接口自动化测试(Python+Requests+Unittest)合集详解教程_带requests的python在线运行环境-程序员宅基地
技术标签: 技术分享 python 软件测试 lua 开发语言
(1)接口自动化测试的优缺点
优点:
- 测试复用性。
- 维护成本相对UI自动化低一些。
- 回归方便。
- 可以运行更多更繁琐的测试。
自动化的一个明显的好处是可以在较少的时间内运行更多的测试。为什么UI自动化维护成本更高? 因为前端页面变化太快,而且UI自动化比较耗时(比如等待页面元素的加载、添加等待时间、定位元素、操作元素、模拟页面动作这些都需要时间) 为什么接口自动化维护成本较低? 因为接口较稳定,接口的响应时间基本上都是秒级、毫秒级别的,速度快,并且接口自动化本身也可以做一些有关联的操作、全流程的操作(比如:注册 --> 登录 --> 修改个人信息)
-
优点1、优点3、优点4是接口自动化和UI自动化公有的优点。
缺点:
- 不能完全取代手工测试。(自动化永远不能替代手工测试,只是提高测试效率)
- 手工测试比自动化测试发现的缺陷更多,自动化测试不容易发现新的BUG。
GET请求和POST请求的区别:
- GET请求一般是从后台服务器上获取数据用于前端页面的展示(例如:看到列表页面等),POST请求是向服务器传送数据(登录、注册、上传文件、发布文章)。什么时候用GET,什么时候用POST取决于开发。无论用POST请求还是GET请求,都能完成对数据的增删改查,分不同的请求方式更多的是一种约定。
- GET请求的请求参数是拼接在url后面的,只能以文本的形式传递参数,请求参数会显示在地址栏,数据长度受限于url的长度,传递的数据量小(4KB左右,不同浏览器会有差异),POST请求的请求参数是放在request body里面,传递数据量大(默认8M),对数据长度也没有要求。GET请求可以在浏览器中直接访问,而POST请求只能借助工具完成(比如:postman、jmeter)。
- GET请求速度快,安全性不高;POST请求一般用于像登录这种安全性要求高的场合,请求不会被缓存,也不会保留在浏览器的历史记录中。
-
以前:get 查询;post 新增;put 编辑;delete 删除 -
现在:get 查询;post 新增 + 编辑 + 删除 -
或者:纯post走天下
前后端分离
开发模式
以前老的方式:
- 产品经理 / 领导 / 客户提出需求(提出文字需求)
- UI做出设计图
- 前端工程师做html页面(用户能看到的页面)
- 后端工程师将html页面套成jsp页面(前后端强依赖,后端必须要等到前端的html页面做好才能套jsp。如果html发生变更,就很麻烦,开发效率低)
- 集成出现问题
- 前端返工
- 后端返工
- 二次集成
- 集成成功
- 交付
新的方式:
- 产品经理 / 领导 / 客户提出需求(提出文字需求)
- UI做出设计图
- 前后端约定接口 & 数据 & 参数
- 前后端并行开发(无强依赖,可前后端并行开发,如果需求变更,只要接口 & 参数不变,就不用两边都修改代码,开发效率高)
- 前后端集成
- 前端页面调整
- 集成成功
- 交付
