Microsoft SQL Server数据库部署过程-程序员宅基地
技术标签: python java mysql 数据库 大数据
介绍 (Introduction)
Database deployments are critical tasks that can affect negative in on performance in production. In this article we’ll describe some performance related best practices for database deployments.
数据库部署是关键任务,可能会影响生产性能。 在本文中,我们将介绍一些与性能相关的数据库部署最佳实践。
In this article, I’ll cover several aspects of Microsoft SQL Server databases deployment process including :
在本文中,我将介绍Microsoft SQL Server数据库部署过程的几个方面, 包括 :
- Database deployment prerequisites 数据库部署先决条件
- Database Schema design assessments 数据库架构设计评估
- Database stress tests 数据库压力测试
- Application stress tests 应用压力测试
- Database index analysis 数据库索引分析
先决条件 (Prerequisites)
The first thing we should do is to collect some fundamental information about this new database to be familiar with the business logic of it, usage, capacity plan, etc. The following are some examples
我们应该做的第一件事是收集有关此新数据库的一些基本信息,以熟悉该数据库的业务逻辑,用法,容量计划等。 以下是一些例子
- Is there any field(s) in this database that contains(s) XML or Binary information? IF << YES >> we need a bit more clarity about the usage type of those data entities,
- Are they used as transactional or lookup data entities?
- If transactional, are there any reports to be generated from XML
- What is the maximum expected number of records for further one year?
- 此数据库中是否有包含XML或二进制信息的字段 ? 如果 《 是 》,我们需要进一步了解这些数据实体的使用类型,
- 它们是否用作事务或查找数据实体?
- 如果是事务性的,是否有任何要从XML生成的报告
- 未来一年的最大预期记录数是多少?
- Are there any special configuration(s) that should be considered during the deployment such as: 任何特殊配置 ,例如:
- DTC (Distributed Transaction Coordinator) DTC(分布式事务处理协调器)
- Service Broker 服务经纪人
- CLR and assembly, if so what type of assembly, external access, unsafe, safe are supported by GAC (Global assembly cache) or it might need any other external Common Language Runtime modules or PowerShell files? CLR和程序集,如果是这样,GAC(全局程序集缓存)支持哪种类型的程序集,外部访问,不安全,安全?或者它可能需要任何其他外部公共语言运行时模块或PowerShell文件?
- RCSI (Read Committed Snapshot Isolation level) RCSI(读取提交的快照隔离级别)
- Encryption and if so what kind of encryption algorithms used 加密,如果使用的话,使用哪种加密算法
- What is the key provisioning used there, I mean what DMK, Certificate, asymmetric key, etc. ? 那里使用的密钥配置是什么,我的意思是什么DMK,证书,非对称密钥等?
- Elevated privileges for application service account? 应用程序服务帐户的特权提升了吗?
- Certain data engineering solution like data archiving, data migration, data cleansing jobs? 某些数据工程解决方案,例如数据归档,数据迁移,数据清理作业?
- Special scheduled jobs to send reports or do some DML operations? 用于发送报告的特殊计划作业或执行某些DML操作?
- SSRS (SQL Server Reporting service) Reports? if so please mentioned their URLs and grant content manager privileges for us SSRS(SQL Server报告服务)报告? 如果是这样,请提及他们的网址并为我们授予内容管理员权限
- Any existing OLAP cubes or BI solution? 任何现有的OLAP多维数据集或BI解决方案?
- Linked server or distributed queries 链接服务器或分布式查询
- Replication or transaction log shipping with other Databases on other servers? 与其他服务器上的其他数据库一起提供复制或事务日志?
- Any direct access from outside by any other users or systems? 其他用户或系统是否可以从外部直接访问?
- What the AD (Active Directory user) that will be Application services account? 什么是AD(Active Directory用户)将成为应用程序服务帐户?
