Pytorch学习 for hw3(2)Logisitic Regression_不归一化容易发散-程序员宅基地
技术标签: 机器学习 pytorch Hong _YiLi
文章目录
逻辑回归是由概率公式推导产生的,常用来做分类任务,拿手写数字辨识1-10为例:通过计算max{ P ( x = 0 ) , P ( x = 1 ) , . . . , P ( x = 9 ) P(x=0),P(x=1),...,P(x=9) P(x=0),P(x=1),...,P(x=9)},找出最大的概率值即为该x对应的类别。
1、Logisitic Regression
(1)前言
介绍一种下载数据集的方法,但是本次案例未使用到。
在安装pytorch时,有个torchvison工具包可以提供一些比较流行的数据集如MNISIT Dataset(手写数字数据),CIFAR-10(32╳32像素的像图片),但是需要在网上下载,下载方法如下:
import torchvision
train_set = torchvision.datasets.MNIST(root='D:/py文件/Hong YiLee/homework3/dataset/mnist', train=True, download=True)
test_set = torchvision.datasets.MNIST(root='D:/py文件/Hong YiLee/homework3/dataset/mnist', train=False, download=True)
root:若未下载过则标明下载地址,已经下载过则标明数据所在位置
train=True:表示提取的是training data,=False表示提取的是testing data
download=True:表示将在往网上下载,=False表示从本机提取
运行结果如下,就是速度有点慢(开了VPN也慢)

由于是分类问题所以,本次实例和上次的略有区别:现有三个输入x,对应两个分类y=0和y=1,求输入为4时,输出y为多少。
| x | y |
|---|---|
| 1.0 | 0 |
| 2.0 | 0 |
| 3.0 | 1 |
| 4.0 | ? |
所以,进而将问题简化为二分类问题即求P(y=0)、P(y=1),且P(y=1)=1-P(y=0),若P(y=0)>0.5那么y=0。由于P(y=0)可能接近0.5,那么在这种情况下分类器对于该x的类别是不确定的,应该输出“不确定”。
(2)知识点介绍:
可以将二分类问题简化为输出为[0,1]之间的回归问题。那么我们只需要将的线性回归的输出映射到[0,1]即可,而sigmiod函数恰好满足:定义域为(-∞,+∞),值域为(0,1)。当输出y>0.5则被归为1,小于0.5则被归为0。损失函数选用由概率推导出来的cross entropy(交叉熵),简称BCE(Binary Cross Entropy),最后要求和取平均值(对loss求导数的时候1/N会影响lr的大小,加上则不用将lr调的过大)。

torch.nn.BCELoss的参数详解点击链接
torch.nn.Functional的模块包含很多函数,其中有sigmoid函数,我使用的pytorch1.7.1版本已经弃用这种方法,可直接使用torch.sigmoid()
(3)完整代码:
(和Linear Regression差不多)
import torch
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[0], [0], [1]])
class LogisticRegressionModel(torch.nn.Module):
# 初始化
def __init__(self):
# 初始化从torch.nn.Module继承的属性
super(LogisticRegressionModel, self).__init__()
# 设置实例属性self.linear
self.linear = torch.nn.Linear(1, 1)
# 定义实例方法,添加输入x
def forward(self, x):
y_pred = torch.sigmoid(self.linear(x))
return y_pred
model = LogisticRegressionModel()
criterion = torch.nn.BCELoss(reduction='sum')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for i in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
