特征筛选_psi筛选特征-程序员宅基地
1. 单特征分析
1.1 简介
好特征可以从几个角度衡量:覆盖度,区分度,相关性,稳定性
1.2 覆盖度
1. 应用场景
- 采集类,授权类,第三方数据在使用前都会分析覆盖度
2. 分类
- 采集类 :如APP list (Android 手机 90%)
- 授权类:如爬虫数据(20% 30%覆盖度)GPS (有些产品要求必须授权)
3. 计算
- 一般会在两个层面上计算覆盖度(覆盖度 = 有数据的用户数/全体用户数)
- 全体存量客户
- 全体有信贷标签客户
4. 衍生
- 覆盖度可以衍生两个指标:缺失率,零值率
- 缺失率:一般就是指在全体有标签用户上的覆盖度
- 零值率:很多信贷类数据在数据缺失时会补零,所以需要统计零值率
- 业务越来越成熟,覆盖度可能会越来愈好,可以通过运营策略提升覆盖度
1.3 区分度
1. 简介
- 评估一个特征对好坏用户的区分性能的指标
2. 应用场金
- 可以把单特征当做模型,使用AUC, KS来评估特征区分度
- 在信贷领域,常用Information Value (IV)来评估单特征的区分度
3. 计算
- Information Value刻画了一个特征对好坏用户分布的区分程度
- IV值越大
- IV值越小
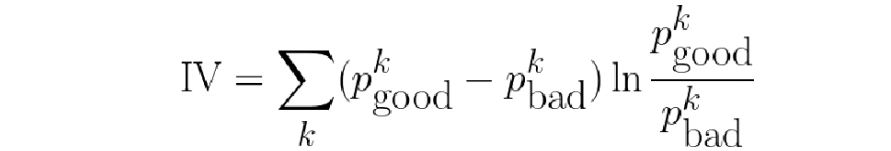
- IV值最后ln的部分跟WOE是一样的
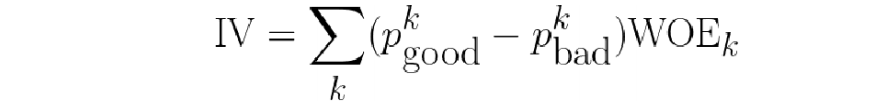
- IV计算举例(数据为了方便计算填充,不代表实际业务)

- IV<0.02 区分度小 建模时不用 (xgboost,lightGMB 对IV值要求不高)
- IV [0.02,0.5] 区分度大 可以放到模型里
- (IV> 0.1 考虑是否有未来信息)
- IV > 0.5 单独取出作为一条规则使用,不参与模型训练
4. 注意
- 模型中尽可能使用区分度相对较弱的特征,将多个弱特征组合,得到评分卡模型
- 连续变量的IV值计算,先离散化再求IV,跟分箱结果关联很大(一般分3-5箱)
1.4 相关性
1. 简介
- 对线性回归模型,有一条基本假设是自变量x1,x2,…,xp之间不存在严格的线性关系
2. 分类
- 需要对相关系数较大的特征进行筛选,只保留其中对标签区分贡献度最大的特征,即保留IV较大的
- 皮尔逊相关系数,斯皮尔曼相关系数,肯德尔相关系数
3. 选择
- 考察两个变量的相关关系,首先得清楚两个变量都是什么类型的
- 连续型数值变量,无序分类变量、有序分类变量
- 连续型数值变量,如果数据具有正态性,此时首选Pearson相关系数,如果数据不服从正态分布,此时可选择
Spearman和Kendall系数 - 两个有序分类变量相关关系,可以使用Spearman相关系数
- 一个分类变量和一个连续数值变量,可以使用kendall相关系数
- 总结:就适用性来说,kendall > spearman > pearson
4. 计算
import pandas as pd
df = pd.DataFrame({'A':[5,91,3],'B':[90,15,66],'C':[93,27,3]})
df.corr() # 皮尔逊
df.corr('spearman')#斯皮尔曼
df.corr('kendall')#肯德尔
- 可以使用toad库来过滤大量的特征,高缺失率、低iv和高度相关的特征一次性过滤掉
import pandas as pd
import toad data = pd.read_csv('data/germancredit.csv')
data.replace({'good':0,'bad':1},inplace=True)
data.shape
#缺失率大于0.5,IV值小于0.05,相关性大于0.7来进行特征筛选
selected_data, drop_list= toad.selection.select(data,target = 'creditability', empty = 0.5, iv = 0.05, corr = 0.7, return_drop=True)
print('保留特征:',selected_data.shape[1],'缺失删除:',len(drop_list['empty']),'低iv删 除:',len(drop_list['iv']),'高相关删除:',len(drop_list['corr']))
1.5 稳定性
1. 简介
- 主要通过计算不同时间段内同一类用户特征的分布的差异来评估
2. 分类
- 常用的特征稳定性的度量有Population Stability Index (PSI)