- What the application server (Name/IP)? To open the SQL port with it 什么是应用程序服务器(名称/ IP)? 用它打开SQL端口
These provide a good set of example checks to help conclude the Database size, usage, requirements, configuration etc
这些提供了一组很好的示例检查,以帮助总结数据库的大小,用法,要求,配置等
分析 (Analysis)
Before we start we should do a pre-deployment analysis of potential performance issues including:
在开始之前,我们应该对潜在的性能问题进行部署前分析,其中包括:
- Database Schema Design review 数据库架构设计审查
- Stored procedures Stress tests 存储过程压力测试
- Application Stress tests 应用压力测试
- Index analysis 指标分析
数据库架构设计审查 (Database schema design review)
The following are some example
以下是一些示例
- What are the fields and objects we should check? 我们应该检查哪些字段和对象?
- What is the performance risks that we should keep in mind while designing the database deployment process, for example: 在设计数据库部署过程时应牢记的性能风险是什么,例如:
- Columns data types should be appropriate for the usage of this column. Therefore Nvarchar (列数据类型应适合于此列的用法。 因此,Nvarchar( MAX) or Varchar (MAX )或Varchar( MAX) are generally inappropriate because we can’t include them by any index because the index has size limitation MAX )通常是不合适的,因为我们不能在任何索引中包含它们,因为索引的大小限制为900 900 bytes and these columns store more than 字节,并且这些列存储了8000 bytes. 8000字节以上。
SELECT TABLE_NAME,
COLUMN_NAME ,
DATA_TYPE + ' (MAX)' AS DATA_TYPE
FROM INFORMATION_SCHEMA.COLUMNS INFO INNER JOIN Sys.Tables T
ON Info.TABLE_NAME = T.name
WHERE Info.CHARACTER_MAXIMUM_LENGTH = '-1'
AND DATA_TYPE NOT IN ( 'text', 'Image', 'Ntext', 'FILESTREAM', 'Xml',
'varbinary' )
ORDER BY TABLE_NAME
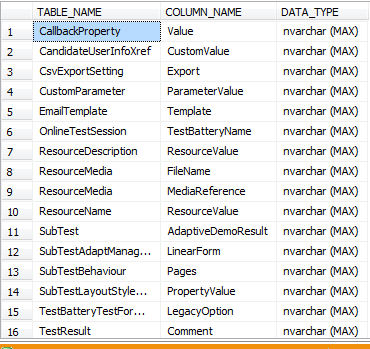
- BOLB and XML Columns: Check the columns with data types Text, Image, Next, FILESTREAM, XML, varbinary} as ideally, we ought to avoid these, unless absolutely needed BOLB和XML列:理想情况下,检查数据类型为Text,Image,Next,FILESTREAM,XML,varbinary}的列,除非绝对需要,否则应避免使用这些列
WITH schema_design AS
(
SELECT
info.TABLE_CATALOG ,
--SCHEMA_NAME(schema_id) AS [SCHEMA_Name],
info.TABLE_SCHEMA as TABLE_SCHEMA,
--'['+SCHEMA_NAME(schema_id)+'].['+T.name+']' as TABLE_NAME,
Info.TABLE_NAME,
info.COLUMN_NAME,
INfo.DATA_TYPE,
Info.COLLATION_NAME,
INfo.CHARACTER_MAXIMUM_LENGTH,
INfo.CHARACTER_OCTET_LENGTH,
C.is_computed,
C.is_filestream
,C.is_identity,
COLUMNPROPERTY(object_id(TABLE_NAME),
COLUMN_NAME, 'IsIdentity')AS IsIdentity,
COLUMNPROPERTY(object_id(TABLE_NAME), COLUMN_NAME, 'IsPrimaryKey')AS IsPrimaryKey
from Sys.Columns as C
inner join INFORMATION_SCHEMA.COLUMNS info
on info.TABLE_NAME = OBJECT_NAME(C.Object_Id)
and Info.COLUMN_NAME = C.name
--Select Distinct Info.Table_Name,Info.TABLE_CATALOG from INFORMATION_SCHEMA.COLUMNS info
Inner Join Sys.Tables T
On Info.TABLE_NAME = T.name
)
SELECT * FROM schema_design
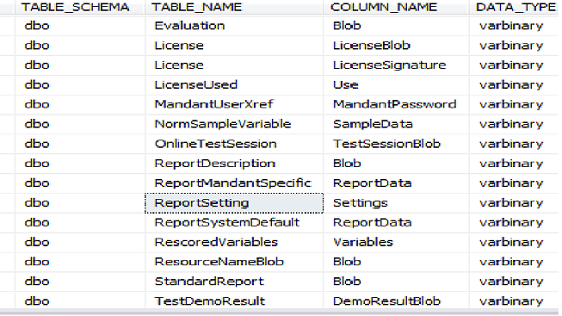
WHERE DATA_TYPE IN ('text' , 'Image','Ntext','FILESTREAM','Xml','varbinary','sql_variant')
ORDER BY TABLE_NAME
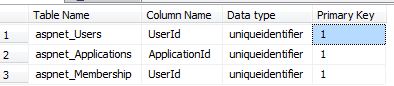
Uniqueidentifier Columns AS primary key: is not preferred for many reasons
