使用性。
当一个内嵌函数引用其外部作作用域的变量,我们就会得到一个闭包. 总结一下,创建一个闭包必须满足以下几点:
- 必须有一个内嵌函数
- 内嵌函数必须引用外部函数中的变量
- 外部函数的返回值必须是内嵌函数
感觉闭包还是有难度的,几句话是说不明白的,还是查查相关资料.
重点是函数运行后并不会被撤销,就像16题的instance字典一样,当函数运行完后,instance并不被销毁,而是继续留在内存空间里.这个功能类似类里的类变量,只不过迁移到了函数上.
闭包就像个空心球一样,你知道外面和里面,但你不知道中间是什么样.
-
装饰器的写法以及应用场景。
应用场景:
1、授权(Authorization)
装饰器能有助于检查某个人是否被授权去使用一个web应用的端点(endpoint)。它们被大量使用于Flask和Django web框架中。这里是一个例子来使用基于装饰器的授权:
from functools import wraps # 最新版python引用是 import functools
def requires_auth(f): # f 就是我们需要装饰的函数,一看就是不带参数的装饰器
@wraps(f) # 新版python写法 @functools.wraps(f)
def decorated(*args, **kwargs):
auth = request.authorization
if not auth or not check_auth(auth.username, auth.password):
authenticate()
return f(*args, **kwargs)
return decorated # 该装饰器需相关配置才能运行,这里是截取代码展示应用
2.、日志(Logging)
日志是装饰器运用的另一个亮点。这是个例子:
from functools import wraps
def logit(func):
@wraps(func)
def with_logging(*args, **kwargs):
print(func.__name__ + " was called")
return func(*args, **kwargs)
return with_logging
@logit
def addition_func(x):
"""Do some math."""
return x + x
result = addition_func(4)
我敢肯定你已经在思考装饰器的一个其他聪明用法了。
3.、带参数的装饰器
带参数的装饰器是典型的闭包函数
4.、在函数中嵌入装饰器
我们回到日志的例子,并创建一个包裹函数,能让我们指定一个用于输出的日志文件。
from functools import wraps
def logit(logfile='out.log'):
def logging_decorator(func):
@wraps(func)
def wrapped_function(*args, **kwargs):
log_string = func.__name__ + " was called"
print(log_string)
# 打开logfile,并写入内容
with open(logfile, 'a') as opened_file:
# 现在将日志打到指定的logfile
opened_file.write(log_string + '\n')
return func(*args, **kwargs)
return wrapped_function
return logging_decorator
@logit()
def myfunc1():
pass
myfunc1()
# Output: myfunc1 was called
# 现在一个叫做 out.log 的文件出现了,里面的内容就是上面的字符串
@logit(logfile='func2.log')
def myfunc2():
pass
myfunc2()
# Output: myfunc2 was called
# 现在一个叫做 func2.log 的文件出现了,里面的内容就是上面的字符串
5.、装饰器类
现在我们有了能用于正式环境的logit装饰器,但当我们的应用的某些部分还比较脆弱时,异常也许是需要更紧急关注的事情。比方说有时你只想打日志到一个文件。而有时你想把引起你注意的问题发送到一个email,同时也保留日志,留个记录。这是一个使用继承的场景,但目前为止我们只看到过用来构建装饰器的函数。
幸运的是,类也可以用来构建装饰器。那我们现在以一个类而不是一个函数的方式,来重新构建logit。
-
异常处理写法以及如何主动跑出异常(应用场景)
-
什么是面向对象的mro
-
isinstance作用以及应用场景?

isinstance作用:来判断一个对象是否是一个已知的类型;
其第一个参数(object)为对象,第二个参数为类型名(int...)或类型名的一个列表((int,list,float)是一个列表)。其返回值为布尔型(True or flase)。
若对象的类型与参数二的类型相同则返回True。若参数二为一个元组,则若对象类型与元组中类型名之一相同即返回True。
简单来说就是判断object是否与第二个参数的类型相同,举例如下:
# -*- coding: utf-8 -*- p = '123' print "1.",isinstance(p,str)#判断P是否是字符串类型 a = "中国" print isinstance(a,unicode) #判断a是否是Unicode编码 print isinstance(a,(unicode,str))#判断a所属类型是否包含在元组中 list1 = [1,2,3,4,5] print isinstance(list1,list)#判断list1是否是列表的类型
-
写代码并实现:
Given an array of integers, return indices of the two numbers such that they add up to a specific target.You may assume that each input would
have exactly one solution, and you may not use the same element twice.
Example:
Given nums = [2, 7, 11, 15], target = 9,
Because nums[0] + nums[1] = 2 + 7 = 9,
return [0, 1]
-
json序列化时,可以处理的数据类型有哪些?如何定制支持datetime类型?
-
json序列化时,默认遇到中文会转换成unicode,如果想要保留中文怎么办?
-
什么是断言?应用场景?
