ViT全流程笔记,附代码详解。_vit 的unembedding-程序员宅基地
技术标签: paddlepaddle 计算机视觉 深度学习
一、课程介绍
Vision Transformer是近期深度学习领域最前沿、最火爆的技术,本次课程由百度研究院深度学习实验室研究员朱欤博士主讲,将通过图解理论基础、手推公式以及从0开始逐行手敲代码,带大家实现最前沿的视觉Transformer算法!通过Vision Transformer十讲的学习,能一步一步将论文中的模型图变成一行行的代码,从零搭建一套自己的深度学习模型,掌握和实践最新的技术,告别简单的git clone和调包。
二、课程笔记
2.1 ViT整体结构
Encoder模块的线性堆叠,Encoder模块的核心内容是Multi Head Attention。输入[N C H W],输出[N num_classes]。
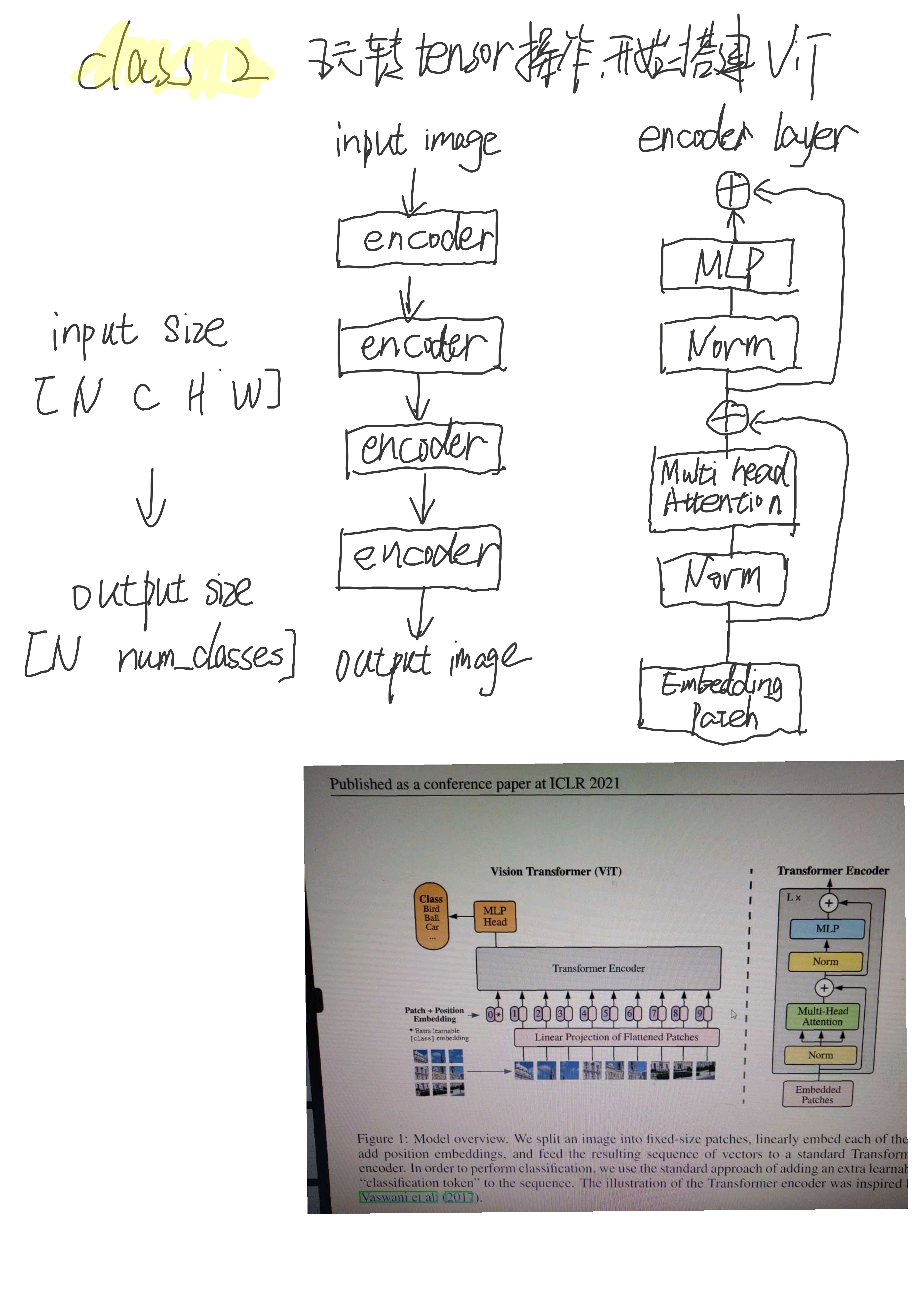
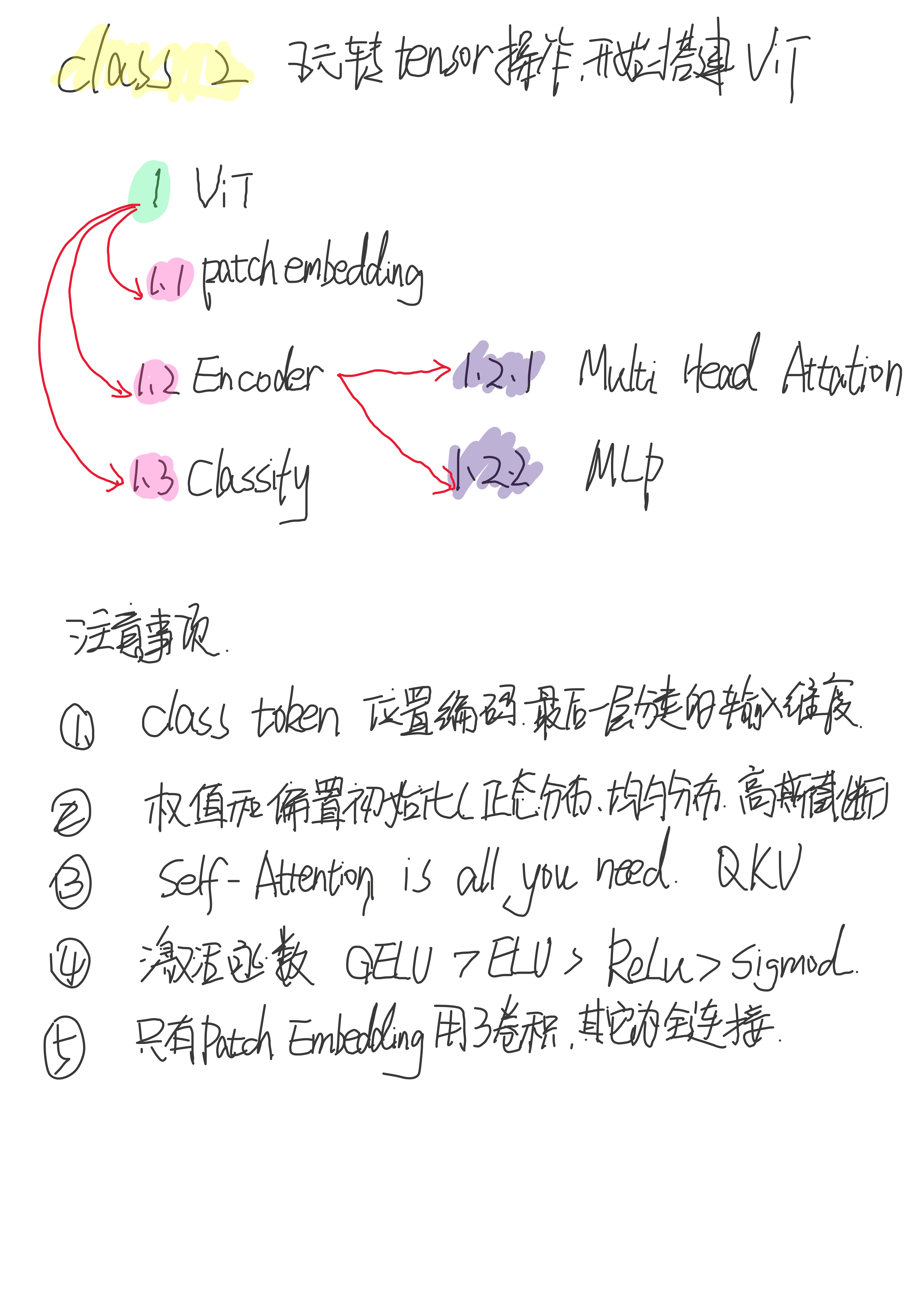
2.1 ViT网络搭建
分别要构建三个类:Patch Embedding、Encoder和Classify,其中Encoder又包括两个类Multi Head Attention和MLP。
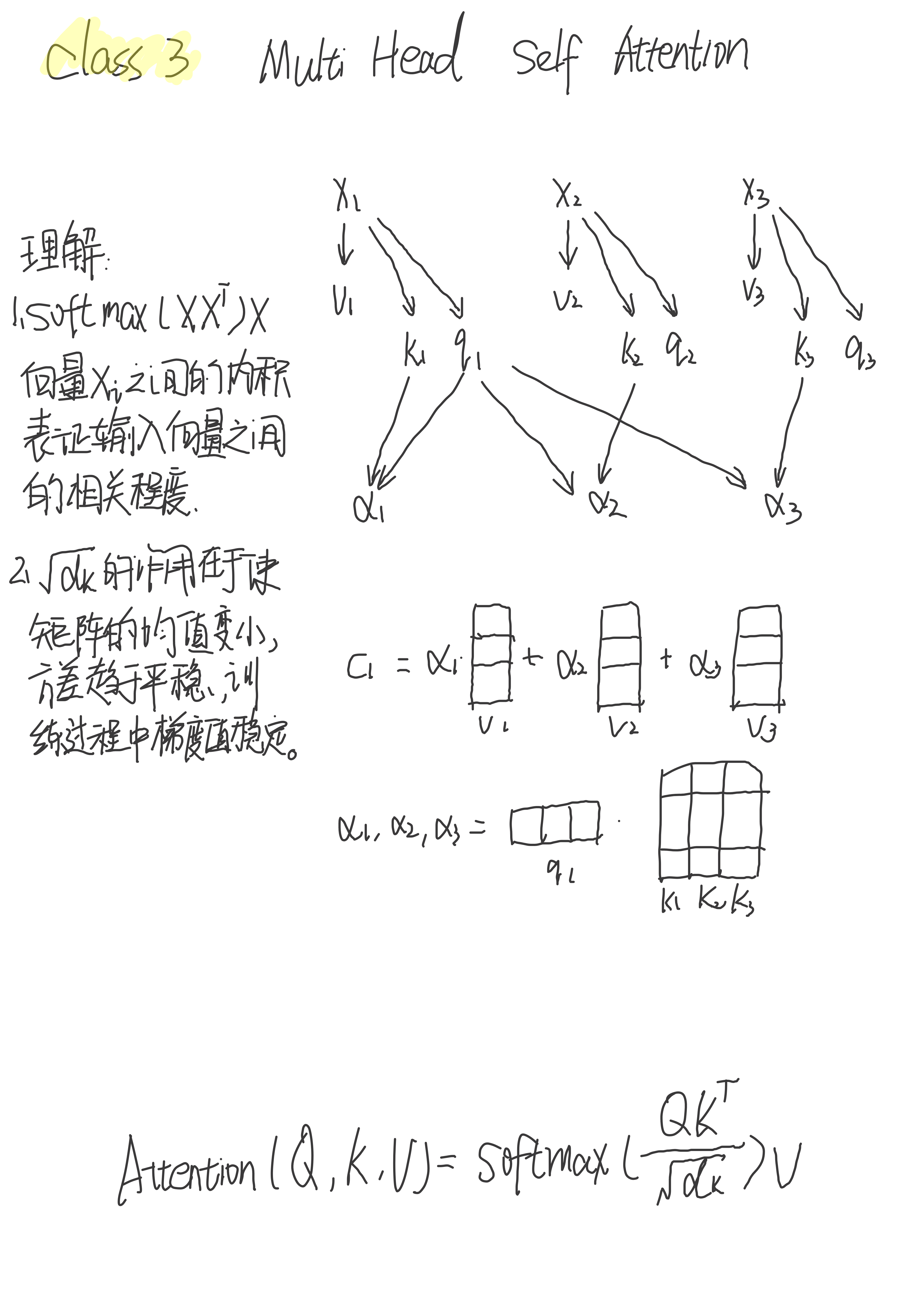
2.3 注意力机制计算公式
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V Attention(Q,K,V)=softmax(dkQKT)V
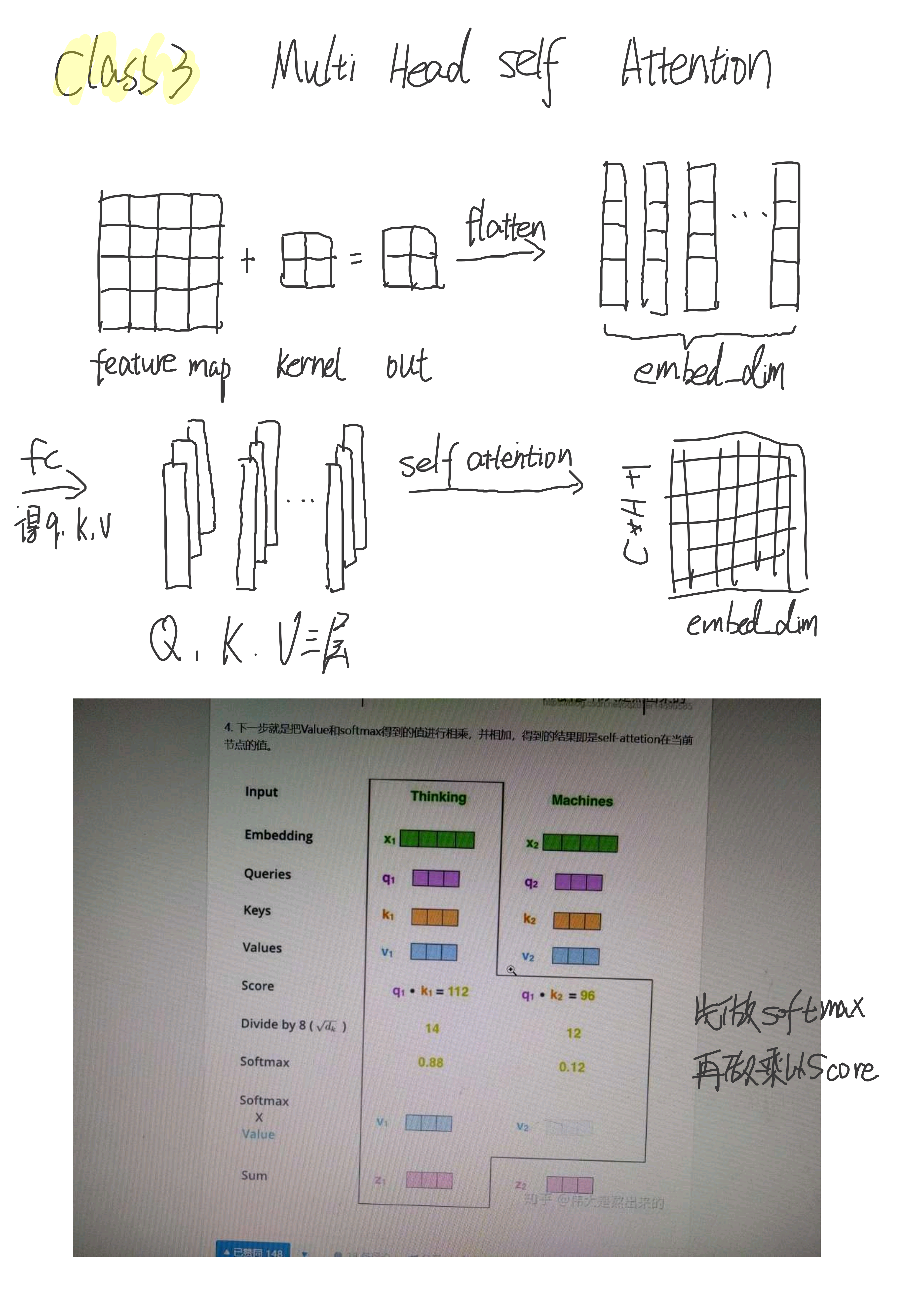
2.4 Feature Map
Patch Embedding是用卷积运算来操作的,Self Attention是用全连接层来操作的。最后输出为[N, C * H + 1, embed_dim],+1是因为加入了Class Token。
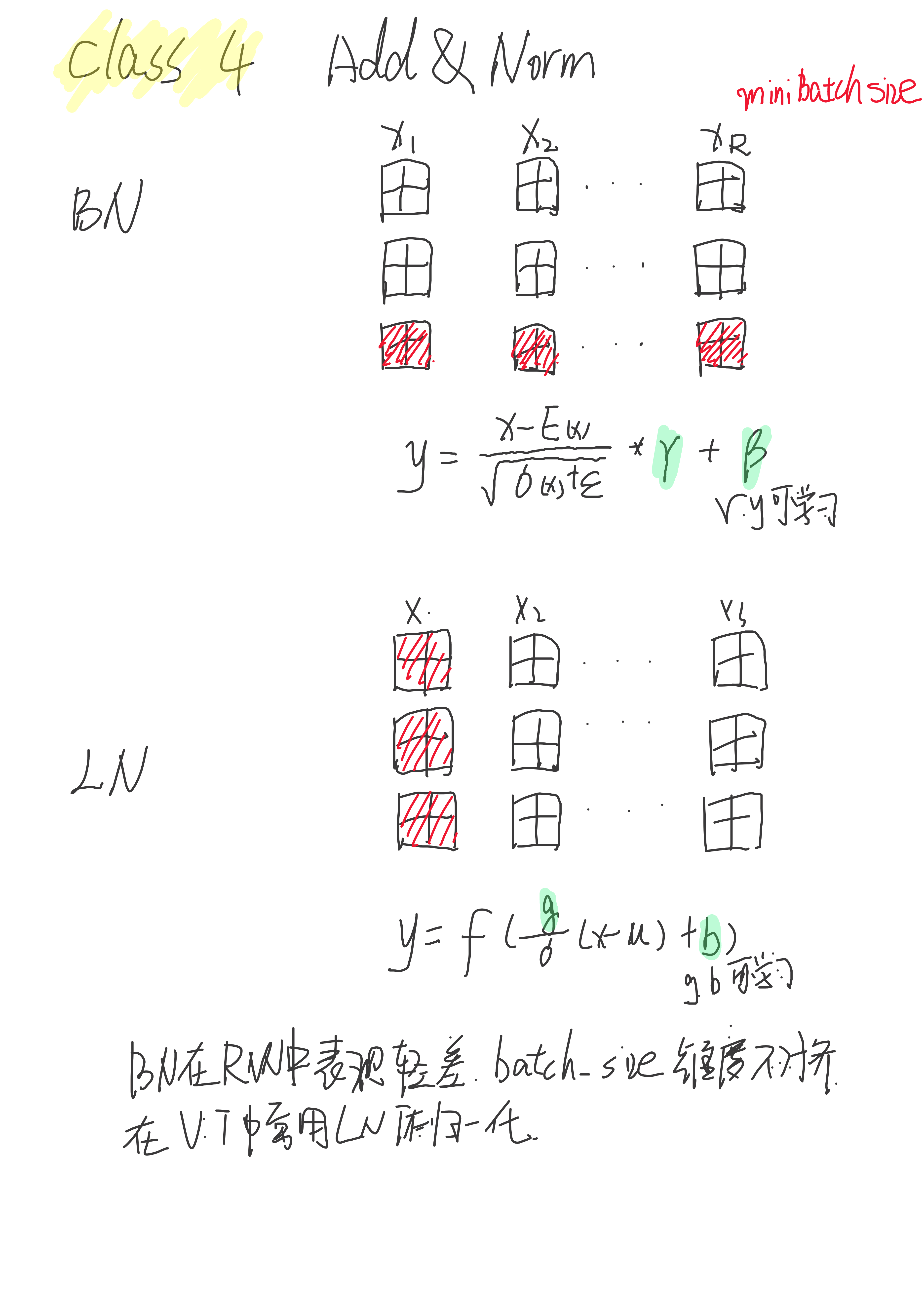
2.5 BatchNorm和LayerNorm
ViT做归一化采用的是LN层,两者有一定区别。
三、课程代码
class ViT
import paddle
import paddle.nn as nn
class ViT(nn.Layer):
def __init__(self,
image_size=224,
patch_size=16,
in_channels=3,
num_classes=1000,
embed_dim=768,
depth=12,
num_heads=12,
mlp_ratio=4,
qkv_bias=True,
dropout=0.,
attention_dropout=0.,):
super(ViT, self).__init__()
#creat patch embedding with positional embedding
self.patch_embedding = PatchEmbedding(image_size,
patch_size,
in_channels,
embed_dim,
dropout)
#creat multi head self-attention layers encoder
self.encoder = Encoder( embed_dim,
num_heads,
qkv_bias,
mlp_ratio,
dropout,
attention_dropout,
depth )
#classifier head for num classes
self.classifier = Classify(embed_dim, dropout, num_classes)
def forward(self, x):
# input [N, C, H', W']
x = self.patch_embedding(x) #[N, C * H + 1, embed_dim]
x = self.encoder(x) #[N, C * H + 1, embed_dim]
x = self.classifier(x[:, 0, :]) #[N, num_classes]
return x
3.1 class PatchEmbedding
class PatchEmbedding(nn.Layer):
def __init__(self,
image_size = 224,
patch_size = 16,
in_channels = 3,
embed_dim = 768,
dropout = 0.):
super(PatchEmbedding, self).__init__()
n_patches = (image_size // patch_size) * (image_size // patch_size) #14 * 14 = 196(个)
self.patch_embedding = nn.Conv2D(in_channels = in_channels,
out_channels = embed_dim,
kernel_size = patch_size,
stride = patch_size)
self.dropout=nn.Dropout(dropout)
#add class token
self.cls_token = paddle.create_parameter(
shape = [1, 1, embed_dim],
dtype = 'float32',
default_initializer = paddle.nn.initializer.Constant(0)
#常量初始化参数,value=0, shape=[1, 1, 768]
)
#add position embedding
self.position_embeddings = paddle.create_parameter(
shape = [1, n_patches + 1, embed_dim],
dtype = 'float32',
default_initializer = paddle.nn.initializer.TruncatedNormal(std = 0.02)
#随机截断正态(高斯)分布初始化函数
)
def forward(self, x):
x = self.patch_embedding(x) #[N, C, H', W',] to [N, embed_dim, H, W]卷积层
x = x.flatten(2) #[N, embed_dim, H * W]