Uniqueidentifier Columns AS主键:由于许多原因,不被首选
- GUID is 16 byte but the INT columns is 4 byte so the GUID will be required to have more read and write logical reads apart from the storage requirements which GUIDs require more. GUID为16字节,但INT列为4字节,因此除了GUID需要更多的存储要求之外,GUID还需要具有更多的读取和写入逻辑读取。
- If we use the GUID as clustered index for every insert we should change the layout of the data as it is not like the Identity INT columns 如果我们将GUID用作每个插入的聚簇索引,则应更改数据的布局,因为它与Identity INT列不同
For better results, consider using integer identity columns. Or at least newsequentialid() instead of a Primary Key on GUID
为了获得更好的结果,请考虑使用整数标识列。 至少是newsequentialid()而不是GUID上的主键
WITH CTE
AS ( SELECT S.name AS [Table Name] ,
c.name 'Column Name' ,
t.name 'Data type' ,
ISNULL(i.is_primary_key, 0) 'Primary Key'
FROM sys.columns c
INNER JOIN sys.types t ON c.user_type_id = t.user_type_id
INNER JOIN sys.tables S ON S.object_id = c.object_id
LEFT OUTER JOIN sys.index_columns ic ON ic.object_id = c.object_id
AND ic.column_id = c.column_id
LEFT OUTER JOIN sys.indexes i ON ic.object_id = i.object_id
AND ic.index_id = i.index_id
)
SELECT *
FROM CTE
WHERE [Data type] = 'uniqueidentifier'
AND CTE.[Primary Key] = 1;
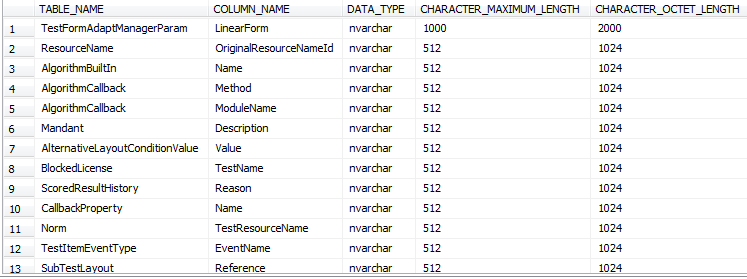
- Columns size : the columns should be created with most suitable size to be able to cover it by the index model, An index key length is 900 byte. If we assume we have column NVARCHAR (500) the actual size is 1000 byte and if we created any index with key columns size > 900 bytes it would impact on the OLTP transaction, and it will show for us the below warning:
The maximum key length is 900 bytes. The index has a maximum length of 1200 bytes. For some combination of large values, the insert/update operation will fail
- 列大小:索引的创建应使用最合适的大小,以使其能够被索引模型覆盖。索引键的长度为900字节。 如果我们假设我们有NVARCHAR列(500),则实际大小为1000字节,并且如果我们创建的任何索引的键列大小> 900字节,都会影响OLTP事务,并为我们显示以下警告:
最大密钥长度为900字节。 索引的最大长度为1200个字节。 对于大值的某些组合,插入/更新操作将失败
SELECT TABLE_NAME ,
COLUMN_NAME ,
DATA_TYPE ,
CHARACTER_MAXIMUM_LENGTH ,
CHARACTER_OCTET_LENGTH
FROM INFORMATION_SCHEMA.COLUMNS INFO
INNER JOIN Sys.tables T ON INFO.TABLE_NAME = T.Name
WHERE Info.CHARACTER_MAXIMUM_LENGTH > '256'
AND Data_type NOT IN ( 'text', 'Image', 'Ntext', 'FILESTREAM', 'Xml',
'varbinary' )
ORDER BY CHARACTER_MAXIMUM_LENGTH DESC
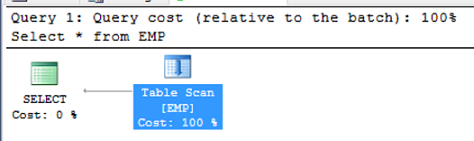
- Heap Tables: This means the tables without primary key or clustered indexes, and these kinds of tables should be not accepted because they will generate extremely poor SQL Server Execution Plans for queries trying to get the data from the application. 堆表:这意味着没有主键或聚集索引的表,并且不应接受此类表,因为它们会为试图从应用程序中获取数据的查询生成极差SQL Server执行计划。
Attached is a Stored Procedure “Check_Heap_Tables” and this SQL Server Stored Procedure will generate a T-SQL script for each Database and Table which is Heap Table and it will print out the required clustered index to be created for highlighted tables.
