有Mysql数据库的情况下为什么要用Hive数据库?-程序员宅基地
有Mysql数据库的情况下为什么要用Hive?
最近接到公司的一个需求,要求使用Hive做数据查询。当时第一反应就是What?Hive是什么鬼?一脸懵逼状。(请原谅一个刚开始实习的Java实习生见识短浅)然后发现了hive的一些问题。下面简单介绍一下Hive。
网上对于hive与mysql的区别的文章也不是很多。so只能问问公司大牛们,看看他们是怎样理解的。
由于 Hive 采用了 SQL 的查询语言 HQL,因此很容易将 Hive 理解为数据库。其实 从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处。
数据库可以用在 Online 的应用中,但是 Hive 是为数据仓库而设计的,清楚这一点,有助于从应用角度理解 Hive 的特性。
一、Hive是一个基于Hadoop的数据仓库平台。通过hive,我们可以方便地进行ETL的工作。hive定义了一个类似于SQL的查询语言:HQL,能 够将用户编写的QL转化为相应的Mapreduce程序基于Hadoop执行。
Hive是Facebook 2008年8月刚开源的一个数据仓库框架,其系统目标与 Pig 有相似之处,但它有一些Pig目前还不支持的机制,比如:更丰富的类型系统、更类似SQL的查询语言、Table/Partition元数据的持久化等。
Hive 可以看成是从SQL到Map-Reduce的 映射器
Hive的数据放在哪儿?
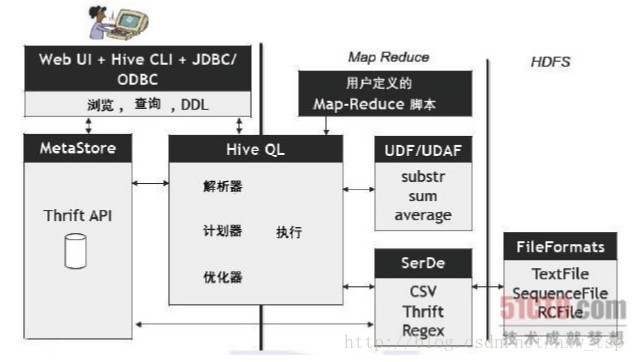
数据在HDFS的warehouse目录下,一个表对应一个子目录。
本地的/tmp目录存放日志和执行计划
hive的表分为两种,内表和外表。
Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。
在删除表的时候,内部表的元数据和数据会被一起删除, 而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
使用Mysql作为Hive metaStore的存储数据库
其中主要涉及到的表如下:
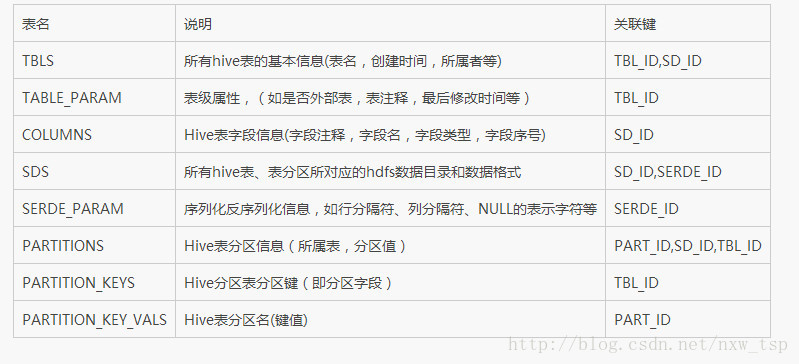
但是对于一个菜鸟来说,看完这些还是有点云里雾里。
下面来看他们的异同。
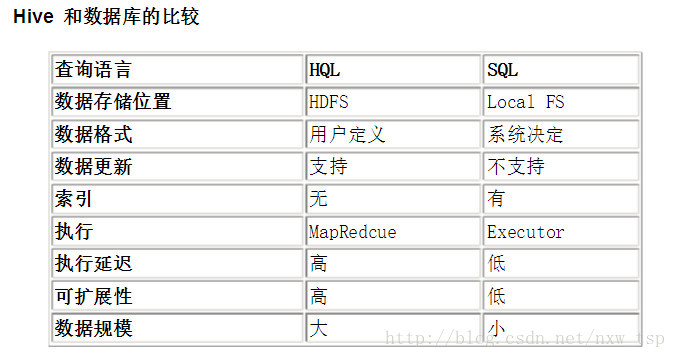
查询语言。由于 SQL 被广泛的应用在数据仓库中,因此,专门针对 Hive 的特性设计了类 SQL 的查询语言 HQL。熟悉 SQL 开发的开发者可以很方便的使用 Hive 进行开发。
数据存储位置。Hive 是建立在 Hadoop 之上的,所有 Hive 的数据都是存储在 HDFS 中的。而数据库 则可以将数据保存在本地文件系统中。
数据格式。Hive 中没有定义专门的数据格式,数据格式可以由用户指定,用户定义数据格式需要指定三 个属性:列分隔符(通常为空格、”\t”、”\x001″)、行分隔符(”\n”)以及读取文件数据的方法(Hive 中默认有三个文件格式 TextFile,SequenceFile 以及 RCFile)。由于在加载数据的过程中,不需要从用户数据格式到 Hive 定义的数据格式的转换,因此,Hive 在加载的过程中不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的 HDFS 目录中。而在数据库中,不同的数据库有不同的存储引擎,定义了自己的数据格式。所有数据都会按照一定的组织存储,因此,数据库加载数据的过程会比较耗时。
数据更新。由于 Hive 是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive 中不 支持对数据的改写和添加,所有的数据都是在加载的时候中确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用 INSERT INTO … VALUES 添加数据,使用 UPDATE … SET 修改数据。
索引。之前已经说过,Hive 在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描, 因此也没有对数据中的某些 Key 建立索引。Hive 要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。由于 MapReduce 的引入, Hive 可以并行访问数据,因此即使没有索引,对于大数据量的访问,Hive 仍然可以体现出优势。数据库中,通常会针对一个或者几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了 Hive 不适合在线数据查询。
