120年奥运会数据分析和可视化_athlete_data.csv可以分析那这数据之间的关系-程序员宅基地
技术标签: python 笔记 可视化 数据分析 我的作业 数据可视化
整理作业用的
# coding=utf-8
#第一步,导出相关函数库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import math
import scipy.stats as st
import statsmodels.api as sm
import seaborn as sns
from pylab import mpl
from matplotlib.font_manager import FontProperties
#中文显示
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定SimHei字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
第一步:导入函数库+中文显示
#第二步,加载数据
def loaddata():
datapath=r'C:\Users\安航正\Desktop\athlete_events.csv'
#路径datapath,编码方式gbk(用utf-8可能出现中文编码问题),允许空格
athletedata=pd.read_csv(datapath,encoding='gbk', skipinitialspace=True)
sex = {
'F':'女性','M':'男性'}
athletedata['Sex'] = athletedata.Sex.map(sex)
#因为原数据中的性别用“F”和“M”表示,不好看,用sex表示对应关系,将athletedata中的Sex中的W和M替换为中文,替换关系为sex,为方便理解特此用sex和Sex区别
return athletedata
第二步骤:将csv文件导入到python中并用athletedata表示(并将性别替换为中文)
def datadescirbe():
#读取数据(可以取一样的名字athletedata)
athletedata=loaddata()
#打印数据的列的名字
print(athletedata.columns)
#打印各列数据个数/是否有空缺值/字段类型
print(athletedata.info())
#打印前五行数据
print(athletedata.head())
#数据描述各个变量
#这一列中一共有多少个数据,这些数据中出现了多少类,出现最多的类别是什么,出现了多少次
print(athletedata['Sex'].describe())
print(athletedata['Age'].describe())
print(athletedata['Height'].describe())
print(athletedata['Weight'].describe())
print(athletedata['Team'].describe())
print(athletedata['Sport'].describe())
#分析具体某一项数据
#譬如身高
height=athletedata['Height']
median=height.median()
print("中位数为%f"%median)
mean=height.mean()
print("均值为%f"%mean)
#标准差
std=height.std()
print("标准差为%f"%std)
#偏度
skew=height.skew()
print("偏差为%f"%skew)
#峰度
kurt=height.kurt()
print("峰度为%f"%kurt)
#其实可以一段代码如下显示出来