附加的是存储过程“ Check_Heap_Tables ” ,此SQL Server存储过程将为每个数据库和表(即堆表)生成一个T-SQL脚本,并将打印出要为突出显示的表创建的聚簇索引。
Use MSDatabase
Go
Exec dbo.[Check_Heap_Tables]
存储过程压力测试 (Stored procedures stress test)
In this second phase our main focus in the most used stored procedures that we should execute it on 200 concurrent user minimum and 1000 concurrent user maximum for the purpose of stress testing the Application Level Stored Procedures for performance testing.
在第二阶段,我们主要关注最常用的存储过程,我们应该在200个并发用户数和1000个并发用户数上执行它,以便对应用程序级存储过程进行压力测试以进行性能测试。
We can do this process by utilizing any stress tool, but we should fill the tables by at least 1 million of rows. In our case we’ll use ApexSQL Generate to help us highlight any potential issues via the query execution plan
我们可以通过使用任何压力工具来完成此过程,但我们应该至少在表中填充100万行。 在我们的案例中,我们将使用ApexSQL Generate通过查询执行计划帮助我们突出显示任何潜在的问题
Although there are multiple ways to tune-up TSQL some examples given below:
尽管有多种方法可以调整TSQL,但下面给出了一些示例:
- Use table hint {MAXDOP, FAST, Keep FixdPlan, Set Nocount on, With Nolock , Index forceseek ..Etc} 使用表提示{MAXDOP,FAST,保持FixdPlan,设置Nocount处于打开状态,具有Nolock,索引forceeek ..Etc}
- Create sufficient indexes to reduce the IO and CPU 创建足够的索引以减少IO和CPU
- Use dynamic queries 使用动态查询
应用压力测试 (Application stress test)
Most recently, many applications use Entity Framework at the application layer to access the database. This Framework does not allow the queries to be written directly; instead it generates queries on its own as required by the application and business logic based on the underlying tables. So, the database does not have the business logic inside the SQL Server.
最近,许多应用程序在应用程序层使用实体框架来访问数据库。 该框架不允许直接编写查询。 相反,它根据基础表根据应用程序和业务逻辑的要求自行生成查询。 因此,数据库在SQL Server内部没有业务逻辑。
For optimizing and stress testing the code we need to capture the business logic code by running stress test scenarios for like 200~300 concurrent users. And ultimately able to capture poorly written or worst performing TSQL.
为了优化和压力测试代码,我们需要通过为200〜300个并发用户运行压力测试方案来捕获业务逻辑代码。 最终能够捕获写得不好或性能最差的TSQL。
Eventually, the goal here is to get the bad TSQL in hand and optimize it and give it back to the application team so that they can integrate it and merge inside the application for optimizing the business by converting the queries into SQL Server Custom Written Stored Procedures.