通过F12打开浏览器开发者工具进行抓包,返回数据是json格式的就是前后端分离,返回时html页面就是没有前后端分离。
微服务的概念:
将大模块切分成小模块。减少代码的耦合度,从而降低模块与模块之间的影响。原先是一个jar包里面包含所有模块,改一个模块就有可能影响其他模块,现在是将一个一个的模块都打成一个一个的jar包,模块与模块之间的交互通过接口,哪个模块出了问题,只需要修改那个模块的jar包,避免因为修改一个模块的代码导致其他模块出错。
(2)Python requests框架讲解
接口自动化requests环境搭建
接口自动化核心库:requests
安装requests库的方法:
方法一:
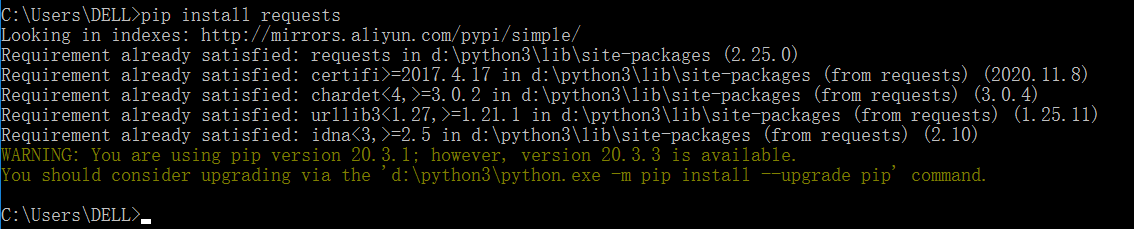
命令行安装,打开cmd或者终端,输入以下命令:
pip install requests -i https://pypi.douban.com/simple/
方法二:
在pycharm中安装,settings --> Project --> Project Interpreter --> 点击“+”号 --> 输入request安装
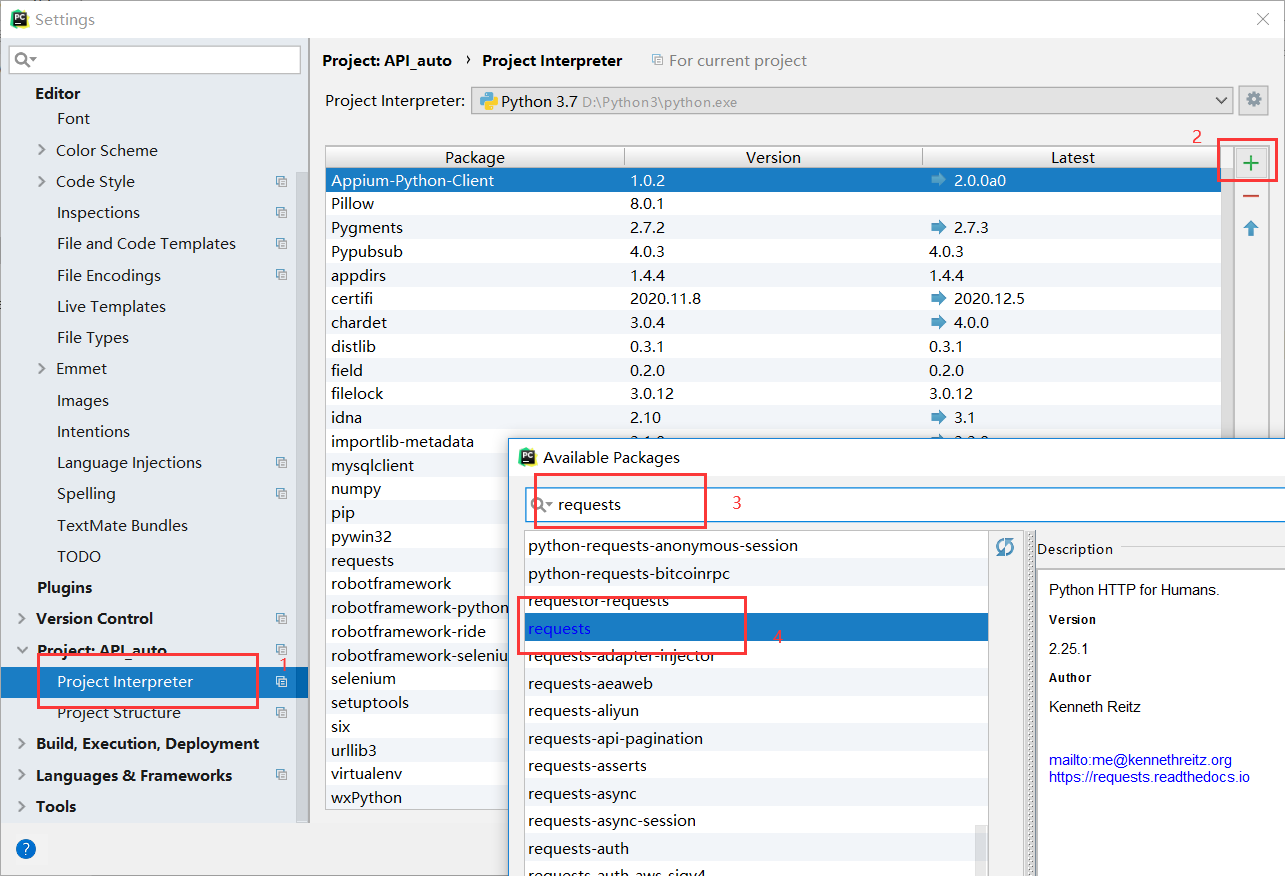
测试环境是否ok
-
import requests -
url_toutiao = "https://www.ixigua.com/tlb/comment/article/v5/tab_comments/?tab_index=0&count=10&group_id=6914830518563373581&item_id=6914830518563373581&aid=1768" -
# 方式一: -
# result_toutiao = requests.get(url_toutiao) -
# 方式二: -
result_toutiao = requests.get(url=url_toutiao) -
# 方式三: -
# result_toutiao = requests.get( -
# "https://www.ixigua.com/tlb/comment/article/v5/tab_comments/?tab_index=0&count=1&group_id=6914830518563373581&item_id=6914830518563373581&aid=1768") -
# print(result_toutiao.json()) -
# print(type(result_toutiao.json())) # <class 'dict'> -
result = result_toutiao.json() -
print(result) -
expect_result = "华晨金杯汽车花朵朵" -
actual_result = result["data"][0]["comment"]["user_name"] -
print(actual_result) -
if expect_result == actual_result: -
print("pass!") -
else: -
print("failed!")