- 当两个时间段的特征分布差异大,则PSI大
- 当两个时间段的特征分布差异小,则PSI小
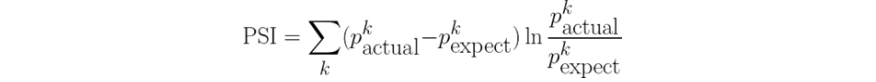
3. PSI和IV对比
- IV是评估好坏用户分布差异的度量
- PSI是评估两个时间段特征分布差异的度量
- 都是评估分布差异的度量,并且公式其实一模一样,只是符号换了而已
2. 多特征筛选
1. 简介
- 当构建了大量特征时,接下来的调整就是筛选出合适的特征进行模型训练
- 过多的特征会导致模型训练变慢,学习所需样本增多,计算特征和存储特征成本变高
2. 方法
- 星座特征
- Boruta
- 方差膨胀系数
- 后向筛选
- L1惩罚项
- 业务逻辑
2.1 星座特征
1. 简介
- 星座是公认没用的特征,区分度低于星座的特征可以认为是无用特征
2. 步骤
- 把所有特征加上星座特征一起做模型训练
- 拿到特征的重要度排序
- 多次训练的重要度排序都低于星座的特征可以剔除
2.2 Boruta
1. 简介
- Boruta算法是一种特征选择方法,使用特征的重要性来选取特征
- 网址:https://github.com/scikit-learn-contrib/boruta_py
- 安装:
pip install Boruta
2. 原理
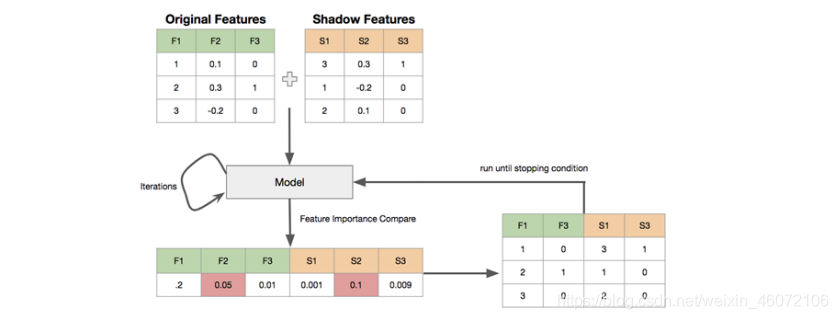
- 创建阴影特征 (shadow feature) : 对每个真实特征R,随机打乱顺序,得到阴影特征矩阵S,拼接到真实特征后面,构成新的特征
矩阵N = [R, S]. - 用新的特征矩阵N作为输入,训练模型,能输出feature_importances_的模型,如RandomForest, lightgbm,xgboost都可以得到真实特征和阴影特征的feature importances,
- 取阴影特征feature importance的最大值S_max,真实特征中feature importance小于S_max的,被认为是不重要的特征
- 删除不重要的特征,重复上述过程,直到满足条件
3. 应用
import numpy as np
import pandas as pd
import joblib
from sklearn.ensemble import RandomForestClassifier
from boruta import BorutaPy
#加载数据
pd_data = joblib.load('data/train_woe.pkl') pd_data
#处理数据,去掉id 和 目标值
pd_x = pd_data.drop(['SK_ID_CURR', 'TARGET'], axis=1)
x = pd_x.values # 特征
y = pd_data[['TARGET']].values # 目标
y = y.ravel() # 将多维数组降位一维
- 使用Boruta,选择features
# 先定义一个随机森林分类器
rf = RandomForestClassifier(n_jobs=-1, class_weight='balanced', max_depth=5)
'''
BorutaPy function
estimator : 所使用的分类器
n_estimators : 分类器数量, 默认值 = 1000
max_iter : 最大迭代次数, 默认值 = 100
'''
feat_selector = BorutaPy(rf, n_estimators='auto', random_state=1, max_iter=10)
feat_selector.fit(x, y)
- 展示选择出来的feature
dic_ft_select = dict()
# feat_selector.support_ # 返回特征是否有用,false可以去掉
for ft, seleted in zip(pd_x.columns.to_list(), feat_selector.support_):
dic_ft_select[ft] = seleted
pd_ft_select = pd.DataFrame({'feature':pd_x.columns.to_list(), "selected": feat_selector.support_})
pd_ft_selec
2.3 方差膨胀系数 (VIF)
1. 简介
- 方差膨胀系数 Variance inflation factor (VIF)
- 如果一个特征是其他一组特征的线性组合,则不会在模型中提供额外的信息,可以去掉
- 评估共线性程度:
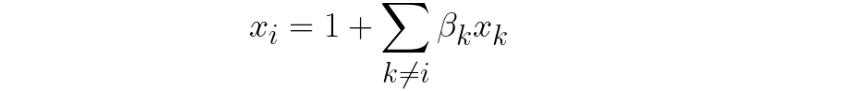
2. 计算
- VF计算:

- VIF越大说明拟合越好,该特征和其他特征组合共线性越强,就越没有信息量,可以剔除
5.3 应用
- 加载数据
import numpy as np
import pandas as pd
import joblib
from statsmodels.stats.outliers_influence import variance_inflation_factor
pd_data = joblib.load('./train_woe.pkl') #去掉ID和目标值
pd_x = pd_data.drop(['SK_ID_CURR', 'TARGET'], axis=1)
- 计算方差膨胀系数
#定义计算函数
def checkVIF_new(df):
lst_col = df.columns
x = np.matrix(df)
VIF_list = [variance_inflation_factor(x,i) for i in range(x.shape[1])]
VIF = pd.DataFrame({'feature':lst_col,"VIF":VIF_list})
max_VIF = max(VIF_list) print(max_VIF)
return VIF
df_vif = checkVIF_new(pd_x)
df_vif
- 选取方差膨胀系数 > 3的features
df_vif[df_vif['VIF'] > 3]
2.4 RFE 递归特征消除 (Recursive Feature Elimination)
1. 简介
- 使用排除法的方式训练模型,把模型性能下降最少的那个特征去掉,反复上述训练直到达到指定的特征个数
6.2 api
sklearn.feature_selection.RFE
6.3 应用
- 加载数据
import numpy as np
import pandas as pd
import joblib from sklearn.feature_selection
import RFE from sklearn.svm
import SVR pd_data = joblib.load('data/final_data.pkl')
pd_data
- 特征,目标提取
pd_x = pd_data.drop(['SK_ID_CURR', 'TARGET'], axis=1)
x = pd_x.values
y = pd_data[['TARGET']].values
y = y.ravel()
- 使用RFE,选择features
#定义分类器
estimator = SVR(kernel="linear")
selector = RFE(estimator, 3, step=1) # step 一次去掉几个特征
selector = selector.fit(x, y)
#展示选择参数
dic_ft_select = dict()
for ft, seleted in zip(pd_x.columns.to_list(), selector.support_):
dic_ft_select[ft] = seleted
pd_ft_select = pd.DataFrame({'feature':pd_x.columns.to_list(), "selected": selector.support_})
pd_ft_select
2.5 基于L1的特征选择 (L1-based feature selection)
1. 简介
- 使用L1范数作为惩罚项的线性模型(Linear models)会得到稀疏解:大部分特征对应的系数为0
- 希望减少特征维度用于其它分类器时,可以通过 feature_selection.SelectFromModel 来选择不为0的系数
- 特别指出,常用于此目的的稀疏预测模型有 linear_model.Lasso(回归), linear_model.LogisticRegression 和 svm.LinearSVC(分类)
7.3 应用
from sklearn.svm import LinearSVC
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectFromModel
iris = load_iris() X, y = iris.data, iris.target
X.shape
lsvc = LinearSVC(C=0.01, penalty="l1", dual=False).fit(X, y)