最终,这里的目标是掌握不良的TSQL并对其进行优化并将其返回给应用程序团队,以便他们可以将其集成并合并到应用程序内部,以通过将查询转换为SQL Server自定义书面存储过程来优化业务。 。
指标分析 (Index Analysis)
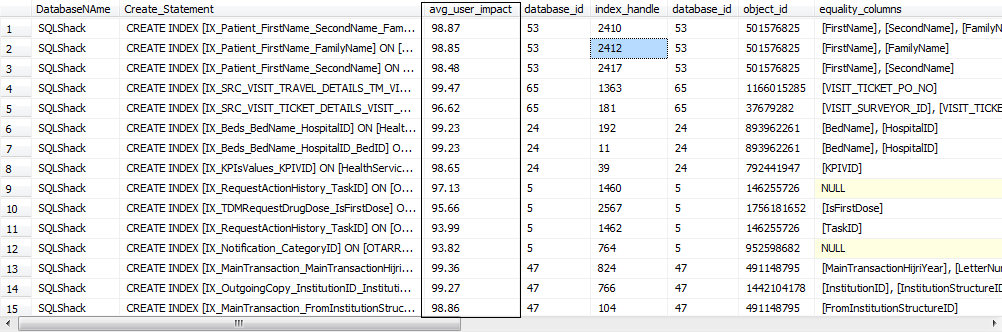
After all of the stress testing performed on the database for potential problematic Stored Procedures and T-SQL queries, SQL Server engine will save the required missing indexes in the system tables which we can now query.
在对数据库执行了所有潜在的有问题的存储过程和T-SQL查询的压力测试之后,SQL Server引擎会将所需的缺失索引保存在我们现在可以查询的系统表中。
After analyzing the Missing Indexes from the System Stored Procedures, we can start to create the appropriate missing indexes on the tables. This process should be done only by experienced DatabaseAs and in collaboration with the Development team to enhance the performance of the poorly performing quires and Stored Procedures.
在分析了系统存储过程中的缺失索引之后,我们可以开始在表上创建适当的缺失索引。 此过程仅应由经验丰富的DatabaseA并与开发团队合作完成,以提高性能不佳的查询和存储过程的性能。
SELECT B.name AS DatabaseNAme,D.database_id,D.* ,
s.avg_total_user_cost ,
s.avg_user_impact ,
s.last_user_seek ,
s.last_user_scan ,
s.unique_compiles ,
'CREATE INDEX [IX_' + OBJECT_NAME(d.object_id, d.database_id) + '_'
+ REPLACE(REPLACE(REPLACE(ISNULL(d.equality_columns, ''), ', ', '_'),
'[', ''), ']', '')
+ CASE WHEN d.equality_columns IS NOT NULL
AND d.inequality_columns IS NOT NULL THEN '_'
ELSE ''
END + REPLACE(REPLACE(REPLACE(ISNULL(d.inequality_columns, ''), ', ',
'_'), '[', ''), ']', '') + ']'
+ ' ON ' + d.statement + ' (' + ISNULL(d.equality_columns, '')
+ CASE WHEN d.equality_columns IS NOT NULL
AND d.inequality_columns IS NOT NULL THEN ','
ELSE ''
END + ISNULL(d.inequality_columns, '') + ')' + ISNULL(' INCLUDE ('
+ d.included_columns
+ ')', '')
+ ' WITH(FILLFACTOR = 80 , DATA_COMPRESSION = PAGE) ' + CHAR(10)
+ CHAR(13) + 'PRINT ''Index '
+ CONVERT(VARCHAR(10), ROW_NUMBER() OVER ( ORDER BY avg_user_impact DESC ))
+ ' [IX_' + OBJECT_NAME(d.object_id, d.database_id) + '_'
+ REPLACE(REPLACE(REPLACE(ISNULL(d.equality_columns, ''), ', ', '_'),
'[', ''), ']', '')
+ CASE WHEN d.equality_columns IS NOT NULL
AND d.inequality_columns IS NOT NULL THEN '_'
ELSE ''
END + REPLACE(REPLACE(REPLACE(ISNULL(d.inequality_columns, ''), ', ',
'_'), '[', ''), ']', '') + '] '
+ ' created '' + CONVERT(VARCHAR(103),GETDATE())' + CHAR(10) + CHAR(13)
+ ' Go' + CHAR(10) + CHAR(13) AS Create_Statement
FROM sys.dm_db_missing_index_group_stats s ,
sys.dm_db_missing_index_groups g ,
sys.dm_db_missing_index_details d
INNER JOIN Sys.databases AS B
ON d.database_id = B.database_id
WHERE s.group_handle = g.index_group_handle
AND d.index_handle = g.index_handle
AND s.avg_user_impact >= 90
AND D.database_id > 4 AND B.NAME <> 'distribution'
ORDER BY name,avg_user_impact DESC
go
结论 (Conclusion )
Be aware that your production environment is a restricted area and never deploy anything without a clear and well documented assessment process, to ensure the best performance of your production database.