agglomeration=height.agg(['mean','median','sum','std','skew','kurt'])
print(agglomeration)
第三步:简单的预览一下数据,进行数据分析
Index([‘ID’, ‘Name’, ‘Sex’, ‘Age’, ‘Height’, ‘Weight’, ‘Team’, ‘NOC’, ‘Games’,
‘Year’, ‘Season’, ‘City’, ‘Sport’, ‘Event’, ‘Medal’],
dtype=‘object’)
打印列的名字columns输出结果
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 271116 entries, 0 to 271115
Data columns (total 15 columns):
ID 271116 non-null int64
Name 271116 non-null object
Sex 271116 non-null object
Age 261642 non-null float64
Height 210945 non-null float64
Weight 208241 non-null float64
Team 271116 non-null object
NOC 271116 non-null object
Games 271116 non-null object
Year 271116 non-null int64
Season 271116 non-null object
City 271116 non-null object
Sport 271116 non-null object
Event 271116 non-null object
Medal 39783 non-null object
dtypes: float64(3), int64(2), object(10)
memory usage: 31.0+ MB
None
athletedata.info()打印各列数据个数/是否有空缺值/字段类型
ID Name Sex Age Height Weight Team
0 1 A Dijiang 男性 24.0 180.0 80.0 China
1 2 A Lamusi 男性 23.0 170.0 60.0 China
2 3 Gunnar Nielsen Aaby 男性 24.0 NaN NaN Denmark
3 4 Edgar Lindenau Aabye 男性 34.0 NaN NaN Denmark/Sweden
4 5 Christine Jacoba Aaftink 女性 21.0 185.0 82.0 Netherlands
NOC Games Year Season City Sport
0 CHN 1992 Summer 1992 Summer Barcelona Basketball
1 CHN 2012 Summer 2012 Summer London Judo
2 DEN 1920 Summer 1920 Summer Antwerpen Football
3 DEN 1900 Summer 1900 Summer Paris Tug-Of-War
4 NED 1988 Winter 1988 Winter Calgary Speed Skating
Event Medal
0 Basketball Men’s Basketball NaN
1 Judo Men’s Extra-Lightweight NaN
2 Football Men’s Football NaN
3 Tug-Of-War Men’s Tug-Of-War Gold
4 Speed Skating Women’s 500 metres NaN