执行。Hive 中大多数查询的执行是通过 Hadoop 提供的 MapReduce 来实现的(类似 select * from tbl 的查询不需要 MapReduce)。而数据库通常有自己的执行引擎。
执行延迟。之前提到,Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外 一个导致 Hive 执行延迟高的因素是 MapReduce 框架。由于 MapReduce 本身具有较高的延迟,因此在利用 MapReduce 执行 Hive 查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive 的并行计算显然能体现出优势。
可扩展性。由于 Hive 是建立在 Hadoop 之上的,因此 Hive 的可扩展性是和 Hadoop 的可扩展性是 一致的(世界上最大的 Hadoop 集群在 Yahoo!,2009年的规模在 4000 台节点左右)。而数据库由于 ACID 语义的严格限制,扩展行非常有限。目前最先进的并行数据库 Oracle 在理论上的扩展能力也只有 100 台左右。
数据规模。由于 Hive 建立在集群上并可以利用 MapReduce 进行并行计算,因此可以支持很大规模的 数据;对应的,数据库可以支持的数据规模较小。
看了这些,我说为什么hive查询数据怎么这么慢呢。
最后再来一下数据库和数据仓储的区别。
> 数据库是面向事务的设计,数据仓库是面向主题设计的。 数据库一般存储在线交易数据,数据仓库存储的一般是历史数据。
> 数据库设计是尽量避免冗余,一般采用符合范式的规则来设计,数据仓库在设计是有意引入冗余,采用反范式的方式来设计。
> 数据库是为捕获数据而设计,数据仓库是为分析数据而设计,它的两个基本的元素是维表和事实表。(维是看问题的角度,比如时间,部门,维表放的就是这些东西的定义,事实表里放着要查询的数据,同时有维的ID)
以上文章部分内容来自与网络。
智能推荐
20、NanoDet训练、测试 以及使用ncnn部署Jetson Nano 进行目标检测和串口数据转发-程序员宅基地
文章浏览阅读6.5k次,点赞7次,收藏59次。基本思想:最近想尝试一下nano 上部署nanodet,于是记录一下训练过程,手中有一份labelme标注的数据集,于是开始了一波操作~首先将图片和json数据集转成xml (https://blog.csdn.net/sxj731533730/article/details/90046780),然后将xml数据集转成voc;import sysimport osimport jsonimport xml.etree.ElementTree as ETfrom PIL import Im_nanodet
code::blocks + wxWidgets 2.8 在ubuntu 10.04下的安装-程序员宅基地
文章浏览阅读930次。code::blocks + wxWidgets 2.8 在ubuntu 10.04下的安装p { margin-bottom: 0.21cm; }1、首先安装必要组件代码:安装编译器 sudo apt-get install build-essential
用java Swing做的小游戏"像素鸟"_java swing小游戏-程序员宅基地
文章浏览阅读4.4k次,点赞10次,收藏38次。最终效果 整个项目都是基于swing实现的。窗是口将图片加载到JPanel面板,然后将面板添加到到JFrame窗口实现显示。这个类是选择几只像素鸟的类,也是main函数里执行的方法,代码有详细的注释,这里就不废话了public class select extends JPanel { /** * */ private static final long serialVersio..._java swing小游戏
三分钟教你读懂支票是什么_支票的原理是什么-程序员宅基地
文章浏览阅读8.7k次。三分钟教你读懂支票是什么支票1、支票的概念及特点支票:出票人签发的,委托办理支票存款业务的银行或其他金融机构在见票时无条件支付确定金额给收款人或持票人的票据。支票必填项:支票字样、确定的金额、出票日期、无条件支付委托、付款人名称、出票人签章。支票选填项:付款地、出票地。支票结算特点:(1)简便,手续_支票的原理是什么