请注意,您的生产环境是受限制的区域,没有清晰且记录良好的评估流程,切勿部署任何东西,以确保生产数据库的最佳性能。
参考资料 (References )
- Warning the Maximum Key Length is 900 bytes 警告最大密钥长度为900字节
- Improving Uniqueidentifier Performance 改善Uniqueidentifier性能
- GUID vs INT Debate GUID与INT辩论
- How It Works: Gotcha: *VARCHAR(MAX) caused my queries to be slower 工作原理:陷阱:* VARCHAR(MAX)导致查询变慢
翻译自: https://www.sqlshack.com/microsoft-sql-server-database-deployment-process/
智能推荐
从零开始搭建Hadoop_创建一个hadoop项目-程序员宅基地
文章浏览阅读331次。第一部分:准备工作1 安装虚拟机2 安装centos73 安装JDK以上三步是准备工作,至此已经完成一台已安装JDK的主机第二部分:准备3台虚拟机以下所有工作最好都在root权限下操作1 克隆上面已经有一台虚拟机了,现在对master进行克隆,克隆出另外2台子机;1.1 进行克隆21.2 下一步1.3 下一步1.4 下一步1.5 根据子机需要,命名和安装路径1.6 ..._创建一个hadoop项目
心脏滴血漏洞HeartBleed CVE-2014-0160深入代码层面的分析_heartbleed代码分析-程序员宅基地
文章浏览阅读1.7k次。心脏滴血漏洞HeartBleed CVE-2014-0160 是由heartbeat功能引入的,本文从深入码层面的分析该漏洞产生的原因_heartbleed代码分析
java读取ofd文档内容_ofd电子文档内容分析工具(分析文档、签章和证书)-程序员宅基地
文章浏览阅读1.4k次。前言ofd是国家文档标准,其对标的文档格式是pdf。ofd文档是容器格式文件,ofd其实就是压缩包。将ofd文件后缀改为.zip,解压后可看到文件包含的内容。ofd文件分析工具下载:点我下载。ofd文件解压后,可以看到如下内容: 对于xml文件,可以用文本工具查看。但是对于印章文件(Seal.esl)、签名文件(SignedValue.dat)就无法查看其内容了。本人开发一款ofd内容查看器,..._signedvalue.dat
基于FPGA的数据采集系统(一)_基于fpga的信息采集-程序员宅基地
文章浏览阅读1.8w次,点赞29次,收藏313次。整体系统设计本设计主要是对ADC和DAC的使用,主要实现功能流程为:首先通过串口向FPGA发送控制信号,控制DAC芯片tlv5618进行DA装换,转换的数据存在ROM中,转换开始时读取ROM中数据进行读取转换。其次用按键控制adc128s052进行模数转换100次,模数转换数据存储到FIFO中,再从FIFO中读取数据通过串口输出显示在pc上。其整体系统框图如下:图1:FPGA数据采集系统框图从图中可以看出,该系统主要包括9个模块:串口接收模块、按键消抖模块、按键控制模块、ROM模块、D.._基于fpga的信息采集
微服务 spring cloud zuul com.netflix.zuul.exception.ZuulException GENERAL-程序员宅基地
文章浏览阅读2.5w次。1.背景错误信息:-- [http-nio-9904-exec-5] o.s.c.n.z.filters.post.SendErrorFilter : Error during filteringcom.netflix.zuul.exception.ZuulException: Forwarding error at org.springframework.cloud..._com.netflix.zuul.exception.zuulexception
邻接矩阵-建立图-程序员宅基地
文章浏览阅读358次。1.介绍图的相关概念 图是由顶点的有穷非空集和一个描述顶点之间关系-边(或者弧)的集合组成。通常,图中的数据元素被称为顶点,顶点间的关系用边表示,图通常用字母G表示,图的顶点通常用字母V表示,所以图可以定义为: G=(V,E)其中,V(G)是图中顶点的有穷非空集合,E(G)是V(G)中顶点的边的有穷集合1.1 无向图:图中任意两个顶点构成的边是没有方向的1.2 有向图:图中..._给定一个邻接矩阵未必能够造出一个图