输出如下:
能看出随迭代次数的增加loss值在减小,最后一次的loss值为1.0836951732635498。
0 2.484407901763916
1 2.4654228687286377
2 2.44744610786438
3 2.4304330348968506
4 2.4143383502960205
5 2.399118423461914
测试对x=4的y的分类,结果y_pred =0.8407>0.5 所以分类正确
x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)
# y_pred = tensor([[0.8407]])
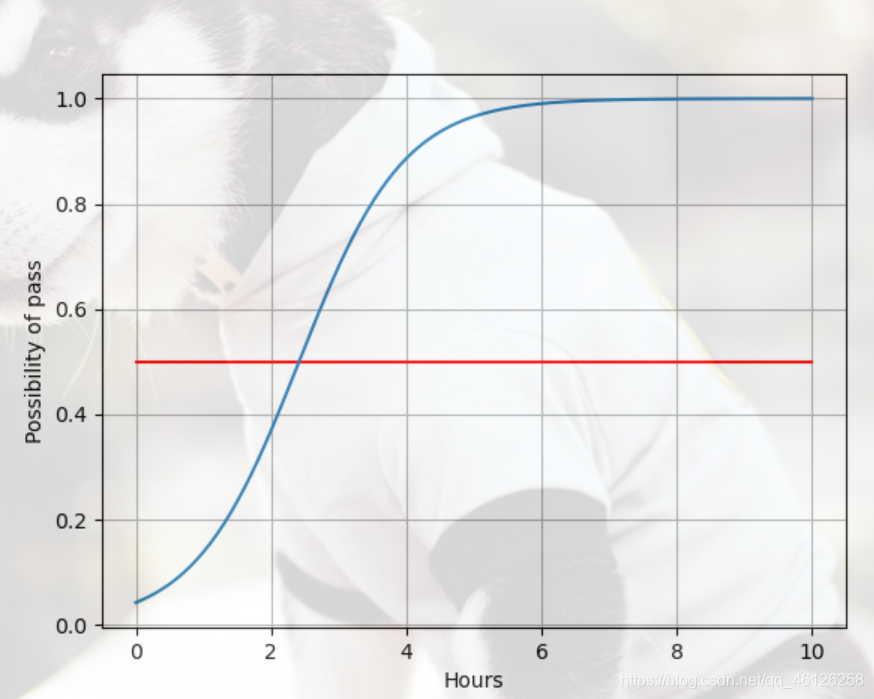
(4)查看y(是否通过考试)对x(每日的学习时间)的函数
(实际上并不是函数,是在取多个点之后的预测值绘制的图像)
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 10, 200) # 取1-10之间等间距的200个点,并组成一个列表
x_t = torch.Tensor(x).view((200, 1)) # 将1行的列表转为200行1列的列向量
y_t = model(x_t) # 输入x,调用logistic model
y = y_t.data.numpy() # 将y_data转化为numpy数据才能进行画图
plt.plot(x, y)
plt.plot([0, 10], [0.5, 0.5], c='r') # 画出分界线
plt.xlabel('Hours')
plt.ylabel('Possibility of pass')
plt.grid() # 画出背景网格线
plt.show() # 显示图
由于一使用plt.plot就出现下面的错误
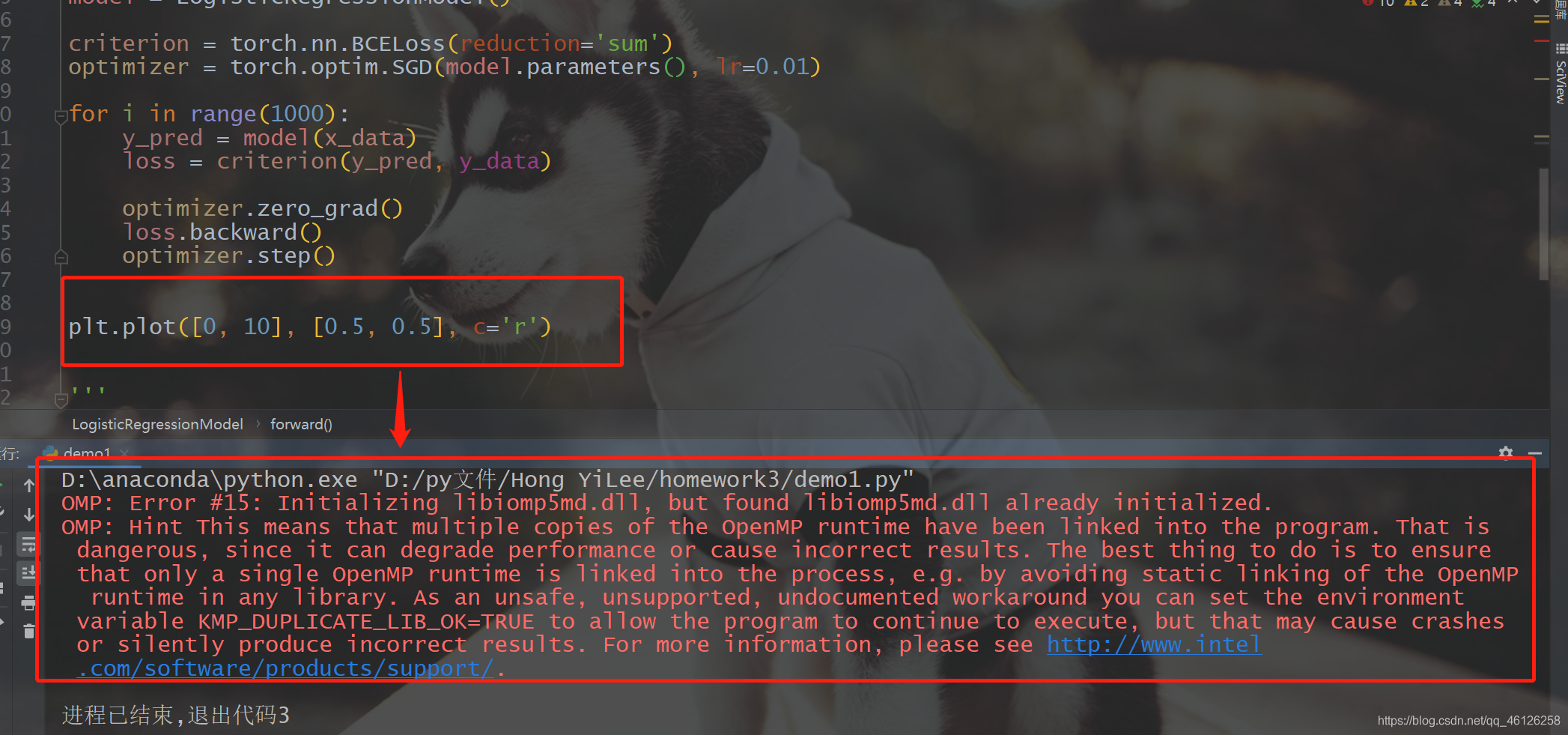
所以添加了一句,问题就解决了
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
结果如下,可以看到当学习时间为两个小时多的时候就会使possibility达到0.5,也就是y的取值为1,自然当x=4时y的取值也为1.
2、多层神经网络的连接
一层的时候运算过程如下:

可以将单个函数的运算拼成矩阵相乘,进而能够使用GPU加速运算过程。torch.nn.Linear(8,1)表示输入x有8列特征,输出y有1列。

当有三层的时候,可以将矩阵乘法看成维度转换的函数,只需要改变torch.nn.Linear()的参数就可以实现两层神经网络的连接单元数如下:

(1)二分类
在二分类中我们用到糖尿病的数据集(diabetes),通过8个特征辨别其是否患有糖尿病,患病输出y=1,否则y=0。
一、数据集的准备
下载链接:https://pan.baidu.com/s/1udhg5-pvS6UsQlpawmd8-w
提取码: itm0
打开文件如下

开始分离x、y
import numpy as np
xy = np.loadtxt('E:\\自制笔记\\课外\\PyTorch深度学习实践\\diabetes.csv.gz', delimiter=',', dtype=np.float32)
x = torch.from_numpy(xy[:, :-1]) # 取所有行的前8列,并转化为tensor
y = torch.from_numpy(xy[:, [-1]]) # 取所有行的的最后一列
print(x.shape, y.shape)
二、根据继承的模块定义model类
import torch
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__() # 初始化从Module继承的方法
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.activation = torch.nn.Sigmoid()
def forward(self, x):
x = self.activation(self.linear1(x))
x = self.activation(self.linear2(x))
x = self.activation(self.linear3(x))