Python的assert是用来检查一个条件,如果它为真,就不做任何事。如果它为假,则会抛出AssertError并且包含错误信息。例如:
x = 23 assert x > 0, "x is not zero or negative" assert x%2 == 0, "x is not an even number"
结果显示:

很多人用assert作为一个很快和容易的方法来在参数错误的时候抛出异常。但这样做是错的,非常错误,有两个原因。首先AssertError不是在测试参数时应该抛出的错误。你不应该像这样写代码:
x = "14"
if not isinstance(x, int):
raise AssertionError("not an int")
显示结果:

你应该抛出TypeError的错误,assert会抛出错误的异常。
那什么时候应该使用assert?没有特定的规则,断言应该用于:
☆防御型的编程
☆运行时检查程序逻辑
☆检查约定
☆程序常量
☆检查文档
(在测试代码的时候使用断言也是可接受的,是一种很方便的单元测试方法,你接受这些测试在用-O标志运行时不会做任何事。我有时在代码里使用assert False来标记没有写完的代码分支,我希望这些代码运行失败。尽管抛出NotImplementedError可能会更好。)
关于断言的意见有很多,因为它能确保代码的正确性。如果你确定代码是正确的,那么就没有用断言的必要了,因为他们从来不会运行失败,你可以直接移除这些断言。如果你确定检查会失败,那么如果你不用断言,代码就会通过编译并忽略你的检查。
在以上两种情况下会很有意思,当你比较肯定代码但是不是绝对肯定时。可能你会错过一些非常古怪的情况。在这个情况下,额外的运行时检查能帮你确保任何错误都会尽早地被捕捉到
另一个好的使用断言的方式是检查程序的不变量。一个不变量是一些你需要依赖它为真的情况,除非一个bug导致它为假。如果有bug,最好能够尽早发现,所以我们为它进行一个测试,但是又不想减慢代码运行速度。所以就用断言,因为它能在开发时打开,在产品阶段关闭。
一个非变量的例子可能是,如果你的函数希望在它开始时有数据库的连接,并且承诺在它返回的时候仍然保持连接,这就是函数的不变量:
def some_function(arg):
assert not DB.closed()
... # code goes here
assert not DB.closed()
return result
断言本身就是很好的注释,胜过你直接写注释:
# when we reach here, we know that n > 2
你可以通过添加断言来确保它:
assert n > 2
断言也是一种防御型编程。你不是让你的代码防御现在的错误,而是防止在代码修改后引发的错误。理想情况下,单元测试可以完成这样的工作,可是需要面对的现实是,它们通常是没有完成的。人们可能在提交代码前会忘了运行测试代码。有一个内部检查是另一个阻挡错误的防线,尤其是那些不明显的错误,却导致了代码出问题并且返回错误的结果。
加入你有一些if…elif 的语句块,你知道在这之前一些需要有一些值
# target is expected to be one of x, y, or z, and nothing else. if target == x: run_x_code() elif target == y: run_y_code() else: run_z_code()
假设代码现在是完全正确的。但它会一直是正确的吗?依赖的修改,代码的修改。如果依赖修改成 target = w 会发生什么,会关系到run_w_code函数吗?如果我们改变了代码,但没有修改这里的代码,可能会导致错误的调用 run_z_code 函数并引发错误。用防御型的方法来写代码会很好,它能让代码运行正确,或者立马执行错误,即使你在未来对它进行了修改。
在代码开头的注释很好的一步,但是人们经常懒得读或者更新注释。一旦发生这种情况,注释会变得没用。但有了断言,我可以同时对代码块的假设书写文档,并且在它们违反的时候触发一个干净的错误
assert target in (x, y, z) if target == x: run_x_code() elif target == y: run_y_code() else: assert target == z run_z_code()
这样,断言是一种防御型编程,同时也是一种文档。我想到一个更好的方案:
if target == x:
run_x_code()
elif target == y:
run_y_code()
elif target == z:
run_z_code()
else:
# This can never happen. But just in case it does...
raise RuntimeError("an unexpected error occurred")
按约定进行设计是断言的另一个好的用途。我们想象函数与调用者之间有个约定,比如下面的:
“如果你传给我一个非空字符串,我保证传会字符串的第一个字母并将其大写。”
如果约定被函数或调用这破坏,代码就会出问题。我们说函数有一些前置条件和后置条件,所以函数就会这么写:
def first_upper(astring): assert isinstance(astring, str) and len(astring) > 0 result = astring[0].upper() assert isinstance(result, str) and len(result) == 1 assert result == result.upper() return result
按约定设计的目标是为了正确的编程,前置条件和后置条件是需要保持的。这是断言的典型应用场景,因为一旦我们发布了没有问题的代码到产品中,程序会是正确的,并且我们能安全的移除检查。
下面是我建议的不要用断言的场景:
☆不要用它测试用户提供的数据
☆不要用断言来检查你觉得在你的程序的常规使用时会出错的地方。断言是用来检查非常罕见的问题。你的用户不应该看到任何断言错误,如果他们看到了,这是一个bug,修复它。
☆有的情况下,不用断言是因为它比精确的检查要短,它不应该是懒码农的偷懒方式。
☆不要用它来检查对公共库的输入参数,因为它不能控制调用者,所以不能保证调用者会不会打破双方的约定。
☆不要为你觉得可以恢复的错误用断言。换句话说,不用改在产品代码里捕捉到断言错误。
☆不要用太多断言以至于让代码很晦涩。
-
有用过with statement吗?它的好处是什么?
python中的with语句是用来干嘛的?有什么作用?
with语句的作用是通过某种方式简化异常处理,它是所谓的上下文管理器的一种
用法举例如下:
with open('output.txt', 'w') as f:
f.write('Hi there!')
