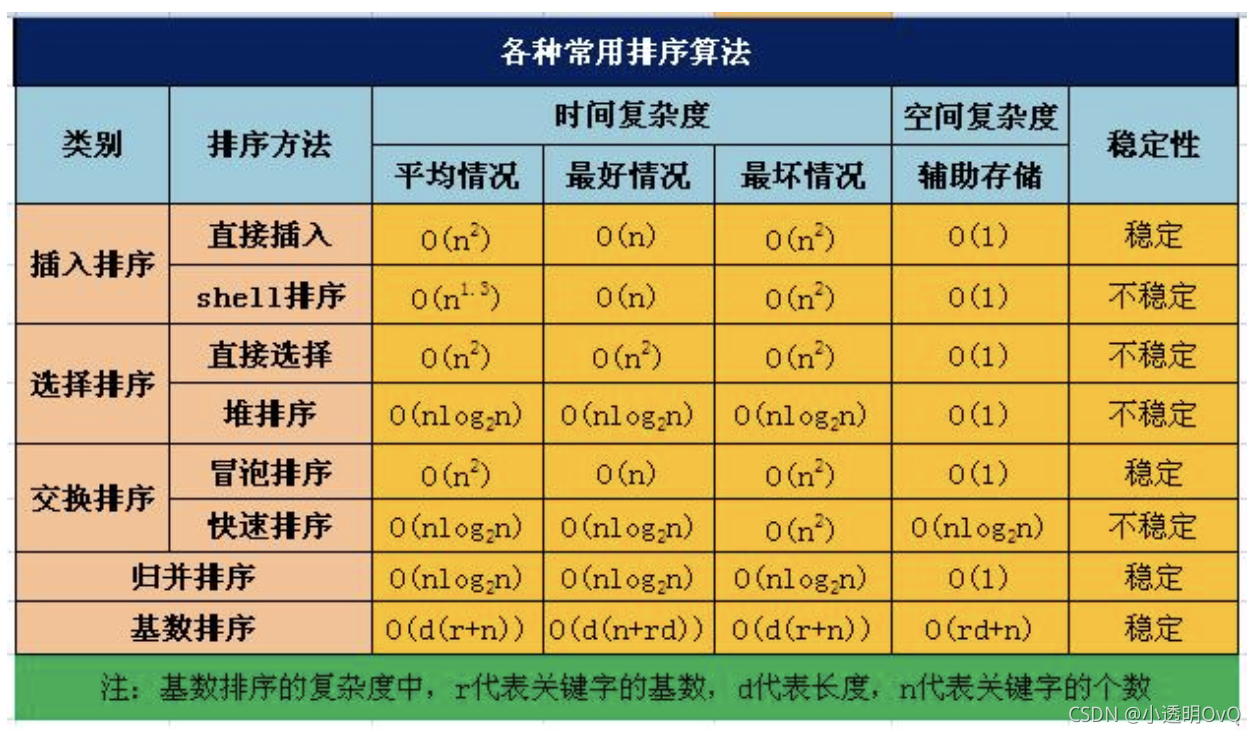
八大排序算法的Java实现-程序员宅基地
内容参考此链接,感谢。
一、插入排序
1. 直接插入排序
/**
* 插入排序
*
* 1. 从第一个元素开始,该元素可以认为已经被排序
* 2. 取出下一个元素,在已经排序的元素序列中从后向前扫描
* 3. 如果该元素(已排序)大于新元素,将该元素移到下一位置
* 4. 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
* 5. 将新元素插入到该位置后
* 6. 重复步骤2~5
* @param arr 待排序数组
*/
public static void insertionSort(int[] arr){
for(int i=1;i<arr.length;i++){
int temp = arr[i]; // 记录一下这个要排序的值
for(int j=i;j>=0;j--){
if(j>0&&arr[j-1]>temp){
arr[j]=arr[j-1];
}else{
// 要么到头了,就是j=0,要么就是arr[j-1]<temp
arr[j]=temp;
break; // 当前这个temp已经放进去了,那就退出最里层的for循环
}
}
}
}
2. 希尔排序
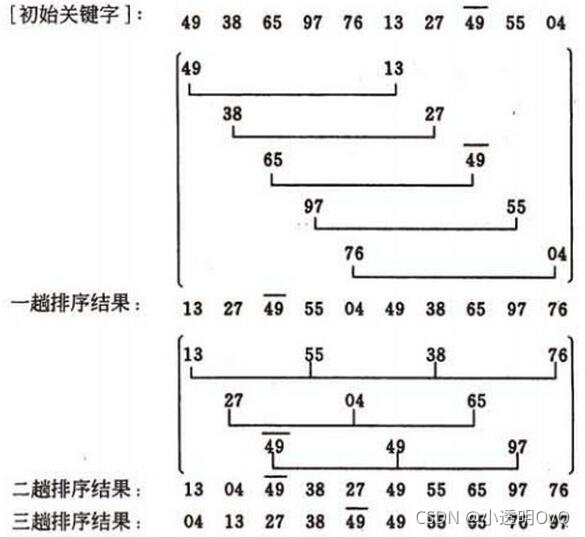
/**
* 希尔排序
*
* 1. 选择一个增量序列t1,t2,…,tk,其中ti>tj,tk=1;(一般初次取数组半长,之后每次再减半,直到增量为1)
* 2. 按增量序列个数k,对序列进行k趟排序;
* 3. 每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m 的子序列,分别对各子表进行直接插入排序。
* 仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
* @param arr 待排序数组
*/
public class ShellSort {
public static void main(String[] args)
{
int[] ins = {
2,3,5,1,23,6,78,34,23,4,5,78,34,65,32,65,76,32,76,1,9};
int[] ins2 = shellSort(ins);