model = SelectFromModel(lsvc, prefit=True)
X_new = model.transform(X)
X_new.shape
3. 内部特征的监控
3.1 前端监控(授信之前)
- 特征稳定性
- 大多数情况下,随着业务越来越稳定,缺失率应该呈现逐渐降低的趋势
- 如下表所示,Week3缺失率突然增加到28%,大概率是数据采集或传输过程出问题了
- PSI,特征维度的PSI如果>0.1可以观察一段时间

3.2 后端监控(放款之后)
- 特征区分度
- AUC/KS 波动在10%以内
- KS 如果是线上A卡 0.2是合格的水平
- IV值的波动稍大可以容忍,和分箱相关,每周数据分布情况可能不同,对IV影响大一些

- 分箱样本比例:

- 分箱风险区分:要重视每个特征的风险趋势单调性
- 每一箱 的bad_rate有波动,容忍度相对高一些
- 要高度重视不同箱之间风险趋势发生变化,如分箱1,分箱2,在week2和week3 风险趋势发生了变化
- 如果风险趋势单调性发生变化,要考虑特征是不是要进行迭代

4. 外部特征评估
4.1 数据评估标准
- 覆盖度、区分度、稳定性
4.2 使用外部数据注意事项
1. 避免未来信息
- 使用外部数据的时候,可能出现训练模型的时候效果好,上线之后效果差
- 取最近一个时间周期的数据
- 之前3~4个月或者更长时间的数据做验证,看效果是不是越来越差
2. 外部数据覆盖度计算
- 交集用户数 / 内部用户数
- 外部数据选择
- 如果外部数据免费,那么全部调用,但付费的三方数据要在有必要的时候在调用
- 在计算外部数据覆盖度前,首先应该明确什么客群适合这个第三方数据
- 内部缺少数据且这个第三方数据能提升区分度,那这个第三方数据才有用
- 覆盖度 = 交集用户数 / 内部目标客群
3. 避免内部数据泄露
- 如果需要把数据交给外部公司,让对方匹配一定要将内部信息做Hash处理再给对方匹配

- 匹配上的是共有的数据,匹配不上的外部无法得知其身份
4. 避免三方公司对结果美化
- 内部自己调用接口测覆盖度直接调用即可
- 如果是把样本交给外部公司让对方匹配,一定要加假样本
- 这样他们只能匹配出结果,但无法得知真实的覆盖度
- 只有内部公司能区分出真假样本,从而计算出真实覆盖度
- 如果覆盖度高于真实样本比例,说明结果作假
5. 评分型外部数据
- 区分度和稳定性的分析方法同单特征的分析一样
- 区分度:AUC, KS, IV, 风险趋势
- 稳定性: PSI
6. 模型效果
- 内部特征训练的模型效果 vs 内部特征+外部特征训练的模型效果
- AUC有 2~3个点的提升就很好了
7. 黑名单型外部数据
- 使用混淆矩阵评估区分度
·

- Precision: 外部命中的尽可能多的是内部的坏客户
- Recall: 内部的坏客户尽可能多的命中外部名单
8. 回溯性
- 外部数据是否具有可回溯性无法得知,所以尽可能取最近的样本去测
早期接入数据后要密切关注线上真实的区分度表现
智能推荐
用java Swing做的小游戏"像素鸟"_java swing小游戏-程序员宅基地
文章浏览阅读4.4k次,点赞10次,收藏38次。最终效果 整个项目都是基于swing实现的。窗是口将图片加载到JPanel面板,然后将面板添加到到JFrame窗口实现显示。这个类是选择几只像素鸟的类,也是main函数里执行的方法,代码有详细的注释,这里就不废话了public class select extends JPanel { /** * */ private static final long serialVersio..._java swing小游戏
三分钟教你读懂支票是什么_支票的原理是什么-程序员宅基地
文章浏览阅读8.7k次。三分钟教你读懂支票是什么支票1、支票的概念及特点支票:出票人签发的,委托办理支票存款业务的银行或其他金融机构在见票时无条件支付确定金额给收款人或持票人的票据。支票必填项:支票字样、确定的金额、出票日期、无条件支付委托、付款人名称、出票人签章。支票选填项:付款地、出票地。支票结算特点:(1)简便,手续_支票的原理是什么
山东工商学院 计算机科学与技术,实验中心-山东工商学院计算机科学与技术学院...-程序员宅基地
文章浏览阅读148次。计算机教学实验中心成立于1999年,隶属计算机科学与技术学院。实验中心现有软件、电子、网络、通信、大学生科技创新、AR技术研究所等41间实验室,实验面积5600平方米,固定资产3500万元,教(职)工26人。实验中心以先进精良的设备条件、整洁舒适的教学环境、科学严谨的管理方式为计算机科学与技术学院、信息与电子工程学院、管理科学与工程学院等学院的实验教学、课程设计、毕业设计等实践环节和全院计算机公共..._计算机科学与技术实验教学中心 山东