山东工商学院 计算机科学与技术,实验中心-山东工商学院计算机科学与技术学院...-程序员宅基地
文章浏览阅读148次。计算机教学实验中心成立于1999年,隶属计算机科学与技术学院。实验中心现有软件、电子、网络、通信、大学生科技创新、AR技术研究所等41间实验室,实验面积5600平方米,固定资产3500万元,教(职)工26人。实验中心以先进精良的设备条件、整洁舒适的教学环境、科学严谨的管理方式为计算机科学与技术学院、信息与电子工程学院、管理科学与工程学院等学院的实验教学、课程设计、毕业设计等实践环节和全院计算机公共..._计算机科学与技术实验教学中心 山东
CUDA ERROR: device-side assert triggered at 问题及解决思路-程序员宅基地
文章浏览阅读10w+次,点赞45次,收藏82次。cuda errorRuntimeError: cuda runtime error (59) : device-side assert triggered at ...我之前还以为是因为GPU抽风了引发的BUG,所以第一次没有在意,直接又重新开始运行了一次,但是第二次就发现程序在同样的地方断掉了,这也就想起来我以前看到的一个博客,里面有句话的大概意思是这样的:每次都在同样的地方出错的..._cuda error: device-side assert triggered
随便推点
Vue简明实用教程(04)——事件处理_vue html里面如何直接写事件函数-程序员宅基地
文章浏览阅读1.1k次,点赞4次,收藏5次。在Vue中可非常便利地进行事件处理,例如:点击事件、鼠标悬停事件等。_vue html里面如何直接写事件函数
南京邮电大学离散数学实验一(求主析取和主合取范式)-程序员宅基地
文章浏览阅读4.5k次,点赞15次,收藏67次。南京邮电大学离散数学实验一(求主析取和主合取范式)_离散数学实验
{spring.cloud.client.ipAddress}_spring.cloud.client.ip-address-程序员宅基地
文章浏览阅读1.5w次,点赞2次,收藏5次。1.在springcloud中服务的 Instance ID 默认值是:${spring.cloud.client.hostname}:${spring.application.name}:${spring.application.instance_id:${server.port}},也就是:主机名:应用名:应用端口。如图12.可以自定义:eureka.instance...._spring.cloud.client.ip-address
单目标跟踪OTB、VOT数据集介绍_otb数据集官网-程序员宅基地
文章浏览阅读2.1w次,点赞6次,收藏63次。OTB分为:OTB50和OTB100官方下载链接为:OTB官方数据集网站http://cvlab.hanyang.ac.kr/tracker_benchmark/datasets.html百度云链接:链接:https://pan.baidu.com/s/1Ck51d7OQ8w8BGcTL9UtopA提取码:jn0k复制这段内容后打开百度网盘手机App,操作更方便哦其中50和100,分别..._otb数据集官网
Xcode修改模拟器Simulator系统版本_xcode模拟器切换ios版本-程序员宅基地
文章浏览阅读5.1k次。从Xcode菜单栏里打开Xcode -> Preferences -> Components -> Simulators,下载对应版本的模拟器。由于模拟器相关文件较大,下载时间较长,需要耐心等待,下载完成后,对应版本的模拟器前面的下载按钮就会变成下载完成的样式。点击Xcode菜单栏 Window -> Devices,然后可以看到设备列表,然而在模拟器列表(..._xcode模拟器切换ios版本
chatgpt赋能python:Python如何分离CSV的列_python的csv拆列-程序员宅基地
文章浏览阅读270次。CSV文件是一种以逗号或其他分隔符分隔的文件格式,用于存储表格数据。它可以用任何文本编辑器打开,并且非常适合在电子表格程序(例如Microsoft Excel或Google Sheets)中打开和处理。CSV文件通常由一组记录组成,每条记录包含一个或多个字段。字段之间使用逗号或其他指定的分隔符分隔。CSV文件中的第一行通常包含列标题,这些标题描述了每个字段的含义。Jack,19,UK本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。_python的csv拆列