return x
model = Model()
三、设置loss和optimizer
由于size_average已经被弃用,所以使用reduction='mean’代替来求取平均值。
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
四、迭代更新
for epoch in range(100):
y_pred = model(x)
loss = criterion(y_pred, y)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
输出结果:
0 0.7159094214439392
1 0.7150604128837585
2 0.7142216563224792
3 0.7133930325508118
4 0.7125746011734009
5 0.7117661237716675
最后的loss值为 0.6668325662612915,当迭代次数达到1000次时,loss值为0.6445940732955933,并趋于稳定。
五、完整代码:
import torch
import numpy as np
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__() # 初始化从Module继承的方法
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.activation = torch.nn.Sigmoid()
def forward(self, x):
x = self.activation(self.linear1(x))
x = self.activation(self.linear2(x))
x = self.activation(self.linear3(x))
return x
model = Model()
xy = np.loadtxt('E:\\自制笔记\\课外\\PyTorch深度学习实践\\diabetes.csv.gz', delimiter=',', dtype=np.float32)
x = torch.from_numpy(xy[:, :-1]) # 取所有行的前8列,并转化为tensor
y = torch.from_numpy(xy[:, [-1]]) # 取所有行的的最后一列
print(x.shape, y.shape)
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(100):
y_pred = model(x)
loss = criterion(y_pred, y)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
(2)回归问题
下面的案例是根据sklearn的diabetes数据集来做的回归问题。已知影响糖尿病的10列特征,和对应的target,查看随训练的变化loss的变化。
一、数据集准备:
如果安装了sklearn的话,在anaconda文件夹下能找到下图的路径,里面有自带的数据集,如我的位置是D:\anaconda\Lib\site-packages\sklearn\datasets\data
查看输入x: 打开之后发现WPS和excel并不能将每一列分割(只有两列间为" , "数据才能被分割,这里的是空格所以不能被分割为单独的列)

对应的y如下:
其中最小的为25,最大的为346 ,所以先对y进行归一化处理。不进行归一化结果会发散,loss值会很大。
import torch
import numpy as np
np.random.seed(0) #当我们设置相同的seed,每次生成的随机数相同
print()
# 按照sklearn中包的位置将数据读取出来
x = np.loadtxt('D:\\anaconda\\Lib\site-packages\\sklearn\\datasets\\data\\diabetes_data.csv.gz', delimiter=' ',
dtype=np.float32)
y = np.loadtxt('D:\\anaconda\\Lib\site-packages\\sklearn\\datasets\\data\\diabetes_target.csv.gz', delimiter=' ',
dtype=np.float32)
y = y.reshape(-1, 1) #转为一列