JSON、URL、text、encoding、status_code、encoding、cookies
-
print(result.json()) # 响应结果以json的形式打印输出 -
print(result.url) # 打印url地址 -
print(result.text) # 以文本格式打印服务器响应的内容 -
print(result.status_code) # 响应状态码 -
print(result.encoding) # 编码格式 -
print(result.cookies) # cookie
JSON(JavaScript Object Notation, JS 对象简谱) 是一种轻量级的数据交换格式。它基于 ECMAScript (欧洲计算机协会制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
JSON格式在Python里面相当于字典类型。
JSON格式化:JSON在线视图查看器(Online JSON Viewer)
url在线编码转换:URL在线编码转换工具 - 编码转换工具 - W3Cschool
(3)get、post、put、delete请求方式的自动化实现
GET请求方式
-
import requests -
url_toutiao = "https://www.ixigua.com/tlb/comment/article/v5/tab_comments/?tab_index=0&count=10&group_id=6914830518563373581&item_id=6914830518563373581&aid=1768" -
# 方式一: -
# result_toutiao = requests.get(url_toutiao) -
# 方式二: -
result_toutiao = requests.get(url=url_toutiao) -
# 方式三: -
# result_toutiao = requests.get( -
# "https://www.ixigua.com/tlb/comment/article/v5/tab_comments/?tab_index=0&count=1&group_id=6914830518563373581&item_id=6914830518563373581&aid=1768") -
# print(result_toutiao.json()) -
# print(type(result_toutiao.json())) # <class 'dict'> -
result = result_toutiao.json() -
print(result) -
expect_result = "华晨金杯汽车花朵朵" -
actual_result = result["data"][0]["comment"]["user_name"] -
print(actual_result) -
if expect_result == actual_result: -
print("pass!") -
else: -
print("failed!") -
运行结果: -
{'message': 'success', 'err_no': 0, 'data': [{'comment': {'id': 6914864825282215951, 'id_str': '6914864825282215951', 'text': '藁城出国打工的人很多,重点检查藁城区!', 'content_rich_span': '{"links":[]}', 'user_id': 940799526971408, 'user_name': '华晨金杯汽车花朵朵',}, 'post_count': 0, 'stick_toast': 1, 'stable': True} -
华晨金杯汽车花朵朵 -
pass!