for(int in: ins2){
System.out.print(in+" ");
}
}
public static int[] shellSort(int[] arr){
int gap = arr.length/2;
for(;gap>0;gap/=2){
// gap不断缩小,直到gap=1
for(int i=0;i<gap;i++){
for(int j=i+gap;j<arr.length;j+=gap){
int temp = arr[j];
int k = j - gap;
while(k>=0&&arr[k]>temp){
arr[k+gap] = arr[k];
k-=gap;
}
arr[k + gap] = temp;
}
}
}
return arr;
}
}
二、选择排序
1. 简单选择排序/直接选择排序
/**
* 选择排序
*
* 1. 从待排序序列中,找到关键字最小的元素;
* 2. 如果最小元素不是待排序序列的第一个元素,将其和第一个元素互换;
* 3. 从余下的 N - 1 个元素中,找出关键字最小的元素,重复①、②步,直到排序结束。
* 仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
* @param arr 待排序数组
*/
public static void selectionSort(int[] arr){
for(int i=0;i<arr.length;i++){
int min = i;
for(int j=i+1;j<arr.length;j++){
if(arr[j]<arr[min]){
min=j;
}
}
if(min!=i){
int temp = arr[min];
arr[min] = arr[i];
arr[i] = temp;
}
}
}
2. 堆排序(不想看了 想吐了)
/**
* 堆排序
*
* 1. 先将初始序列K[1..n]建成一个大顶堆, 那么此时第一个元素K1最大, 此堆为初始的无序区.
* 2. 再将关键字最大的记录K1 (即堆顶, 第一个元素)和无序区的最后一个记录 Kn 交换, 由此得到新的无序区K[1..n−1]和有序区K[n], 且满足K[1..n−1].keys⩽K[n].key
* 3. 交换K1 和 Kn 后, 堆顶可能违反堆性质, 因此需将K[1..n−1]调整为堆. 然后重复步骤②, 直到无序区只有一个元素时停止.