#归一化处理
mean_y = np.mean(y, axis = 0)
std_y = np.std(y, axis = 0)
for i in range(len(y)):
if std_y[0] != 0:
y[i][0] = (y[i][0] - mean_y[0]) / std_y[0]
#创建两个tensor
x = torch.from_numpy(x)
y = torch.from_numpy(y)
# 将数据的行数打乱
def _shuffle(X, Y):
# This function shuffles two equal-length list/array, X and Y, together.
randomize = np.arange(len(X))
np.random.shuffle(randomize)
return (X[randomize], Y[randomize])
x, y = _shuffle(x, y)
二、根据继承的模块定义model类
与二分类类似,但是由于y的输出不再是单个的类别(0、1),所以最后一层不能使用激活函数限制他的值域。
class Model(torch.nn.Module):
# 初始化,并定义激活函数
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(10, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.activation = torch.nn.Sigmoid()
# 最后一层不要添加激活函数,否则最后的值域会被限制
def forward(self, x):
x = self.activation(self.linear1(x))
x = self.activation(self.linear2(x))
x = self.linear3(x)
return x
model = Model()
三、设置loss和optimizer
criterion = torch.nn.MSELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
四、迭代更新
for i in range(100):
y_pred = model(x)
loss = criterion(y_pred, y)
print(i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
结果如下:
0 1.1163854598999023
1 1.0310304164886475
2 1.0081417560577393
3 1.001995325088501
4 1.0003454685211182
随迭代次数增加loss变小,最后趋于稳定为0.9996225833892822
智能推荐
Android IPC机制-程序员宅基地
文章浏览阅读917次,点赞18次,收藏11次。为了方便有学习需要的朋友,我把资料都整理成了视频教程(实际上比预期多花了不少精力)当程序员容易,当一个优秀的程序员是需要不断学习的,从初级程序员到高级程序员,从初级架构师到资深架构师,或者走向管理,从技术经理到技术总监,每个阶段都需要掌握不同的能力。早早确定自己的职业方向,才能在工作和能力提升中甩开同龄人。无论你现在水平怎么样一定要 持续学习 没有鸡汤,别人看起来的毫不费力,其实费了很大力,这四个字就是我的建议!!我希望每一个努力生活的IT工程师,都会得到自己想要的,因为我们很辛苦,我们应得的。
利用ode45求解含控制量并且控制量为离散点的动力学方程_ode函数离散-程序员宅基地
文章浏览阅读2k次,点赞5次,收藏14次。1、写出微分方程函数2、求解function dy=rigid(t,y)dy=zeros(3,1);dy(1)=y(2)*y(3);dy(2)=-y(1)*y(3);dy(3)=-0.51*y(1)*y(2);end%将微分方程写成函数形式,待调用options=odeset('RelTol',1e-4,'AbsTol',[1e-4 1e-4 1e-5]);[T Y]=ode45(@rigid,[0 12],[0 1 1],options);plot(T,Y(:,1),'-',T,Y_ode函数离散
Java中==和equals的区别-程序员宅基地
文章浏览阅读3.8w次,点赞41次,收藏180次。==操作符与equals方法的区别_java中==和equals的区别