POST请求方式
-
import requests -
url_v_login = "http://[服务器ip]:8081/login" -
# 定义参数,字典格式 -
payload = {'username': 'sang', 'password': '123'} -
# Content-Type: application/json --> json -
# Content-Type: application/x-www-form-urlencoded --> data -
result = requests.post(url_v_login, data=payload) -
# 将返回结果转为json格式 -
result_json = result.json() -
print(result_json) # {'status': 'success', 'msg': '登录成功'} -
# 获取RequestsCookieJar -
result_cookie = result.cookies -
print(result_cookie, type(result_cookie)) # RequestsCookieJar -
# 将RequestsCookieJar转化为字典格式 -
result_cookie_dic = requests.utils.dict_from_cookiejar(result_cookie) -
print(result_cookie_dic) # {'JSESSIONID': 'D042C5FE4CFF337806D545B0001E7197'} -
# 获取SESSION -
final_cookie = "JSESSIONID=" + result_cookie_dic["JSESSIONID"] # SJSESSIONID=D042C5FE4CFF337806D545B0001E7197 -
print(final_cookie)
PUT请求方式
-
# V部落_编辑栏目 -
# 定义请求头,自动获取cookie的方法详情请看下文 -
headers = {"Cookie": "VBlog(self.requests).get_cookie()"} -
new_now_time = time.strftime("%Y%m%d%H%M%S", time.localtime(time.time())) -
new_category_name = "更新栏目" + new_now_time -
payload = {"id": 2010, "cateName": new_category_name} -
self.requests.put("http://[服务器ip]:8081/admin/category/", headers=headers, data=payload)
DELETE请求方式
-
# 删除栏目 -
result = self.requests.delete("http://[服务器ip]:8081/admin/category/" + “2010”, headers=headers) -
print(result.json()) # {'status': 'success', 'msg': '删除成功!'} -
self.assertEqual("删除成功!", result.json()["msg"])
(4)接口自动化测试过程中cookie的处理
手动传入cookie的值(每次通过浏览器F12抓包,然后复制request header里面的cookie)
-
import requests -
# V部落查询栏目 -
url_v_category = "http://[服务器ip]:8081/admin/category/all" -
# 定制请求头 -
# 如果你想为请求添加HTTP头部,只要简单地传递一个字典给headers参数就可以了 -
v_headers = { -
"cookie": "studentUserName=ctt01; Hm_lvt_cd8218cd51f800ed2b73e5751cb3f4f9=1609742724,1609762306,1609841170,1609860946; adminUserName=admin; JSESSIONID=9D1FF19F333C5E25DBA60769E9F5248E"} -
result = requests.get(url_v_category, headers=v_headers) -
# 打印json格式的响应结果 -
print(result.json())

cookie自动获取
-
import requests -
url_v_login = "http://[服务器ip]:8081/login" -
# 定义参数,字典格式 -
payload = {'username': 'sang', 'password': '123'} -
# Content-Type: application/json --> json -
# Content-Type: application/x-www-form-urlencoded --> data -
result = requests.post(url_v_login, data=payload) -
# 将返回结果转为json格式 -
result_json = result.json() -
print(result_json) # {'status': 'success', 'msg': '登录成功'} -
# 获取RequestsCookieJar -
result_cookie = result.cookies -
print(result_cookie, type(result_cookie)) # RequestsCookieJar -
# 将RequestsCookieJar转化为字典格式 -
result_cookie_dic = requests.utils.dict_from_cookiejar(result_cookie) -
print(result_cookie_dic) # {'JSESSIONID': 'D042C5FE4CFF337806D545B0001E7197'} -
# 获取SESSION -
final_cookie = "JSESSIONID=" + result_cookie_dic["JSESSIONID"] # SJSESSIONID=D042C5FE4CFF337806D545B0001E7197 -
print(final_cookie)
批量获取cookie脚本
-
import requests -
def get_cookie(username, password): -
"""通过考试系统学生登录获取单个cookie""" -
url_login = "http://[服务器ip]:8088/api/user/login" -
payload = {"userName": username, "password": password, "remember": False} -
result = requests.post(url_login, json=payload) -
# result_json = result.json() -
# print(result_json) -
# 获取RequestsCookieJar -
result_cookie = result.cookies -
# print(result_cookie, type(result_cookie)) # RequestsCookieJar -
# 将RequestsCookieJar转化为字典格式 -
result_cookie_dic = requests.utils.dict_from_cookiejar(result_cookie) -
# print(result_cookie_dic) # {'SESSION': 'YzFkM2IzN2QtZWY1OC00Nzc4LTgyOWYtNjg5OGRiZDZlM2E4'} -
# 获取SESSION -
final_cookie = "SESSION=" + result_cookie_dic["SESSION"] # SESSION=Mzc2... -
return final_cookie
-
from test01.demo04_student_login import get_cookie -
import os -
def get_batch_cookies(): -
"""批量获取cookie""" -
# 获取cookie之前,先将cookies.csv文件内容清空 -
# with open(r"D:\Desktop\Testman_Study\API_auto\file\cookies.csv", "w") as cookies_info: -
# cookies_info.write("") -
# 或者将文件删除 -
os.remove(r"D:\Desktop\Testman_Study\API_auto\file\cookies.csv") -
# 读取csv文件 -
with open(r"D:\Desktop\Testman_Study\API_auto\file\register.csv", "r") as user_info: -
for user in user_info: -
user_list = user.strip().split(",") -
# 调用获取单个cookies的方法,传入注册好的用户名和密码 -
cookies = get_cookie(user_list[0], user_list[1]) -
# 将cookie追加写入文件 -
with open(r"D:\Desktop\Testman_Study\API_auto\file\cookies.csv", "a") as cookies_info: -
cookies_info.write(cookies + "\n") -
# 调用方法 -
get_batch_cookies()
-
register.csv(前提是这些账号和密码都是已经注册过的,可以直接登录) -
poopoo001,123456,1 -
poopoo002,123457,2 -
poopoo003,123458,3 -
poopoo004,123459,4 -
......