随便推点
MDT2012部署系列之11 WDS安装与配置-程序员宅基地
文章浏览阅读321次。(十二)、WDS服务器安装通过前面的测试我们会发现,每次安装的时候需要加域光盘映像,这是一个比较麻烦的事情,试想一个上万个的公司,你天天带着一个光盘与光驱去给别人装系统,这将是一个多么痛苦的事情啊,有什么方法可以解决这个问题了?答案是肯定的,下面我们就来简单说一下。WDS服务器,它是Windows自带的一个免费的基于系统本身角色的一个功能,它主要提供一种简单、安全的通过网络快速、远程将Window..._doc server2012上通过wds+mdt无人值守部署win11系统.doc
python--xlrd/xlwt/xlutils_xlutils模块可以读xlsx吗-程序员宅基地
文章浏览阅读219次。python–xlrd/xlwt/xlutilsxlrd只能读取,不能改,支持 xlsx和xls 格式xlwt只能改,不能读xlwt只能保存为.xls格式xlutils能将xlrd.Book转为xlwt.Workbook,从而得以在现有xls的基础上修改数据,并创建一个新的xls,实现修改xlrd打开文件import xlrdexcel=xlrd.open_workbook('E:/test.xlsx') 返回值为xlrd.book.Book对象,不能修改获取sheett_xlutils模块可以读xlsx吗
关于新版本selenium定位元素报错:‘WebDriver‘ object has no attribute ‘find_element_by_id‘等问题_unresolved attribute reference 'find_element_by_id-程序员宅基地
文章浏览阅读8.2w次,点赞267次,收藏656次。运行Selenium出现'WebDriver' object has no attribute 'find_element_by_id'或AttributeError: 'WebDriver' object has no attribute 'find_element_by_xpath'等定位元素代码错误,是因为selenium更新到了新的版本,以前的一些语法经过改动。..............._unresolved attribute reference 'find_element_by_id' for class 'webdriver
DOM对象转换成jQuery对象转换与子页面获取父页面DOM对象-程序员宅基地
文章浏览阅读198次。一:模态窗口//父页面JSwindow.showModalDialog(ifrmehref, window, 'dialogWidth:550px;dialogHeight:150px;help:no;resizable:no;status:no');//子页面获取父页面DOM对象//window.showModalDialog的DOM对象var v=parentWin..._jquery获取父window下的dom对象
什么是算法?-程序员宅基地
文章浏览阅读1.7w次,点赞15次,收藏129次。算法(algorithm)是解决一系列问题的清晰指令,也就是,能对一定规范的输入,在有限的时间内获得所要求的输出。 简单来说,算法就是解决一个问题的具体方法和步骤。算法是程序的灵 魂。二、算法的特征1.可行性 算法中执行的任何计算步骤都可以分解为基本可执行的操作步,即每个计算步都可以在有限时间里完成(也称之为有效性) 算法的每一步都要有确切的意义,不能有二义性。例如“增加x的值”,并没有说增加多少,计算机就无法执行明确的运算。 _算法
【网络安全】网络安全的标准和规范_网络安全标准规范-程序员宅基地
文章浏览阅读1.5k次,点赞18次,收藏26次。网络安全的标准和规范是网络安全领域的重要组成部分。它们为网络安全提供了技术依据,规定了网络安全的技术要求和操作方式,帮助我们构建安全的网络环境。下面,我们将详细介绍一些主要的网络安全标准和规范,以及它们在实际操作中的应用。_网络安全标准规范