flask-login-程序员宅基地
文章浏览阅读170次。创建扩展对象实例from flask_login import LoginManagerlogin_manager = LoginManager()login_manager.login_view = 'auth.login'# 上面这一句是设置登录视图的名称,如果一个未登录用户请求一个只有登录用户才能访问的视图,# 则闪现一条错误消息,并重定向到这里设置的登录视图。# 如果未设置..._python flask please log in to access this page
html怎么控制top值为0,关于vue滚动scrollTop 赋值一直为0问题-程序员宅基地
文章浏览阅读428次。Vue中document.body.scrollTop的值总为零的解决办法最近在做vue的时候监听页面滚动发现document.body.scrollTop一直为0但是发现document.body.scrollTop一直是0。查资料发现是DTD的问题。页面指定了DTD,即指定了DOCTYPE时,使用document.documentElement。页面没有DTD,即没指定DOCTYPE时,使用d..._滚动给scrolltop赋值
kingbase数据库安装教程(初步使用)(人大金仓)-程序员宅基地
文章浏览阅读2.1k次,点赞25次,收藏21次。人大金仓数据库管理系统KingbaseES(简称:金仓数据库或KingbaseES)是北京人大金仓信息技术股份有限公司自主研制开发的具有自主知识产权的通用关系型数据库管理系统。_kingbase
随便推点
发现电脑一直默认按住Ctrl键如何解决_键盘一直自动按ctrl-程序员宅基地
文章浏览阅读1k次,点赞11次,收藏9次。你的键盘上应该有两个Ctrl键,按右边的Ctrl解决了。_键盘一直自动按ctrl
Linux 命令【6】:cut_cut使用特殊字符为分隔符-程序员宅基地
文章浏览阅读141次。Linux 命令【6】:cut文章目录一、简介二、命令详解三、实例演示一、简介cut 命令是一个将文本按列进行切分的小工具,它可以指定分隔每列的定界符。二、命令详解命令格式:cut {选项} {文件名}选项:-b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。-c :以字符为单位进行分割。-d :自定义分隔符,默认为制表符。-f :与-d一起使用,指定显示哪个区域。-n :取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一._cut使用特殊字符为分隔符
音频进度条设置_audiotrack可以设置进度吗-程序员宅基地
文章浏览阅读2.4k次。/** * 播放audio标签视频控制 * */ //等待音频加载完毕 点击每一段录音进行播放 $('.lis').click(function(){ $('.j_voiceCont').show(); var src = $(this).attr("src"); $(this).addClass('c_audiotrack可以设置进度吗
Sora----打破虚实之间的最后一根枷锁----这扇门的背后是人类文明的晟阳还是最后的余晖-程序员宅基地
文章浏览阅读1.9k次,点赞69次,收藏64次。Sora官网。
大批量数据分批式导出文件解决,避免OOM(多次查询多次导出形成一个文件)_bufferedwriter避免oom-程序员宅基地
文章浏览阅读2k次。大批量数据的导出,当数据量达到一定的量会导致内存被撑爆,出现 oom异常,基于问题实大批量数据分批的方式进行查询和导出代码实现package com.ly.service;import com.ly.helper.BatchWriteFileUtils;import com.ly.helper.BeanUtils;import com.ly.vo.rs..._bufferedwriter避免oom
如何生成HLS协议的M3U8文件-程序员宅基地
文章浏览阅读5次。什么是HLS协议:HLS(HttpLiveStreaming)是由Apple公司定义的用于实时流传输的协议,HLS基于HTTP协议实现,传输内容包括两部分,一是M3U8描述文件,二是TS媒体文件。HLS协议应用:由于传输层协议只需要标准的HTTP协议, HLS可以方便的透过防火墙或者代理服务器,而且可以很方便的利用CDN进行分发加速,这样就可以很方便的解决大规模应用的瓶颈。并...