* @param arr 待排序数组
*/
public static void heapSort(int[] arr){
for(int i = arr.length; i > 0; i--){
max_heapify(arr, i);
int temp = arr[0]; //堆顶元素(第一个元素)与Kn交换
arr[0] = arr[i-1];
arr[i-1] = temp;
}
}
private static void max_heapify(int[] arr, int limit){
if(arr.length <= 0 || arr.length < limit) return;
int parentIdx = limit / 2;
for(; parentIdx >= 0; parentIdx--){
if(parentIdx * 2 >= limit){
continue;
}
int left = parentIdx * 2; //左子节点位置
int right = (left + 1) >= limit ? left : (left + 1); //右子节点位置,如果没有右节点,默认为左节点位置
int maxChildId = arr[left] >= arr[right] ? left : right;
if(arr[maxChildId] > arr[parentIdx]){
//交换父节点与左右子节点中的最大值
int temp = arr[parentIdx];
arr[parentIdx] = arr[maxChildId];
arr[maxChildId] = temp;
}
}
System.out.println("Max_Heapify: " + Arrays.toString(arr));
}
三、交换排序
1. 冒泡排序
/**
* 冒泡排序
*
* 冒泡排序只会操作相邻的两个数据。每次冒泡操作都会对相邻的两个元素进行比较,看是否满足大小关系要求。
* 如果不满足就让它俩互换。一次冒泡会让至少一个元素移动到它应该在的位置,重复n次,就完成了 n 个数据的排序工作。
**/
public class BubbleSort {
public void bubbleSort(Integer[] arr, int n) {
if (n <= 1) return; //如果只有一个元素就不用排序了
for (int i = 0; i < n; ++i) {
// 提前退出冒泡循环的标志位,即一次比较中没有交换任何元素,这个数组就已经是有序的了
boolean flag = false;
for (int j = 0; j < n - i - 1; ++j) {
//此处你可能会疑问的j<n-i-1,因为冒泡是把每轮循环中较大的数飘到后面,
// 数组下标又是从0开始的,i下标后面已经排序的个数就得多减1,总结就是i增多少,j的循环位置减多少
if (arr[j] > arr[j + 1]) {
//即这两个相邻的数是逆序的,交换
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
flag = true;
}
}
if (!flag) break;//没有数据交换,数组已经有序,退出排序
}
}
public static void main(String[] args) {
Integer arr[] = {
2, 4, 7, 6, 8, 5, 9};
SortUtil.show(arr);
BubbleSort bubbleSort = new BubbleSort();
bubbleSort.bubbleSort(arr, arr.length);
SortUtil.show(arr);
}
}
2. 快速排序
/**
* 快速排序(递归)
*
* ①. 从数列中挑出一个元素,称为"基准"(pivot)。
* ②. 重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
* ③. 递归地(recursively)把小于基准值元素的子数列和大于基准值元素的子数列排序。
* @param arr 待排序数组
* @param low 左边界
* @param high 右边界
*/
public static void quickSort(int[] arr, int low, int high){
if(arr.length <= 0) return;
if(low >= high) return;
int left = low;
int right = high;
int temp = arr[left]; //挖坑1:保存基准的值
while (left < right){
while(left < right && arr[right] >= temp){
//坑2:从后向前找到比基准小的元素,插入到基准位置坑1中
right--;
}
arr[left] = arr[right];
while(left < right && arr[left] <= temp){
//坑3:从前往后找到比基准大的元素,放到刚才挖的坑2中
left++;
}
arr[right] = arr[left];
}
arr[left] = temp; //基准值填补到坑3中,准备分治递归快排
System.out.println("Sorting: " + Arrays.toString(arr));
quickSort(arr, low, left-1);
quickSort(arr, left+1, high);
}
四、归并排序
/**
* 归并排序(递归)
*
* ①. 将序列每相邻两个数字进行归并操作,形成 floor(n/2)个序列,排序后每个序列包含两个元素;
* ②. 将上述序列再次归并,形成 floor(n/4)个序列,每个序列包含四个元素;
* ③. 重复步骤②,直到所有元素排序完毕。