x = x.transpose([0, 2, 1]) #[N, H * W, embed_dim]
cls_token = self.cls_token.expand((x.shape[0], -1, -1)) #[N, 1, embed_dim]
x = paddle.concat((cls_token, x), axis = 1) #[N, H * W + 1, embed_dim]
x = x + self.position_embeddings #[N, H * W + 1, embed_dim]
x = self.dropout(x)
return x
3.2 class Encoder
class Encoder(nn.Layer):
def __init__(self,
embed_dim,
num_heads,
qkv_bias,
mlp_ratio,
dropout,
attention_dropout,
depth):
super(Encoder, self).__init__()
layer_list = []
for i in range(depth):
encoder_layer = EncoderLayer(embed_dim,
num_heads,
qkv_bias,
mlp_ratio,
dropout,
attention_dropout)
layer_list.append(encoder_layer)
self.layers = nn.LayerList(layer_list)# or nn.Sequential(*layer_list)
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x):
for layer in self.layers:
x = layer(x)
x = self.norm(x)
return x
class EncoderLayer(nn.Layer):
def __init__(self,
embed_dim,
num_heads,
qkv_bias,
mlp_ratio,
dropout,
attention_dropout
):
super(EncoderLayer, self).__init__()
#Multi Head Attention & LayerNorm
w_attr_1, b_attr_1 = self._init_weights()
self.attn_norm = nn.LayerNorm(embed_dim,
weight_attr = w_attr_1,
bias_attr = b_attr_1,
epsilon = 1e-6)
self.attn = Attention(embed_dim,
num_heads,
qkv_bias,
dropout,
attention_dropout)
#MLP & LayerNorm
w_attr_2, b_attr_2 = self._init_weights()
self.mlp_norm = nn.LayerNorm(embed_dim,
weight_attr = w_attr_2,
bias_attr = b_attr_2,
epsilon = 1e-6)
self.mlp = Mlp(embed_dim, mlp_ratio, dropout)
def _init_weights(self):
weight_attr = paddle.ParamAttr(initializer=nn.initializer.Constant(0.0))
bias_attr = paddle.ParamAttr(initializer=nn.initializer.Constant(1.0))
return weight_attr, bias_attr
def forward(self, x):
h = x #[N, H * W + 1, embed_dim]
x = self.attn_norm(x) #Attention LayerNorm
x = self.attn(x) #[N, H * W + 1, embed_dim]
x = h + x #Add
h = x #[N, H * W + 1, embed_dim]
x = self.mlp_norm(x) #MLP LayerNorm
x = self.mlp(x) #[N, H * W + 1, embed_dim]
x = h + x #[Add]
return x
3.2.1 class Attention
class Attention(nn.Layer):
def __init__(self,
embed_dim,
num_heads,
qkv_bias,
dropout,
attention_dropout):
super(Attention, self).__init__()
self.num_heads = num_heads
self.attn_head_size = int(embed_dim / self.num_heads)
self.all_head_size = self.attn_head_size * self.num_heads
self.scales = self.attn_head_size ** -0.5
#calculate qkv
w_attr_1, b_attr_1 = self._init_weights()
self.qkv = nn.Linear(embed_dim,
self.all_head_size * 3, # weight for Q K V
weight_attr = w_attr_1,
bias_attr = b_attr_1 if qkv_bias else False)
#calculate proj
w_attr_2, b_attr_2 = self._init_weights()
self.proj = nn.Linear(embed_dim,
embed_dim,
weight_attr=w_attr_2,
bias_attr=b_attr_2)
self.attn_dropout = nn.Dropout(attention_dropout)
self.proj_dropout = nn.Dropout(dropout)
self.softmax = nn.Softmax(axis=-1)
def _init_weights(self):
weight_attr = paddle.ParamAttr(initializer=nn.initializer.KaimingUniform())