athletedata.head()打印前五行数据
count 271116
unique 2
top 男性
freq 196594
Name: Sex, dtype: object
count 261642.000000
mean 25.556898
std 6.393561
min 10.000000
25% 21.000000
50% 24.000000
75% 28.000000
max 97.000000
Name: Age, dtype: float64
count 210945.000000
mean 175.338970
std 10.518462
min 127.000000
25% 168.000000
50% 175.000000
75% 183.000000
max 226.000000
Name: Height, dtype: float64
count 208241.000000
mean 70.702393
std 14.348020
min 25.000000
25% 60.000000
50% 70.000000
75% 79.000000
max 214.000000
Name: Weight, dtype: float64
count 271116
unique 1184
top United States
freq 17847
Name: Team, dtype: object
count 271116
unique 66
top Athletics
freq 38624
Name: Sport, dtype: object
.describe()函数对object类型和float类型的数据的描述
中位数为175.000000
均值为175.338970
标准差为10.518462
偏差为0.018477
峰度为0.177728
/#或者是
mean 1.753390e+02
median 1.750000e+02
sum 3.698688e+07
std 1.051846e+01
skew 1.847730e-02
kurt 1.777280e-01
Name: Height, dtype: float64
中位数均值标准差偏差峰度的输出
def dataplot():
plot=loaddata()
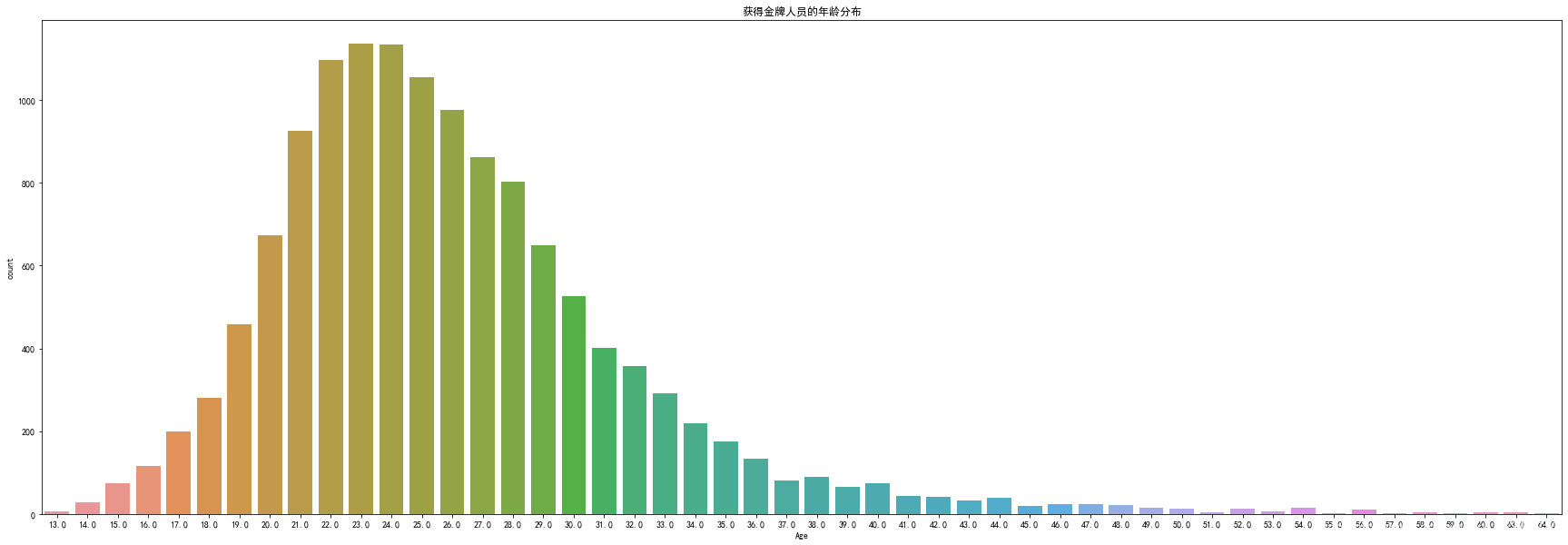
#获得金牌的人员中年龄的分布//条形图
#将获得金牌筛选出来
goldMedals=plot[(plot.Medal=='Gold')]
#print(goldMedals.head()) //调试用
#定义画布和布局
##将年龄中空缺值去掉
ageGoldMedals=goldMedals[(goldMedals['Age']).notnull()]
plt.figure(figsize=(30,10)) #画布大小
plt.tight_layout() #紧凑型布局
sns.countplot(ageGoldMedals['Age']) #绘制分布图
plt.title('获得金牌人员的年龄分布') #显示出来
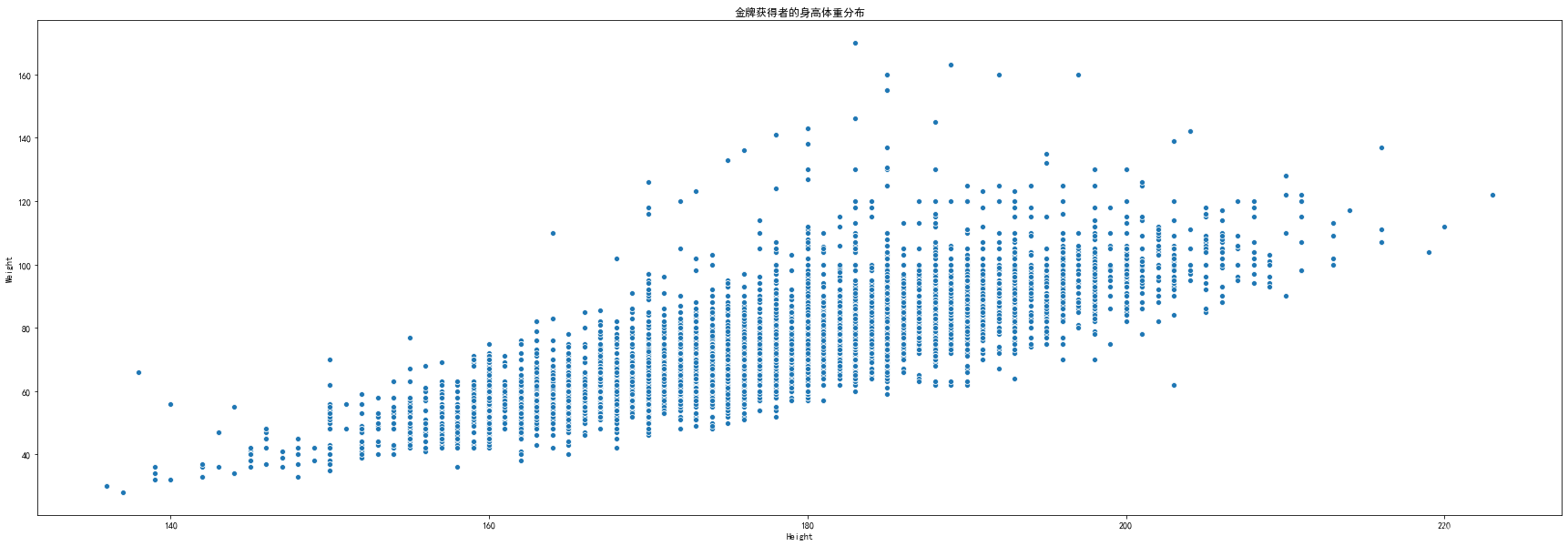
#获得金牌的身高和体重的分布//散点图
#将身高和体重的空缺值去掉
HWGoldMedals=goldMedals[(goldMedals['Height']).notnull()&(goldMedals['Weight'].notnull())]
#print(HWGoldMedals.head())//调试用
#绘制散点图
plt.figure(figsize=(30,10)) #画布大小
sns.scatterplot(x="Height",y="Weight",data=HWGoldMedals)
