Spark SQL中StructField和StructType-程序员宅基地
每一天都会进行更新,一起冲击未来
StructField和StructType
StructType---定义数据框的结构
StructType定义DataFrame的结构,是StructField对象的集合或者列表,通过printSchema可以打印出所谓的表字段名,StructType就是所有字段的集合。在创建dataframe的时候,将StructType作为字段的集合,按照顺序一一给各个字段。
StructField--定义DataFrame列的元数据
StructField来定义列名,列类型,可为空的列和元数据。
将StructField和StructType和DataFrame一起使用
首先创建样例类
case class StructType(fields: Array[StructField])
case class StructField(
name: String,
dataType: DataType,
nullable: Boolean = true,
metadata: Metadata = Metadata.empty)创建相关的数据以及字段名
//创建数据集合
val simpleData = Seq(
Row("James ","","Smith","36636","M",3000),
Row("Michael ","Rose","","40288","M",4000),
Row("Robert ","","Williams","42114","M",4000),
Row("Maria ","Anne","Jones","39192","F",4000),
Row("Jen","Mary","Brown","","F",-1) )
//创建StructType对象,里面是Array[StructField]类型
val simpleSchema = StructType(Array(
StructField("firstname",StringType,true),
StructField("middlename",StringType,true),
StructField("lastname",StringType,true),
StructField("id", StringType, true),
StructField("gender", StringType, true),
StructField("salary", IntegerType, true) ))
//创建dataFrame
val df = spark.createDataFrame(
spark.sparkContext.parallelize(simpleData),simpleSchema)
//打印Schema
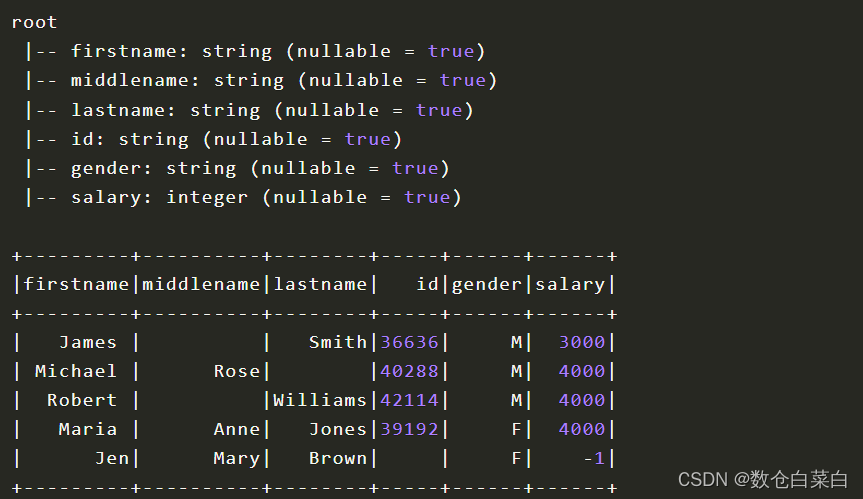
df.printSchema()
代码很简答,需要一个数据集合,创建一个StructType对象,里面包含StructField对象。
前面说过,StructField对象里面包含的是列名以及各种信息。
创建DataFrame。此时,元数据就是simpleData,所谓的Schema就是simpleSchema。
看一下各个字段以及“表结构”
其实上面的案例也比较有一些麻烦,下面来看一下另外一种方法,不用创建样例类
通过StructType.add进行操作
通过StructType.add进行操作,意味着我们不用再去创建StructField对象,通过add方法,只需要写入字段名称和字段方法就可以完成这个操作。
//创建上下文环境 SparkSql环境
val sparkSQL = new SparkConf().setMaster("local[*]").setAppName("SparkSQL")
val sparkSession = SparkSession.builder().config(sparkSQL).getOrCreate()
import sparkSession.implicits._
//数据集合
val simpData = Seq(Row("James", "", "Smith", "36636", "M", 3000),
Row("Michael", "Rose", "", "40288", "M", 4000),
Row("Robert", "", "Williams", "42114", "M", 4000),
Row("Maria", "Anne", "Jones", "39121", "F", 4000),
Row("Jen", "Mary", "Brown", "", "F", -1))
//创建StructType对象,将字段进行累加
val structType = new StructType()
.add("firstname", StringType)
.add("middlename", StringType)