bias_attr = paddle.ParamAttr(initializer=nn.initializer.KaimingUniform())
return weight_attr, bias_attr
def transpose_multihead(self, x):
#input size [N, ~, embed_dim]
new_shape = x.shape[0:2] + [self.num_heads, self.attn_head_size]
#reshape size[N, ~, head, head_size]
x = x.reshape(new_shape)
x = x.transpose([0, 2, 1, 3])
#transpose [N, head, ~, head_size]
return x
def forward(self, x):
#input x = [N, H * W + 1, embed_dim]
qkv = self.qkv(x).chunk(3, axis = -1) #[N, ~, embed_dim * 3] list
q, k, v = map(self.transpose_multihead, qkv) #[N, head, ~, head_size]
attn = paddle.matmul(q, k, transpose_y = True) #[N, head, ~, ~]
attn = self.softmax(attn * self.scales) #softmax(Q*K/(dk^0.5))
attn = self.attn_dropout(attn) #[N, head, ~, ~]
z = paddle.matmul(attn, v) #[N, head, ~, head_size]
z = z.transpose([0, 2, 1, 3]) #[N, ~, head, head_size]
new_shape = z.shape[0:2] + [self.all_head_size]
z = z.reshape(new_shape) #[N, ~, embed_dim]
z = self.proj(z) #[N, ~, embed_dim]
z = self.proj_dropout(z) #[N, ~, embed_dim]
return z
3.2.2 class Mlp
class Mlp(nn.Layer):
def __init__(self,
embed_dim,
mlp_ratio,
dropout):
super(Mlp, self).__init__()
#fc1
w_attr_1, b_attr_1 = self._init_weights()
self.fc1 = nn.Linear(embed_dim,
int(embed_dim * mlp_ratio),
weight_attr = w_attr_1,
bias_attr = b_attr_1)
#fc2
w_attr_2, b_attr_2 = self._init_weights()
self.fc2 = nn.Linear(int(embed_dim * mlp_ratio),
embed_dim,
weight_attr = w_attr_2,
bias_attr = b_attr_2)
self.act = nn.GELU()#GELU > ELU > ReLU > sigmod
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def _init_weights(self):
weight_attr = paddle.ParamAttr(
initializer=paddle.nn.initializer.XavierUniform())
#XavierNormal正态分布的所有层梯度一致,XavierUniform均匀分布的所有成梯度一致。
bias_attr = paddle.ParamAttr(
initializer=paddle.nn.initializer.Normal(std=1e-6)) #正态分布的权值和偏置
return weight_attr, bias_attr
def forward(self, x):
x = self.fc1(x) #[N, ~, embed_dim]
x = self.act(x)
x = self.dropout1(x)
x = self.fc2(x) #[N, ~, embed_dim]
x = self.dropout2(x)
return x
3.3 class Classify
class Classify(nn.Layer):
def __init__(self, embed_dim, dropout, num_classes):
super(Classify, self).__init__()
#fc1
w_attr_1, b_attr_1 = self._init_weights()
self.fc1 = nn.Linear(embed_dim,
embed_dim,
weight_attr = w_attr_1,
bias_attr = b_attr_1)
#fc2
w_attr_2, b_attr_2 = self._init_weights()
self.fc2 = nn.Linear(embed_dim,
num_classes,
weight_attr = w_attr_2,
bias_attr = b_attr_2)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.relu = nn.ReLU()
def _init_weights(self):
weight_attr = paddle.ParamAttr(
initializer=paddle.nn.initializer.KaimingUniform())
bias_attr = paddle.ParamAttr(
initializer=paddle.nn.initializer.KaimingUniform())
return weight_attr, bias_attr
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.dropout1(x)
x = self.fc2(x)
x = self.dropout2(x)
return x
def main():