-
cookies.csv -
SESSION=ZmE3YmU4ZDctNDExZS00MDdhLWE0YjEtMjAyZjQxOTMxYmUx -
SESSION=YjdkNTZhNTUtNGFmMi00MjVkLWEyNjctOTNiMmRmOTY1YTdm -
SESSION=ZTJmMTYzMWEtZjUzOS00NTlhLWI0OWQtMzBmN2RkYmU4YmRi -
SESSION=YTM0ZGRhOTctZjk5Ni00OWZhLTg1YTItZjUyMTMwZGE2MjVi -
......
(5)不同类型请求参数的处理
-
import requests -
# 文章列表 -
url_v_article = "http://[服务器ip]:8081/article/all" -
v_headers = { -
"Cookie": "studentUserName=ctt01; Hm_lvt_cd8218cd51f800ed2b73e5751cb3f4f9=1609742724,1609762306,1609841170,1609860946; adminUserName=admin; JSESSIONID=9D1FF19F333C5E25DBA60769E9F5248E"} -
# 自定义url参数,定义一个字典,将参数拆分,再将字典传递给params变量即可 -
article_params = {"state": 1, # -1:全部文章 1:已发表 0:回收站 2:草稿箱 -
"page": 1, # 显示第1页 -
"count": 6, # 每页显示6条 -
"keywords": "" # 包含的关键字 -
} -
keywords = ["大橘猫", "跑男", "牙"] -
for keyword in keywords: -
article_params["keywords"] = keyword -
# headers和params是不定长的,根据定义的字典传参 -
result = requests.get(url_v_article, headers=v_headers, params=article_params) -
print(result.json())

(6)结合Python+Requests+Unittest框架做接口自动化测试
unittest框架结构:
if _name_ == '__main__':
if __name__ == '__main__'的意思是:
- 当.py文件被直接运行时,if __name__ == '__main__'下的代码块将被运行;
- 当.py文件以模块形式被导入时,if __name__ == '__main__'下的代码块不被运行。
(7)接口自动化测试过程中高级断言
闭环断言(新增 --> 查询 --> 修改 --> 查询 --> 删除 -->查询)
-
def test_article(self): -
# ①V部落_新增文章 -
now_time = time.strftime("%Y%m%d%H%M%S", time.localtime(time.time())) -
title = "蔡坨坨" + now_time -
payload = {"id": -1, "title": title, "mdContent": "文章内容", "state": 1, "htmlContent": "<p>文章内容</p>", -
"dynamicTags": "", "cid": 62} -
headers = {"Cookie": VBlog(self.requests).get_cookie()} -
result = self.requests.post("http://[服务器ip]:8081/article/", headers=headers, data=payload) -
# ②查询文章 -
url_v_article = "http://[服务器ip]:8081/article/all" -
article_params = {"state": 1, # -1:全部文章 1:已发表 0:回收站 2:草稿箱 -
"page": 1, # 显示第1页 -
"count": 6, # 每页显示6条 -
"keywords": title # 包含的关键字title -
} -
result = requests.get(url_v_article, headers=headers, params=article_params, timeout=30) -
print(result.json()) # 响应结果以json的形式打印输出 -
ls = result.json()["articles"] -
act = 123 -
# 查到新增的文章,说明新增成功 -
for l in range(0, len(ls)): -
if ls[l]["title"] == title: -
act = "ok" -
article_id = ls[l]["id"] -
self.assertEqual("ok", act) -
# ③编辑文章 -
now_time = time.strftime("%Y%m%d%H%M%S", time.localtime(time.time())) -
title = "修改文章" + now_time -
payload = {"id": article_id, "title": title, "mdContent": "修改内容", "state": 1, "htmlContent": "<p>修改内容</p>", -