plt.title('金牌获得者的身高体重分布')
plt.show()
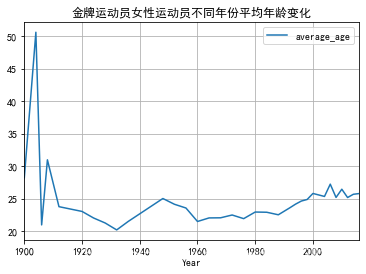
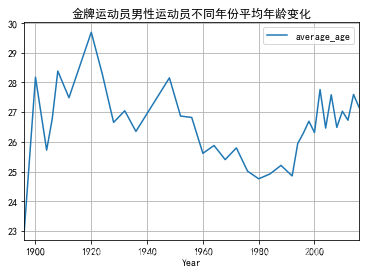
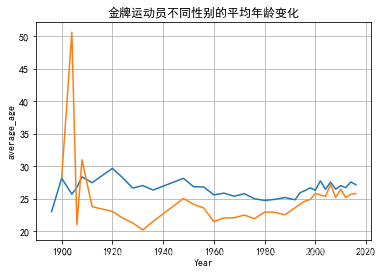
#金牌运动员不同性别的平均年龄变化//折线图
##筛选出得过金牌的对应性别,并且求出每一年的对应性别的年龄平均值,平均值分配在average_age列中去
Wgold = goldMedals[(goldMedals['Sex'] == '女性')]
NWgold=Wgold.groupby(by = ['Year']).Age.agg('mean').reset_index(name = "average_age")
Mgold = goldMedals[(goldMedals['Sex'] == '男性')]
NMgold=Mgold.groupby(by = ['Year']).Age.agg('mean').reset_index(name = "average_age")
#print(NWgold)//调试
#print(NMgold)
#两部分数据生成两个表//有格子好看一点QWQ
NWgold.plot(x='Year',y='average_age')
plt.grid(True)
NMgold.plot(x='Year',y='average_age')
plt.grid(True)
plt.title('金牌运动员不同性别的平均年龄变化')
plt.show()
#两部分数据生成一个表进行对比
sns.lineplot(x = 'Year', y = 'average_age', data = NMgold)
sns.lineplot(x = 'Year', y = 'average_age', data = NWgold)
plt.title('金牌运动员不同性别的平均年龄变化')
plt.show()
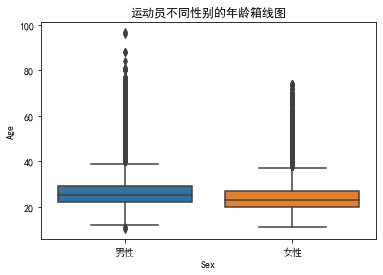
#参与者不同性别的年龄箱线图&提琴图
#将年份和性别中的空缺值去除
year_sex=plot[(plot['Sex']).notnull()&(plot['Year'].notnull())]
#箱线图
sns.boxplot(x = 'Sex', y = 'Age', data = year_sex)
plt.title('运动员不同性别的年龄箱线图')
plt.show()
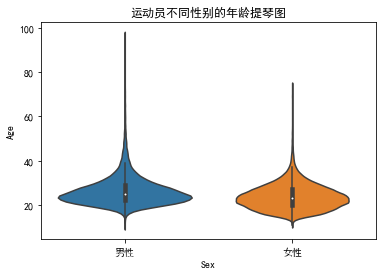
#提琴图
sns.violinplot(x = 'Sex', y = 'Age', data = year_sex)
plt.title('运动员不同性别的年龄提琴图')
plt.show()
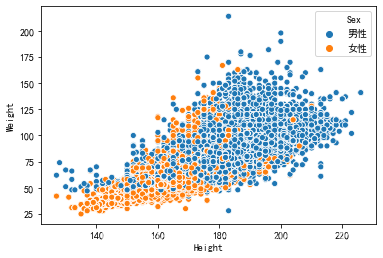
#男女运动员的身高和体重分布//散点图
#将性别和身高和体重的空缺值去除
sex_hw=plot[(plot['Sex']).notnull()&(plot['Height']).notnull()&(plot['Weight']).notnull()]
#print(sex_hw)//调试
#x轴对应身高,y轴对应体重,不同性别用点的颜色来区分
sns.scatterplot(x='Height', y='Weight', data=sex_hw, hue='Sex')
plt.show()
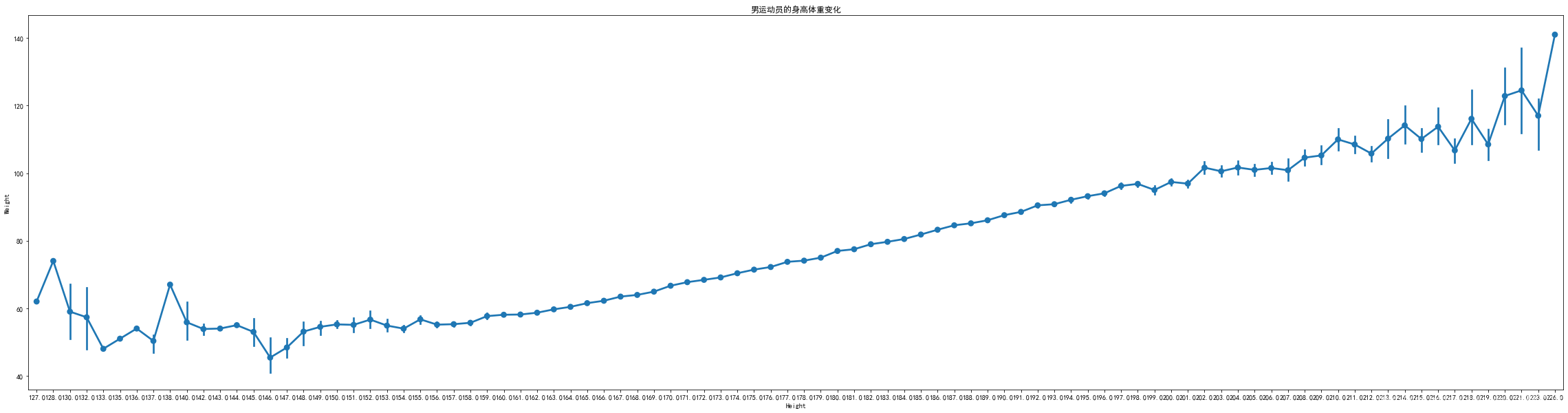
#绘制男运动员的身高体重分布//点状图
#用上一个图表中已经去除空缺值的数据选择男性单一性别