ins = paddle.randn([1, 3, 224, 224])
model = ViT()
out = model(ins)
print(out.shape)
paddle.summary(model, (1, 3, 224, 224))
if __name__ == "__main__":
x = self.fc2(x)
x = self.dropout2(x)
return x
def main():
ins = paddle.randn([1, 3, 224, 224])
model = ViT()
out = model(ins)
print(out.shape)
paddle.summary(model, (1, 3, 224, 224))
if __name__ == "__main__":
main()
[1, 1000]
----------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
============================================================================
Conv2D-1 [[1, 3, 224, 224]] [1, 768, 14, 14] 590,592
Dropout-1 [[1, 197, 768]] [1, 197, 768] 0
PatchEmbedding-1 [[1, 3, 224, 224]] [1, 197, 768] 152,064
LayerNorm-1 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-1 [[1, 197, 768]] [1, 197, 2304] 1,771,776
Softmax-1 [[1, 12, 197, 197]] [1, 12, 197, 197] 0
Dropout-2 [[1, 12, 197, 197]] [1, 12, 197, 197] 0
Linear-2 [[1, 197, 768]] [1, 197, 768] 590,592
Dropout-3 [[1, 197, 768]] [1, 197, 768] 0
Attention-1 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-2 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-3 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-1 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-4 [[1, 197, 3072]] [1, 197, 3072] 0
Linear-4 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Dropout-5 [[1, 197, 768]] [1, 197, 768] 0
Mlp-1 [[1, 197, 768]] [1, 197, 768] 0
EncoderLayer-1 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-3 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-5 [[1, 197, 768]] [1, 197, 2304] 1,771,776
Softmax-2 [[1, 12, 197, 197]] [1, 12, 197, 197] 0
Dropout-6 [[1, 12, 197, 197]] [1, 12, 197, 197] 0
Linear-6 [[1, 197, 768]] [1, 197, 768] 590,592
Dropout-7 [[1, 197, 768]] [1, 197, 768] 0
Attention-2 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-4 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-7 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-2 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-8 [[1, 197, 3072]] [1, 197, 3072] 0
Linear-8 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Dropout-9 [[1, 197, 768]] [1, 197, 768] 0
Mlp-2 [[1, 197, 768]] [1, 197, 768] 0
EncoderLayer-2 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-5 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-9 [[1, 197, 768]] [1, 197, 2304] 1,771,776
Softmax-3 [[1, 12, 197, 197]] [1, 12, 197, 197] 0
Dropout-10 [[1, 12, 197, 197]] [1, 12, 197, 197] 0
Linear-10 [[1, 197, 768]] [1, 197, 768] 590,592
Dropout-11 [[1, 197, 768]] [1, 197, 768] 0
Attention-3 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-6 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-11 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-3 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-12 [[1, 197, 3072]] [1, 197, 3072] 0
Linear-12 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Dropout-13 [[1, 197, 768]] [1, 197, 768] 0