* @param arr 待排序数组
*/
public static int[] mergingSort(int[] arr){
if(arr.length <= 1) return arr;
int num = arr.length >> 1;
int[] leftArr = Arrays.copyOfRange(arr, 0, num);
int[] rightArr = Arrays.copyOfRange(arr, num, arr.length);
System.out.println("split two array: " + Arrays.toString(leftArr) + " And " + Arrays.toString(rightArr));
return mergeTwoArray(mergingSort(leftArr), mergingSort(rightArr)); //不断拆分为最小单元,再排序合并
}
private static int[] mergeTwoArray(int[] arr1, int[] arr2){
int i = 0, j = 0, k = 0;
int[] result = new int[arr1.length + arr2.length]; //申请额外的空间存储合并之后的数组
while(i < arr1.length && j < arr2.length){
//选取两个序列中的较小值放入新数组
if(arr1[i] <= arr2[j]){
result[k++] = arr1[i++];
}else{
result[k++] = arr2[j++];
}
}
while(i < arr1.length){
//序列1中多余的元素移入新数组
result[k++] = arr1[i++];
}
while(j < arr2.length){
//序列2中多余的元素移入新数组
result[k++] = arr2[j++];
}
System.out.println("Merging: " + Arrays.toString(result));
return result;
}
五、归并排序
/**
* 基数排序(LSD 从低位开始)
*
* 基数排序适用于:
* (1)数据范围较小,建议在小于1000
* (2)每个数值都要大于等于0
*
* ①. 取得数组中的最大数,并取得位数;
* ②. arr为原始数组,从最低位开始取每个位组成radix数组;
* ③. 对radix进行计数排序(利用计数排序适用于小范围数的特点);
* @param arr 待排序数组
*/
public static void radixSort(int[] arr){
if(arr.length <= 1) return;
//取得数组中的最大数,并取得位数
int max = 0;
for(int i = 0; i < arr.length; i++){
if(max < arr[i]){
max = arr[i];
}
}
int maxDigit = 1;
while(max / 10 > 0){
maxDigit++;
max = max / 10;
}
System.out.println("maxDigit: " + maxDigit);
//申请一个桶空间
int[][] buckets = new int[10][arr.length-1];
int base = 10;
//从低位到高位,对每一位遍历,将所有元素分配到桶中
for(int i = 0; i < maxDigit; i++){
int[] bktLen = new int[10]; //存储各个桶中存储元素的数量
//分配:将所有元素分配到桶中
for(int j = 0; j < arr.length; j++){
int whichBucket = (arr[j] % base) / (base / 10);
buckets[whichBucket][bktLen[whichBucket]] = arr[j];
bktLen[whichBucket]++;
}
//收集:将不同桶里数据挨个捞出来,为下一轮高位排序做准备,由于靠近桶底的元素排名靠前,因此从桶底先捞
int k = 0;
for(int b = 0; b < buckets.length; b++){
for(int p = 0; p < bktLen[b]; p++){
arr[k++] = buckets[b][p];
}
}
System.out.println("Sorting: " + Arrays.toString(arr));
base *= 10;
}
}
智能推荐
分布式光纤传感器的全球与中国市场2022-2028年:技术、参与者、趋势、市场规模及占有率研究报告_预计2026年中国分布式传感器市场规模有多大-程序员宅基地
文章浏览阅读3.2k次。本文研究全球与中国市场分布式光纤传感器的发展现状及未来发展趋势,分别从生产和消费的角度分析分布式光纤传感器的主要生产地区、主要消费地区以及主要的生产商。重点分析全球与中国市场的主要厂商产品特点、产品规格、不同规格产品的价格、产量、产值及全球和中国市场主要生产商的市场份额。主要生产商包括:FISO TechnologiesBrugg KabelSensor HighwayOmnisensAFL GlobalQinetiQ GroupLockheed MartinOSENSA Innovati_预计2026年中国分布式传感器市场规模有多大
07_08 常用组合逻辑电路结构——为IC设计的延时估计铺垫_基4布斯算法代码-程序员宅基地
文章浏览阅读1.1k次,点赞2次,收藏12次。常用组合逻辑电路结构——为IC设计的延时估计铺垫学习目的:估计模块间的delay,确保写的代码的timing 综合能给到多少HZ,以满足需求!_基4布斯算法代码