CUDA ERROR: device-side assert triggered at 问题及解决思路-程序员宅基地
文章浏览阅读10w+次,点赞45次,收藏82次。cuda errorRuntimeError: cuda runtime error (59) : device-side assert triggered at ...我之前还以为是因为GPU抽风了引发的BUG,所以第一次没有在意,直接又重新开始运行了一次,但是第二次就发现程序在同样的地方断掉了,这也就想起来我以前看到的一个博客,里面有句话的大概意思是这样的:每次都在同样的地方出错的..._cuda error: device-side assert triggered
HDOJ1556 树状数组简单应用_hdoj 树状数组基础-程序员宅基地
文章浏览阅读251次。Color the ballTime Limit: 9000/3000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submission(s): 23142 Accepted Submission(s): 11237Problem DescriptionN个气球排成一排,_hdoj 树状数组基础
浅析HTML_解析html-程序员宅基地
文章浏览阅读430次。HTML面试题整理以及一些自我理解_解析html
随便推点
chatgpt赋能python:Python如何分离CSV的列_python的csv拆列-程序员宅基地
文章浏览阅读270次。CSV文件是一种以逗号或其他分隔符分隔的文件格式,用于存储表格数据。它可以用任何文本编辑器打开,并且非常适合在电子表格程序(例如Microsoft Excel或Google Sheets)中打开和处理。CSV文件通常由一组记录组成,每条记录包含一个或多个字段。字段之间使用逗号或其他指定的分隔符分隔。CSV文件中的第一行通常包含列标题,这些标题描述了每个字段的含义。Jack,19,UK本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。_python的csv拆列
MYSQL8安全之SSL认证_mysql ssl-程序员宅基地
文章浏览阅读5.4k次,点赞3次,收藏17次。MYSQL8安全之SSL认证_mysql ssl
Java Swing 如何使用JTree(1)_swing 如何初始化一个jtree-程序员宅基地
文章浏览阅读3k次,点赞2次,收藏6次。Java Swing 如何使用JTree_swing 如何初始化一个jtree
Go 语言到底适合干什么?_对java开发者来说 go 能做什么-程序员宅基地
文章浏览阅读115次。Go 语言对于构建微服务和 API 很有优势,因为它的代码结构简单,易于维护,同时具有高效和高并发特性。由于云计算中的系统通常是分布式的,Go 语言的并发编程模型非常适合用于处理云计算中的任务。由于 Go 语言具有高效和高性能的特性,因此它非常适合用于构建 Web 应用程序。Go 语言原生支持高效的并发编程,因此非常适合用于构建网络应用程序和分布式系统。Go 语言具有高效的执行性能和并发处理能力,因此很适合用于处理大量数据。Go 语言的语言特性、安全性和执行效率都非常适合用于系统编程领域。_对java开发者来说 go 能做什么
【虚拟仿真】Unity3D中拆分模型教程(多种类型模型拆分)_unity怎么拆分模型-程序员宅基地
文章浏览阅读1.4w次,点赞63次,收藏160次。推荐阅读CSDN主页GitHub开源地址Unity3D插件分享简书地址我的个人博客QQ群:1040082875大家好,我是佛系工程师☆恬静的小魔龙☆,不定时更新Unity开发技巧,觉得有用记得一键三连哦。一、前言今天有小伙伴在我这篇文章【虚拟仿真】Unity3D对物体进行拆分实现下面问我如何一秒一拆:虽然我已经给出了思路,但是离实现还是有点思路,正好我对于我这篇文章也是不满意,就解答一下小伙伴的疑惑,然后再将文章内容进行升级。原文章:【虚拟仿真】Unity3D对物体进行拆分实._unity怎么拆分模型
ChatGLM2本地部署的实战方案-程序员宅基地
文章浏览阅读10w+次,点赞55次,收藏74次。本文主要介绍了ChatGLM2本地部署应用的实战方案,希望对学习大语言模型的同学们有所帮助。文章目录1. 介绍2. 配置环境 2.1 安装虚拟环境 2.2 安装依赖库3. 下载权重文件4. 运行ChatGLM2 4.1 方式一 4.2 方式二_chatglm2