当你要成对执行两个相关的操作的时候,这样就很方便,以上便是经典例子,with语句会在嵌套的代码执行之后,自动关闭文件。这种做法的还有另一个优势就是,无论嵌套的代码是以何种方式结束的,它都关闭文件。如果在嵌套的代码中发生异常,它能够在外部exception handler catch异常前关闭文件。如果嵌套代码有return/continue/break语句,它同样能够关闭文件。
我们也能够自己构造自己的上下文管理器
我们可以用contextlib中的context manager修饰器来实现,比如可以通过以下代码暂时改变当前目录然后执行一定操作后返回。
from contextlib import contextmanager
import os
@contextmanager
def working_directory(path):
current_dir = os.getcwd()
os.chdir(path)
try:
yield
finally:
os.chdir(current_dir)
with working_directory("data/stuff"):
# do something within data/stuff
# here I am back again in the original working directory
-
使用代码实现查看列举目录下的所有文件。
-
简述 yield和yield from关键字。
1、可迭代对象与迭代器的区别
可迭代对象:指的是具备可迭代的能力,即enumerable. 在Python中指的是可以通过for-in 语句去逐个访问元素的一些对象,比如元组tuple,列表list,字符串string,文件对象file 等。
迭代器:指的是通过另一种方式去一个一个访问可迭代对象中的元素,即enumerator。在python中指的是给内置函数iter()传递一个可迭代对象作为参数,返回的那个对象就是迭代器,然后通过迭代器的next()方法逐个去访问。
2、生成器
生成器的本质就是一个逐个返回元素的函数,即“本质——函数”
生成器有什么好处?
最大的好处在于它是“延迟加载”,即对于处理长序列问题,更加的节省存储空间。即生成器每次在内存中只存储一个值,比如打印一个斐波拉切数列:原始的方法可以如下所示:
def fab(max): n, a, b = 0, 0, 1 L = [] while n < max: L.append(b) a, b = b, a + b n = n + 1 return L
这样做最大的问题在于将所有的元素都存储在了L里面,很占用内存,而使用生成器则如下所示
def fab(max): n, a, b = 0, 0, 1 while n < max: yield b #每次迭代时值加载这一个元素,而且替换掉之前的那一个元素,这样就大大节省了内存。而且程序在遇见yield语句时会 停下来,这是后面使用yield阻断原理进行多线程编程的一个启发,(python协程编程会在后面讲到) a, b = b, a + b n = n + 1
生成器其实就是下面这个样子,写得简单一些就是一次返回一条,如下:
def generator():
for i in range(5):
yield i
def generator_1():
yield 1
yield 2
yield 3
yield 4
yield 5
上面这两种方式是完全等价的,只不过前者更简单一些。
3、什么又是yield from呢?
简单地说,yield from generator 。实际上就是返回另外一个生成器。如下所示:
def generator1():
item = range(10)
for i in item:
yield i
def generator2():
yield 'a'
yield 'b'
yield 'c'
yield from generator1() #yield from iterable本质上等于 for item in iterable: yield item的缩写版
yield from [11,22,33,44]
yield from (12,23,34)
yield from range(3)
for i in generator2() :
print(i)
从上面的代码可以看书,yield from 后面可以跟的式子有“ 生成器 元组 列表等可迭代对象以及range()函数产生的序列”
上面代码运行的结果为:
a
b
c
0
1
2
3
4
5
6
7
8
9
11
22
33
44
12
23
34
0
1
2
-
提高python运行效率的方法
1、使用生成器,因为可以节约大量内存
2、循环代码优化,避免过多重复代码的执行
3、核心模块用Cython PyPy等,提高效率
4、多进程、多线程、协程
5、多个if elif条件判断,可以把最有可能先发生的条件放到前面写,这样可以减少程序判断的次数,提高效率
IOError、AttributeError、ImportError、IndentationError、IndexError、KeyError、SyntaxError、NameError分别代表什么异常
IOError:输入输出异常
AttributeError:试图访问一个对象没有的属性
ImportError:无法引入模块或包,基本是路径问题
IndentationError:语法错误,代码没有正确的对齐
IndexError:下标索引超出序列边界
KeyError:试图访问你字典里不存在的键
SyntaxError:Python代码逻辑语法出错,不能执行
NameError:使用一个还未赋予对象的变量