.add("lastname", StringType)
.add("id", StringType)
.add("gender", StringType)
.add("salary", StringType)
//创建DataFrame
val dataFrame = sparkSession.createDataFrame(
sparkSession.sparkContext.parallelize(simpData), structType)
dataFrame.printSchema()
sparkSession.close()同样也是需要数据集合以及StructType对象。不过这种操作更加的简便,重要的是不会报错,用最上面的方法创建样例类可能会报错,需要导入不同的包。
使用StructType进行嵌套字段
//创建Spark SQL环境
val sparkSQL = new SparkConf().setMaster("local[*]").setAppName("SparkSQL")
val sparkSession = SparkSession.builder().config(sparkSQL).getOrCreate()
import sparkSession.implicits._
//创建数据集,其中最里面的Row对象就是嵌套对象
val structData = Seq( Row(Row("James ", "", "Smith"), "36636", "M", 3100),
Row(Row("Michael ", "Rose", ""), "40288", "M", 4300),
Row(Row("Robert ", "", "Williams"), "42114", "M", 1400),
Row(Row("Maria ", "Anne", "Jones"), "39192", "F", 5500),
Row(Row("Jen", "Mary", "Brown"), "", "F", -1))
//通过StructType的add方法进行添加字段
val structType = new StructType()
.add("name",new StructType()
.add("firstname",StringType)
.add("middlename",StringType)
.add("lastname",StringType))
.add("id",StringType)
.add("gender",StringType)
.add("salary",StringType)
//创建dataframe
val dataFrame =
sparkSession.createDataFrame(
sparkSession.sparkContext.parallelize(structData), structType)
//打印schema
dataFrame.printSchema()
sparkSession.close()因为name字段进行了嵌套,因此在"name"字段后面的类型里面不再是StringType.而是一个嵌套类型 StructType,这个嵌套类型里面再继续进行add。在这里面嵌套了三个字段。

可以看上面Schema。那么字段的类型是Struct结构。这个Struct结构里面嵌套了三个字段。
其实上面写错了,纠正一下,最后一个字段应该是IntegerType类型
如果写StringType类型,虽然打印Schema没有报错,但是进行select的时候就会报错。所以需要进行修改,在这里说明一下。
dataFrame.select("name").show(false)
看一下嵌套字段的name

本来以为Spark SQL的知识只有一点点,没有想到的是Spark SQL里面的知识很多很多,不单单是SQL语言,虽然可以结合Hive或者Mysql写SQL,但是结构化数据使用本身的DSL+SQL更加的简单。
SQL是重中之重,SQL能解决90%问题,剩下解决不了的问题就交给RDD把
智能推荐
SPFA算法详解——判断负权环_spfa算法判断负环-程序员宅基地
文章浏览阅读1w次,点赞5次,收藏34次。SPFA(Shortest Path Faster Algorithm)(队列优化)算法是求单源最短路径的一种算法。它是在Bellman-ford算法的基础上加上一个队列优化,减少了冗余的松弛操作,是一种高效的最短路算法。 Bellman-Ford算法虽然可以处理负环,但是时间复杂度为O(ne),e为图的边数,在图为稠密图的时候,是不可接受的。 Bellman-Ford算法的缺点在于,当某一个..._spfa算法判断负环
步进电机定位不准的原因分析_龙印旗帜机步进走不准-程序员宅基地
文章浏览阅读1.3k次。摘要: 步进电机定位不准的原因分析: 1)一般的步进驱动器对方向和脉冲信号都有一定的要求,如:方向信号在第一个脉冲上升沿或下降沿(不同的驱动器要求不一样)到来前数微秒被确定,否则会有一个脉冲所运转的角度与实际需要的转向相反,最 ... 步进电机定位不准的原因分析: 1)一般的步进驱动器对方向和脉冲信号都有一定的要求,如:方向信号在第一个脉冲上升沿或下降_龙印旗帜机步进走不准