M_hw=sex_hw[(sex_hw['Sex']=='男性')]
plt.figure(figsize=(40,10))
#x轴身高,y轴体重
sns.pointplot('Height','Weight',data=M_hw)
plt.title('男运动员的身高体重变化')
plt.show()
第三步:数据可视化
以下是生成的数据可视化
if __name__ == '__main__':
datadescirbe()
dataplot()
第四步:写个main函数,将数据分析函数和数据可视化函数引入
此外
还写了个身高的qq图,但是感觉不太得劲的样子,而且没什么实际作用
智能推荐
oracle 12c 集群安装后的检查_12c查看crs状态-程序员宅基地
文章浏览阅读1.6k次。安装配置gi、安装数据库软件、dbca建库见下:http://blog.csdn.net/kadwf123/article/details/784299611、检查集群节点及状态:[root@rac2 ~]# olsnodes -srac1 Activerac2 Activerac3 Activerac4 Active[root@rac2 ~]_12c查看crs状态
解决jupyter notebook无法找到虚拟环境的问题_jupyter没有pytorch环境-程序员宅基地
文章浏览阅读1.3w次,点赞45次,收藏99次。我个人用的是anaconda3的一个python集成环境,自带jupyter notebook,但在我打开jupyter notebook界面后,却找不到对应的虚拟环境,原来是jupyter notebook只是通用于下载anaconda时自带的环境,其他环境要想使用必须手动下载一些库:1.首先进入到自己创建的虚拟环境(pytorch是虚拟环境的名字)activate pytorch2.在该环境下下载这个库conda install ipykernelconda install nb__jupyter没有pytorch环境
国内安装scoop的保姆教程_scoop-cn-程序员宅基地
文章浏览阅读5.2k次,点赞19次,收藏28次。选择scoop纯属意外,也是无奈,因为电脑用户被锁了管理员权限,所有exe安装程序都无法安装,只可以用绿色软件,最后被我发现scoop,省去了到处下载XXX绿色版的烦恼,当然scoop里需要管理员权限的软件也跟我无缘了(譬如everything)。推荐添加dorado这个bucket镜像,里面很多中文软件,但是部分国外的软件下载地址在github,可能无法下载。以上两个是官方bucket的国内镜像,所有软件建议优先从这里下载。上面可以看到很多bucket以及软件数。如果官网登陆不了可以试一下以下方式。_scoop-cn
Element ui colorpicker在Vue中的使用_vue el-color-picker-程序员宅基地
文章浏览阅读4.5k次,点赞2次,收藏3次。首先要有一个color-picker组件 <el-color-picker v-model="headcolor"></el-color-picker>在data里面data() { return {headcolor: ’ #278add ’ //这里可以选择一个默认的颜色} }然后在你想要改变颜色的地方用v-bind绑定就好了,例如:这里的:sty..._vue el-color-picker
迅为iTOP-4412精英版之烧写内核移植后的镜像_exynos 4412 刷机-程序员宅基地