Mlp-3 [[1, 197, 768]] [1, 197, 768] 0
EncoderLayer-3 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-7 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-13 [[1, 197, 768]] [1, 197, 2304] 1,771,776
Softmax-4 [[1, 12, 197, 197]] [1, 12, 197, 197] 0
Dropout-14 [[1, 12, 197, 197]] [1, 12, 197, 197] 0
Linear-14 [[1, 197, 768]] [1, 197, 768] 590,592
Dropout-15 [[1, 197, 768]] [1, 197, 768] 0
Attention-4 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-8 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-15 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-4 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-16 [[1, 197, 3072]] [1, 197, 3072] 0
Linear-16 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Dropout-17 [[1, 197, 768]] [1, 197, 768] 0
Mlp-4 [[1, 197, 768]] [1, 197, 768] 0
EncoderLayer-4 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-9 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-17 [[1, 197, 768]] [1, 197, 2304] 1,771,776
Softmax-5 [[1, 12, 197, 197]] [1, 12, 197, 197] 0
Dropout-18 [[1, 12, 197, 197]] [1, 12, 197, 197] 0
Linear-18 [[1, 197, 768]] [1, 197, 768] 590,592
Dropout-19 [[1, 197, 768]] [1, 197, 768] 0
Attention-5 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-10 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-19 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-5 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-20 [[1, 197, 3072]] [1, 197, 3072] 0
Linear-20 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Dropout-21 [[1, 197, 768]] [1, 197, 768] 0
Mlp-5 [[1, 197, 768]] [1, 197, 768] 0
EncoderLayer-5 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-11 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-21 [[1, 197, 768]] [1, 197, 2304] 1,771,776
Softmax-6 [[1, 12, 197, 197]] [1, 12, 197, 197] 0
Dropout-22 [[1, 12, 197, 197]] [1, 12, 197, 197] 0
Linear-22 [[1, 197, 768]] [1, 197, 768] 590,592
Dropout-23 [[1, 197, 768]] [1, 197, 768] 0
Attention-6 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-12 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-23 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-6 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-24 [[1, 197, 3072]] [1, 197, 3072] 0
Linear-24 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Dropout-25 [[1, 197, 768]] [1, 197, 768] 0
Mlp-6 [[1, 197, 768]] [1, 197, 768] 0
EncoderLayer-6 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-13 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-25 [[1, 197, 768]] [1, 197, 2304] 1,771,776
Softmax-7 [[1, 12, 197, 197]] [1, 12, 197, 197] 0
Dropout-26 [[1, 12, 197, 197]] [1, 12, 197, 197] 0
Linear-26 [[1, 197, 768]] [1, 197, 768] 590,592
Dropout-27 [[1, 197, 768]] [1, 197, 768] 0