"dynamicTags": "", "cid": 62} -
headers = {"Cookie": VBlog(self.requests).get_cookie()} -
self.requests.post("http://[服务器ip]:8081/article/", headers=headers, data=payload) -
# 编辑完,查询文章 -
url_v_article = "http://[服务器ip]:8081/article/all" -
article_params = {"state": 1, # -1:全部文章 1:已发表 0:回收站 2:草稿箱 -
"page": 1, # 显示第1页 -
"count": 6, # 每页显示6条 -
"keywords": title # 包含的关键字title -
} -
result = requests.get(url_v_article, headers=headers, params=article_params, timeout=30) -
print(result.json()) # 响应结果以json的形式打印输出 -
ls = result.json()["articles"] -
act = 123 -
# 查到修改过的文章,说明编辑成功 -
for l in range(0, len(ls)): -
if ls[l]["title"] == title: -
act = "ok" -
article_id = ls[l]["id"] -
self.assertEqual("ok", act) -
# ④查看文章详情 -
article_id = str(article_id) -
result = self.requests.get("http://[服务器ip]:8081/article/" + article_id, headers=headers) -
print(result.json()) -
if result.json()["title"] == title: -
act = "ok" -
self.assertEqual(act, "ok") -
# ⑤删除文章 -
payload = {'aids': article_id, 'state': 1} -
result = self.requests.put("http://[服务器ip]:8081/article/dustbin", headers=headers, data=payload) -
print(result.json()) -
act = result.json()["msg"] -
self.assertEqual(act, "删除成功!")
(8)通过HTMLTestRunner.py生成可视化HTML测试报告
HTMLTestRunner.py百度网盘链接:
-
from reports import HTMLTestRunner -
from case.exam_case.teacher_case import TeacherCase -
import unittest -
import os -
import time -
# 创建测试套件 -
suite = unittest.TestSuite() -
# 添加测试用例,根据添加顺序执行 -
# 添加单个测试用例 -
# suite.addTest(TeacherCase("test_001_admin_login")) -
# 添加多个测试用例 -
suite.addTests([TeacherCase("test_001_admin_login"), -
TeacherCase("test_002_insert_paper"), -
TeacherCase("test_003_select_paper"), -
]) -
# 定义测试报告的存放的路径 -
path = r"D:\Desktop\Testman_Study\unittest_exam_system\reports" -
# 判断路径是否存在 -
if not os.path.exists(path): -
# 如果不存在,则创建一个 -
os.makedirs(path) -
else: -
pass -
# 定义一个时间戳用于测试报告命名 -
now_time = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime(time.time())) -
reports_path = path + "\\" + now_time + "(exam_report).html" -
reports_title = u"考试系统&V部落——测试报告" -
desc = u"考试系统&V部落——接口自动化测试报告" -
# 二进制写 -
fp = open(reports_path, "wb") -
runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title=reports_title, description=desc) -
# 运行 -
runner.run(suite)
postman、JMeter、requests总结:
- postman:接口功能测试
- JMeter:接口性能测试
- requests:接口自动化
- 三个的共同特点:都能完成接口功能测试。
总结:
感谢每一个认真阅读我文章的人!!!