用Python绘制渐变三角螺旋线_turtle画渐变线条-程序员宅基地
文章浏览阅读2.5k次,点赞7次,收藏11次。本文章主要教大家如何制作渐变颜色的三角形螺旋线,下面是代码块的解析,仅供学习python的小伙伴们参考。_turtle画渐变线条
(转)SRC)基于稀疏表示的人脸识别_双字典稀疏表示分类(dd-src)在人脸识别中的用法-程序员宅基地
文章浏览阅读322次。原 (SRC)基于稀疏表示的人脸识别 2013年11月01日 16:19:22 xiaoshengforever 阅读数:30632更多 <div class="tags-box space"> <..._双字典稀疏表示分类(dd-src)在人脸识别中的用法
十五、帧内编码:1、帧内编码的基本原理-程序员宅基地
文章浏览阅读4k次,点赞3次,收藏10次。帧内编码相对其他模块来说相对简单一、帧内编码的重要意义帧内编码时I帧主要的压缩编码方法,帧内编码的性能对视频整体编码结果具有重要影响I帧在编码时只采用当前帧的图像内部数据,体积通常比B/P帧更大,对整体码率的影响很大I帧在帧间编码中通常作为B/P帧的参考数据,如果I帧编码出现错误,将影响B/P帧的编码结果二、早起视频压缩标准的帧内编码1、简介在早期的视频编码标准MPEG-1/MPEG-2中,帧内编码已经发挥重要作用,只不过是比H264简单的多。MPEG-1/MPEG-2中已经定义了_帧内编码
微信小程序开发问题汇总-程序员宅基地
文章浏览阅读294次。前言经过将近一个多月的开发,我们团队开发的微信小程序 "出发吧一起" 终于开发完成,现在的线上版本为 2.2.4-beta 版本文档主要介绍该小程序在开发中所用到的技术,已经在开发中遇到问题的采取的解决方法原文链接(转载请注明出处):微信小程序:出发吧一起开源地址小程序简介“让兴趣不再孤单,让爱好不再流浪” 是微信小程序《出发吧一起》的主题,这款小程序旨在解决当代大..._微信小程序 if(m < 10){ m = '0' + m; }; if(d < 10) { d = '0' + d; };
随便推点
3、mqtt客户端演示(MQTT通信协议(mosquitto)发布订阅 C语言实现)_c语言mqtt订阅消息-程序员宅基地
文章浏览阅读1.1k次,点赞3次,收藏9次。MQTT通信协议(mosquitto)发布订阅 C语言实现_c语言mqtt订阅消息
需求分析-程序员宅基地
文章浏览阅读7.3w次,点赞29次,收藏136次。(一) 需求分析的目标和任务他的基本任务是:准确地回答“系统必须做什么”这个问题,也就是对目标系统提出完整、准确、清晰、具体的要求1、确定对系统的综合要求:功能需求、性能需求、可靠性和可用性需求、出错处理需求、接口需求、约束(设计约束或实现约束描述在设计或实现应用系统时应遵守的限制约束条件)、逆向需求(说明软件系统不应该做什么)、将来可能提出的需求2、分析系统的数据需求3、导出系统..._需求分析
数字物流系统的构建-程序员宅基地
文章浏览阅读1k次。(中国智慧城市网讯)数字物流系统源于实体物流,物理世界的实体物流是构建数字物流系统的基础。数字物流系统应该是物理世界的实际物流系统和相应的虚拟物流系统两个层面血肉相连、相互作用、有机统一的..._数字物流系统
File详解_file表示硬盘上的-程序员宅基地
文章浏览阅读731次。/* java.io.File; 1.File类和流无关,不能通过该类完成文件的读和写 2.File是文件和目录路径名的抽象表示形式 File代表的是硬盘上的Directory和file*/import java.io.*;import java.util.*;import java.text.*;public class fuck13{ public static void main(..._file表示硬盘上的
fast-rcnn,faster-rcnn相关细节_faster rcnn resize-程序员宅基地
文章浏览阅读1k次。详见大神博客http://closure11.com/rcnn-fast-rcnn-faster-rcnn%E7%9A%84%E4%B8%80%E4%BA%9B%E4%BA%8B/Bounding-box Regression有了ROI Pooling层其实就可以完成最简单粗暴的深度对象检测了,也就是先用selective search等proposal提取算法得到一批box坐标,_faster rcnn resize
对 COM 组件的调用返回了错误 HRESULT E_FAIL。-程序员宅基地
文章浏览阅读8.4k次。win7系统,用c#调用Interop.SHDocVw.dll时,报了个对“ COM 组件的调用返回了错误 HRESULT E_FAIL”的错误。网上有人说要开启dtc服务,然后去组件服务里_对 com 组件的调用返回了错误 hresult e_fail