文章浏览阅读640次。基于芯片日益增长的问题,所以内核开发者们引入了新的方法,就是在内核中只保留函数,而数据则不包含,由用户(应用程序员)自己把数据按照规定的格式编写,并放在约定的地方,为了不占用过多的内存,还要求数据以根精简的方式编写。boot启动时,传参给内核,告诉内核设备树文件和kernel的位置,内核启动时根据地址去找到设备树文件,再利用专用的编译器去反编译dtb文件,将dtb还原成数据结构,以供驱动的函数去调用。firmware是三星的一个固件的设备信息,因为找不到固件,所以内核启动不成功。_exynos 4412 刷机
Linux系统配置jdk_linux配置jdk-程序员宅基地
文章浏览阅读2w次,点赞24次,收藏42次。Linux系统配置jdkLinux学习教程,Linux入门教程(超详细)_linux配置jdk
随便推点
matlab(4):特殊符号的输入_matlab微米怎么输入-程序员宅基地
文章浏览阅读3.3k次,点赞5次,收藏19次。xlabel('\delta');ylabel('AUC');具体符号的对照表参照下图:_matlab微米怎么输入
C语言程序设计-文件(打开与关闭、顺序、二进制读写)-程序员宅基地
文章浏览阅读119次。顺序读写指的是按照文件中数据的顺序进行读取或写入。对于文本文件,可以使用fgets、fputs、fscanf、fprintf等函数进行顺序读写。在C语言中,对文件的操作通常涉及文件的打开、读写以及关闭。文件的打开使用fopen函数,而关闭则使用fclose函数。在C语言中,可以使用fread和fwrite函数进行二进制读写。 Biaoge 于2024-03-09 23:51发布 阅读量:7 ️文章类型:【 C语言程序设计 】在C语言中,用于打开文件的函数是____,用于关闭文件的函数是____。
Touchdesigner自学笔记之三_touchdesigner怎么让一个模型跟着鼠标移动-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏13次。跟随鼠标移动的粒子以grid(SOP)为partical(SOP)的资源模板,调整后连接【Geo组合+point spirit(MAT)】,在连接【feedback组合】适当调整。影响粒子动态的节点【metaball(SOP)+force(SOP)】添加mouse in(CHOP)鼠标位置到metaball的坐标,实现鼠标影响。..._touchdesigner怎么让一个模型跟着鼠标移动
【附源码】基于java的校园停车场管理系统的设计与实现61m0e9计算机毕设SSM_基于java技术的停车场管理系统实现与设计-程序员宅基地
文章浏览阅读178次。项目运行环境配置:Jdk1.8 + Tomcat7.0 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:Springboot + mybatis + Maven +mysql5.7或8.0+html+css+js等等组成,B/S模式 + Maven管理等等。环境需要1.运行环境:最好是java jdk 1.8,我们在这个平台上运行的。其他版本理论上也可以。_基于java技术的停车场管理系统实现与设计
Android系统播放器MediaPlayer源码分析_android多媒体播放源码分析 时序图-程序员宅基地
文章浏览阅读3.5k次。前言对于MediaPlayer播放器的源码分析内容相对来说比较多,会从Java-&amp;gt;Jni-&amp;gt;C/C++慢慢分析,后面会慢慢更新。另外,博客只作为自己学习记录的一种方式,对于其他的不过多的评论。MediaPlayerDemopublic class MainActivity extends AppCompatActivity implements SurfaceHolder.Cal..._android多媒体播放源码分析 时序图
java 数据结构与算法 ——快速排序法-程序员宅基地
文章浏览阅读2.4k次,点赞41次,收藏13次。java 数据结构与算法 ——快速排序法_快速排序法