Attention-7 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-14 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-27 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-7 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-28 [[1, 197, 3072]] [1, 197, 3072] 0
Linear-28 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Dropout-29 [[1, 197, 768]] [1, 197, 768] 0
Mlp-7 [[1, 197, 768]] [1, 197, 768] 0
EncoderLayer-7 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-15 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-29 [[1, 197, 768]] [1, 197, 2304] 1,771,776
Softmax-8 [[1, 12, 197, 197]] [1, 12, 197, 197] 0
Dropout-30 [[1, 12, 197, 197]] [1, 12, 197, 197] 0
Linear-30 [[1, 197, 768]] [1, 197, 768] 590,592
Dropout-31 [[1, 197, 768]] [1, 197, 768] 0
Attention-8 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-16 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-31 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-8 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-32 [[1, 197, 3072]] [1, 197, 3072] 0
Linear-32 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Dropout-33 [[1, 197, 768]] [1, 197, 768] 0
Mlp-8 [[1, 197, 768]] [1, 197, 768] 0
EncoderLayer-8 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-17 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-33 [[1, 197, 768]] [1, 197, 2304] 1,771,776
Softmax-9 [[1, 12, 197, 197]] [1, 12, 197, 197] 0
Dropout-34 [[1, 12, 197, 197]] [1, 12, 197, 197] 0
Linear-34 [[1, 197, 768]] [1, 197, 768] 590,592
Dropout-35 [[1, 197, 768]] [1, 197, 768] 0
Attention-9 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-18 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-35 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-9 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-36 [[1, 197, 3072]] [1, 197, 3072] 0
Linear-36 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Dropout-37 [[1, 197, 768]] [1, 197, 768] 0
Mlp-9 [[1, 197, 768]] [1, 197, 768] 0
EncoderLayer-9 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-19 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-37 [[1, 197, 768]] [1, 197, 2304] 1,771,776
Softmax-10 [[1, 12, 197, 197]] [1, 12, 197, 197] 0
Dropout-38 [[1, 12, 197, 197]] [1, 12, 197, 197] 0
Linear-38 [[1, 197, 768]] [1, 197, 768] 590,592
Dropout-39 [[1, 197, 768]] [1, 197, 768] 0
Attention-10 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-20 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-39 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-10 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-40 [[1, 197, 3072]] [1, 197, 3072] 0
Linear-40 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Dropout-41 [[1, 197, 768]] [1, 197, 768] 0
Mlp-10 [[1, 197, 768]] [1, 197, 768] 0
EncoderLayer-10 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-21 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-41 [[1, 197, 768]] [1, 197, 2304] 1,771,776