OpenAI Manager助手(基于SpringBoot和Vue)_chatgpt网页版-程序员宅基地
文章浏览阅读3.3k次,点赞3次,收藏5次。OpenAI Manager助手(基于SpringBoot和Vue)_chatgpt网页版
关于美国计算机奥赛USACO,你想知道的都在这_usaco可以多次提交吗-程序员宅基地
文章浏览阅读2.2k次。USACO自1992年举办,到目前为止已经举办了27届,目的是为了帮助美国信息学国家队选拔IOI的队员,目前逐渐发展为全球热门的线上赛事,成为美国大学申请条件下,含金量相当高的官方竞赛。USACO的比赛成绩可以助力计算机专业留学,越来越多的学生进入了康奈尔,麻省理工,普林斯顿,哈佛和耶鲁等大学,这些同学的共同点是他们都参加了美国计算机科学竞赛(USACO),并且取得过非常好的成绩。适合参赛人群USACO适合国内在读学生有意向申请美国大学的或者想锻炼自己编程能力的同学,高三学生也可以参加12月的第_usaco可以多次提交吗
MySQL存储过程和自定义函数_mysql自定义函数和存储过程-程序员宅基地
文章浏览阅读394次。1.1 存储程序1.2 创建存储过程1.3 创建自定义函数1.3.1 示例1.4 自定义函数和存储过程的区别1.5 变量的使用1.6 定义条件和处理程序1.6.1 定义条件1.6.1.1 示例1.6.2 定义处理程序1.6.2.1 示例1.7 光标的使用1.7.1 声明光标1.7.2 打开光标1.7.3 使用光标1.7.4 关闭光标1.8 流程控制的使用1.8.1 IF语句1.8.2 CASE语句1.8.3 LOOP语句1.8.4 LEAVE语句1.8.5 ITERATE语句1.8.6 REPEAT语句。_mysql自定义函数和存储过程
半导体基础知识与PN结_本征半导体电流为0-程序员宅基地
文章浏览阅读188次。半导体二极管——集成电路最小组成单元。_本征半导体电流为0
随便推点
【Unity3d Shader】水面和岩浆效果_unity 岩浆shader-程序员宅基地
文章浏览阅读2.8k次,点赞3次,收藏18次。游戏水面特效实现方式太多。咱们这边介绍的是一最简单的UV动画(无顶点位移),整个mesh由4个顶点构成。实现了水面效果(左图),不动代码稍微修改下参数和贴图可以实现岩浆效果(右图)。有要思路是1,uv按时间去做正弦波移动2,在1的基础上加个凹凸图混合uv3,在1、2的基础上加个水流方向4,加上对雾效的支持,如没必要请自行删除雾效代码(把包含fog的几行代码删除)S..._unity 岩浆shader
广义线性模型——Logistic回归模型(1)_广义线性回归模型-程序员宅基地
文章浏览阅读5k次。广义线性模型是线性模型的扩展,它通过连接函数建立响应变量的数学期望值与线性组合的预测变量之间的关系。广义线性模型拟合的形式为:其中g(μY)是条件均值的函数(称为连接函数)。另外,你可放松Y为正态分布的假设,改为Y 服从指数分布族中的一种分布即可。设定好连接函数和概率分布后,便可以通过最大似然估计的多次迭代推导出各参数值。在大部分情况下,线性模型就可以通过一系列连续型或类别型预测变量来预测正态分布的响应变量的工作。但是,有时候我们要进行非正态因变量的分析,例如:(1)类别型.._广义线性回归模型
HTML+CSS大作业 环境网页设计与实现(垃圾分类) web前端开发技术 web课程设计 网页规划与设计_垃圾分类网页设计目标怎么写-程序员宅基地
文章浏览阅读69次。环境保护、 保护地球、 校园环保、垃圾分类、绿色家园、等网站的设计与制作。 总结了一些学生网页制作的经验:一般的网页需要融入以下知识点:div+css布局、浮动、定位、高级css、表格、表单及验证、js轮播图、音频 视频 Flash的应用、ul li、下拉导航栏、鼠标划过效果等知识点,网页的风格主题也很全面:如爱好、风景、校园、美食、动漫、游戏、咖啡、音乐、家乡、电影、名人、商城以及个人主页等主题,学生、新手可参考下方页面的布局和设计和HTML源码(有用点赞△) 一套A+的网_垃圾分类网页设计目标怎么写
C# .Net 发布后,把dll全部放在一个文件夹中,让软件目录更整洁_.net dll 全局目录-程序员宅基地
文章浏览阅读614次,点赞7次,收藏11次。之前找到一个修改 exe 中 DLL地址 的方法, 不太好使,虽然能正确启动, 但无法改变 exe 的工作目录,这就影响了.Net 中很多获取 exe 执行目录来拼接的地址 ( 相对路径 ),比如 wwwroot 和 代码中相对目录还有一些复制到目录的普通文件 等等,它们的地址都会指向原来 exe 的目录, 而不是自定义的 “lib” 目录,根本原因就是没有修改 exe 的工作目录这次来搞一个启动程序,把 .net 的所有东西都放在一个文件夹,在文件夹同级的目录制作一个 exe._.net dll 全局目录
BRIEF特征点描述算法_breif description calculation 特征点-程序员宅基地
文章浏览阅读1.5k次。本文为转载,原博客地址:http://blog.csdn.net/hujingshuang/article/details/46910259简介 BRIEF是2010年的一篇名为《BRIEF:Binary Robust Independent Elementary Features》的文章中提出,BRIEF是对已检测到的特征点进行描述,它是一种二进制编码的描述子,摈弃了利用区域灰度..._breif description calculation 特征点
房屋租赁管理系统的设计和实现,SpringBoot计算机毕业设计论文_基于spring boot的房屋租赁系统论文-程序员宅基地
文章浏览阅读4.1k次,点赞21次,收藏79次。本文是《基于SpringBoot的房屋租赁管理系统》的配套原创说明文档,可以给应届毕业生提供格式撰写参考,也可以给开发类似系统的朋友们提供功能业务设计思路。_基于spring boot的房屋租赁系统论文