作为一位过来人也是希望大家少走一些弯路,如果你不想再体验一次学习时找不到资料,没人解答问题,坚持几天便放弃的感受的话,在这里我给大家分享一些自动化测试的学习资源,希望能给你前进的路上带来帮助。

软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

视频文档获取方式:
这份文档和视频资料,对于想从事【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!以上均可以分享,点下方进群即可自行领取。
智能推荐
c# 调用c++ lib静态库_c#调用lib-程序员宅基地
文章浏览阅读2w次,点赞7次,收藏51次。四个步骤1.创建C++ Win32项目动态库dll 2.在Win32项目动态库中添加 外部依赖项 lib头文件和lib库3.导出C接口4.c#调用c++动态库开始你的表演...①创建一个空白的解决方案,在解决方案中添加 Visual C++ , Win32 项目空白解决方案的创建:添加Visual C++ , Win32 项目这......_c#调用lib
deepin/ubuntu安装苹方字体-程序员宅基地
文章浏览阅读4.6k次。苹方字体是苹果系统上的黑体,挺好看的。注重颜值的网站都会使用,例如知乎:font-family: -apple-system, BlinkMacSystemFont, Helvetica Neue, PingFang SC, Microsoft YaHei, Source Han Sans SC, Noto Sans CJK SC, W..._ubuntu pingfang
html表单常见操作汇总_html表单的处理程序有那些-程序员宅基地
文章浏览阅读159次。表单表单概述表单标签表单域按钮控件demo表单标签表单标签基本语法结构<form action="处理数据程序的url地址“ method=”get|post“ name="表单名称”></form><!--action,当提交表单时,向何处发送表单中的数据,地址可以是相对地址也可以是绝对地址--><!--method将表单中的数据传送给服务器处理,get方式直接显示在url地址中,数据可以被缓存,且长度有限制;而post方式数据隐藏传输,_html表单的处理程序有那些
PHP设置谷歌验证器(Google Authenticator)实现操作二步验证_php otp 验证器-程序员宅基地
文章浏览阅读1.2k次。使用说明:开启Google的登陆二步验证(即Google Authenticator服务)后用户登陆时需要输入额外由手机客户端生成的一次性密码。实现Google Authenticator功能需要服务器端和客户端的支持。服务器端负责密钥的生成、验证一次性密码是否正确。客户端记录密钥后生成一次性密码。下载谷歌验证类库文件放到项目合适位置(我这边放在项目Vender下面)https://github.com/PHPGangsta/GoogleAuthenticatorPHP代码示例://引入谷_php otp 验证器
【Python】matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距-程序员宅基地
文章浏览阅读4.3k次,点赞5次,收藏11次。matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距
docker — 容器存储_docker 保存容器-程序员宅基地
文章浏览阅读2.2k次。①Storage driver 处理各镜像层及容器层的处理细节,实现了多层数据的堆叠,为用户 提供了多层数据合并后的统一视图②所有 Storage driver 都使用可堆叠图像层和写时复制(CoW)策略③docker info 命令可查看当系统上的 storage driver主要用于测试目的,不建议用于生成环境。_docker 保存容器
随便推点
网络拓扑结构_网络拓扑csdn-程序员宅基地
文章浏览阅读834次,点赞27次,收藏13次。网络拓扑结构是指计算机网络中各组件(如计算机、服务器、打印机、路由器、交换机等设备)及其连接线路在物理布局或逻辑构型上的排列形式。这种布局不仅描述了设备间的实际物理连接方式,也决定了数据在网络中流动的路径和方式。不同的网络拓扑结构影响着网络的性能、可靠性、可扩展性及管理维护的难易程度。_网络拓扑csdn
JS重写Date函数,兼容IOS系统_date.prototype 将所有 ios-程序员宅基地
文章浏览阅读1.8k次,点赞5次,收藏8次。IOS系统Date的坑要创建一个指定时间的new Date对象时,通常的做法是:new Date("2020-09-21 11:11:00")这行代码在 PC 端和安卓端都是正常的,而在 iOS 端则会提示 Invalid Date 无效日期。在IOS年月日中间的横岗许换成斜杠,也就是new Date("2020/09/21 11:11:00")通常为了兼容IOS的这个坑,需要做一些额外的特殊处理,笔者在开发的时候经常会忘了兼容IOS系统。所以就想试着重写Date函数,一劳永逸,避免每次ne_date.prototype 将所有 ios
如何将EXCEL表导入plsql数据库中-程序员宅基地
文章浏览阅读5.3k次。方法一:用PLSQL Developer工具。 1 在PLSQL Developer的sql window里输入select * from test for update; 2 按F8执行 3 打开锁, 再按一下加号. 鼠标点到第一列的列头,使全列成选中状态,然后粘贴,最后commit提交即可。(前提..._excel导入pl/sql
Git常用命令速查手册-程序员宅基地
文章浏览阅读83次。Git常用命令速查手册1、初始化仓库git init2、将文件添加到仓库git add 文件名 # 将工作区的某个文件添加到暂存区 git add -u # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,不处理untracked的文件git add -A # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,包括untracked的文件...
分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120-程序员宅基地
文章浏览阅读202次。分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120
【C++缺省函数】 空类默认产生的6个类成员函数_空类默认产生哪些类成员函数-程序员宅基地
文章浏览阅读1.8k次。版权声明:转载请注明出处 http://blog.csdn.net/irean_lau。目录(?)[+]1、缺省构造函数。2、缺省拷贝构造函数。3、 缺省析构函数。4、缺省赋值运算符。5、缺省取址运算符。6、 缺省取址运算符 const。[cpp] view plain copy_空类默认产生哪些类成员函数