Softmax-11 [[1, 12, 197, 197]] [1, 12, 197, 197] 0
Dropout-42 [[1, 12, 197, 197]] [1, 12, 197, 197] 0
Linear-42 [[1, 197, 768]] [1, 197, 768] 590,592
Dropout-43 [[1, 197, 768]] [1, 197, 768] 0
Attention-11 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-22 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-43 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-11 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-44 [[1, 197, 3072]] [1, 197, 3072] 0
Linear-44 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Dropout-45 [[1, 197, 768]] [1, 197, 768] 0
Mlp-11 [[1, 197, 768]] [1, 197, 768] 0
EncoderLayer-11 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-23 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-45 [[1, 197, 768]] [1, 197, 2304] 1,771,776
Softmax-12 [[1, 12, 197, 197]] [1, 12, 197, 197] 0
Dropout-46 [[1, 12, 197, 197]] [1, 12, 197, 197] 0
Linear-46 [[1, 197, 768]] [1, 197, 768] 590,592
Dropout-47 [[1, 197, 768]] [1, 197, 768] 0
Attention-12 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-24 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-47 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-12 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-48 [[1, 197, 3072]] [1, 197, 3072] 0
Linear-48 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Dropout-49 [[1, 197, 768]] [1, 197, 768] 0
Mlp-12 [[1, 197, 768]] [1, 197, 768] 0
EncoderLayer-12 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-25 [[1, 197, 768]] [1, 197, 768] 1,536
Encoder-1 [[1, 197, 768]] [1, 197, 768] 0
Linear-49 [[1, 768]] [1, 768] 590,592
ReLU-1 [[1, 768]] [1, 768] 0
Dropout-50 [[1, 768]] [1, 768] 0
Linear-50 [[1, 768]] [1, 1000] 769,000
Dropout-51 [[1, 1000]] [1, 1000] 0
Classify-1 [[1, 768]] [1, 1000] 0
============================================================================
Total params: 87,158,248
Trainable params: 87,158,248
Non-trainable params: 0
----------------------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 423.52
Params size (MB): 332.48
Estimated Total Size (MB): 756.57
----------------------------------------------------------------------------
智能推荐
Spring Boot 获取 bean 的 3 种方式!还有谁不会?,Java面试官_springboot2.7获取bean-程序员宅基地
文章浏览阅读1.2k次,点赞35次,收藏18次。AutowiredPostConstruct 注释用于在依赖关系注入完成之后需要执行的方法上,以执行任何初始化。此方法必须在将类放入服务之前调用。支持依赖关系注入的所有类都必须支持此注释。即使类没有请求注入任何资源,用 PostConstruct 注释的方法也必须被调用。只有一个方法可以用此注释进行注释。_springboot2.7获取bean
Logistic Regression Java程序_logisticregression java-程序员宅基地
文章浏览阅读2.1k次。理论介绍 节点定义package logistic;public class Instance { public int label; public double[] x; public Instance(){} public Instance(int label,double[] x){ this.label = label; th_logisticregression java
linux文件误删除该如何恢复?,2024年最新Linux运维开发知识点-程序员宅基地
文章浏览阅读981次,点赞21次,收藏18次。本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。下面我们来进行文件的恢复,执行下文中的lsof命令,在其返回结果中我们可以看到test-recovery.txt (deleted)被删除了,但是其存在一个进程tail使用它,tail进程的进程编号是1535。我们看到文件名为3的文件,就是我们刚刚“误删除”的文件,所以我们使用下面的cp命令把它恢复回去。命令进入该进程的文件目录下,1535是tail进程的进程id,这个文件目录里包含了若干该进程正在打开使用的文件。
流媒体协议之RTMP详解-程序员宅基地
文章浏览阅读10w+次,点赞12次,收藏72次。RTMP(Real Time Messaging Protocol)实时消息传输协议是Adobe公司提出得一种媒体流传输协议,其提供了一个双向得通道消息服务,意图在通信端之间传递带有时间信息得视频、音频和数据消息流,其通过对不同类型得消息分配不同得优先级,进而在网传能力限制下确定各种消息得传输次序。_rtmp
微型计算机2017年12月下,2017年12月计算机一级MSOffice考试习题(二)-程序员宅基地
文章浏览阅读64次。2017年12月的计算机等级考试将要来临!出国留学网为考生们整理了2017年12月计算机一级MSOffice考试习题,希望能帮到大家,想了解更多计算机等级考试消息,请关注我们,我们会第一时间更新。2017年12月计算机一级MSOffice考试习题(二)一、单选题1). 计算机最主要的工作特点是( )。A.存储程序与自动控制B.高速度与高精度C.可靠性与可用性D.有记忆能力正确答案:A答案解析:计算...
20210415web渗透学习之Mysqludf提权(二)(胃肠炎住院期间转)_the provided input file '/usr/share/metasploit-fra-程序员宅基地
文章浏览阅读356次。在学MYSQL的时候刚刚好看到了这个提权,很久之前用过别人现成的,但是一直时间没去细想, 这次就自己复现学习下。 0x00 UDF 什么是UDF? UDF (user defined function),即用户自定义函数。是通过添加新函数,对MySQL的功能进行扩充,就像使..._the provided input file '/usr/share/metasploit-framework/data/exploits/mysql
随便推点
webService详细-程序员宅基地
文章浏览阅读3.1w次,点赞71次,收藏485次。webService一 WebService概述1.1 WebService是什么WebService是一种跨编程语言和跨操作系统平台的远程调用技术。Web service是一个平台独立的,低耦合的,自包含的、基于可编程的web的应用程序,可使用开放的XML(标准通用标记语言下的一个子集)标准...
Retrofit(2.0)入门小错误 -- Could not locate ResponseBody xxx Tried: * retrofit.BuiltInConverters_已添加addconverterfactory 但是 could not locate respons-程序员宅基地
文章浏览阅读1w次。前言照例给出官网:Retrofit官网其实大家学习的时候,完全可以按照官网Introduction,自己写一个例子来运行。但是百密一疏,官网可能忘记添加了一句非常重要的话,导致你可能出现如下错误:Could not locate ResponseBody converter错误信息:Caused by: java.lang.IllegalArgumentException: Could not l_已添加addconverterfactory 但是 could not locate responsebody converter
一套键鼠控制Windows+Linux——Synergy在Windows10和Ubuntu18.04共控的实践_linux 18.04 synergy-程序员宅基地
文章浏览阅读1k次。一套键鼠控制Windows+Linux——Synergy在Windows10和Ubuntu18.04共控的实践Synergy简介准备工作(重要)Windows服务端配置Ubuntu客户端配置配置开机启动Synergy简介Synergy能够通过IP地址实现一套键鼠对多系统、多终端进行控制,免去了对不同终端操作时频繁切换键鼠的麻烦,可跨平台使用,拥有Linux、MacOS、Windows多个版本。Synergy应用分服务端和客户端,服务端即主控端,Synergy会共享连接服务端的键鼠给客户端终端使用。本文_linux 18.04 synergy
nacos集成seata1.4.0注意事项_seata1.4.0 +nacos 集成-程序员宅基地
文章浏览阅读374次。写demo的时候遇到了很多问题,记录一下。安装nacos1.4.0配置mysql数据库,新建nacos_config数据库,并根据初始化脚本新建表,使配置从数据库读取,可单机模式启动也可以集群模式启动,启动时 ./start.sh -m standaloneapplication.properties 主要是db部分配置## Copyright 1999-2018 Alibaba Group Holding Ltd.## Licensed under the Apache License,_seata1.4.0 +nacos 集成
iperf3常用_iperf客户端指定ip地址-程序员宅基地
文章浏览阅读833次。iperf使用方法详解 iperf3是一款带宽测试工具,它支持调节各种参数,比如通信协议,数据包个数,发送持续时间,测试完会报告网络带宽,丢包率和其他参数。 安装 sudo apt-get install iperf3 iPerf3常用的参数: -c :指定客户端模式。例如:iperf3 -c 192.168.1.100。这将使用客户端模式连接到IP地址为192.16..._iperf客户端指定ip地址
浮点性(float)转化为字符串类型 自定义实现和深入探讨C++内部实现方法_c++浮点数 转 字符串 精度损失最小-程序员宅基地
文章浏览阅读7.4k次。 写这个函数目的不是为了和C/C++库中的函数在性能和安全性上一比高低,只是为了给那些喜欢探讨函数内部实现的网友,提供一种从浮点性到字符串转换的一种途径。 浮点数是有精度限制的,所以即使我们在使用C/C++中的sprintf或者cout 限制,当然这个精度限制是可以修改的。比方在C++中,我们可以cout.precision(10),不过这样设置的整个输出字符长度为10,而不是特定的小数点后1_c++浮点数 转 字符串 精度损失最小