最优二叉查找树(动态规划)——详解_最优二叉搜索树-程序员宅基地
最优二叉查找树
(1)二叉查找树(二分检索树)二叉搜索树
T是一棵二元树,它或者为空,或者其每个结点含有一个可以比较大小的数据元素,且有:
- T的左子树的所有元素比根结点中的元素小;
- T的右子树的所有元素比根结点中的元素大;
- T的左子树和右子树也是二叉搜索树。
(2)最优二叉搜索树
给定一个n个关键字的已排序的序列K=<k 1 ,k 2 ,…,k n >( 不失一般性,设k 1 <k 2 <…<k n ),对每个关键字k i ,都有一个概率p i 表示其搜索频率。根据k i和p i 构建一个二叉搜索树T,每个k i 对应树中的一个结点。若搜索对象x等于某个k i ,则一定可以在T中找到结点k i ;若x<k 1 或 x>k n 或 k i <x<k i+1 (1≤i<n), 则在T中将搜索失败。为此引入外部结点d 0 ,d 1 ,…,d n ,用来表示不在K中的值,称为伪结点。这里每个d i 代表一个区间, d 0 表示所有小于k 1 的值, d n 表示所有大于k n 的值,对于i=1,2,…,n-1,d i 表示所有在k i 和k i+1 之间的值。 同时每个d i 也有一个概率qi 表示搜索对象x恰好落入区间d i 的频率。
(3)例
设有n=5个关键字的集合,每个k i 的概率p i 和d i 的概率q i 如表所示:其中

基于该集合,两棵可能的二叉搜索树如下所示。
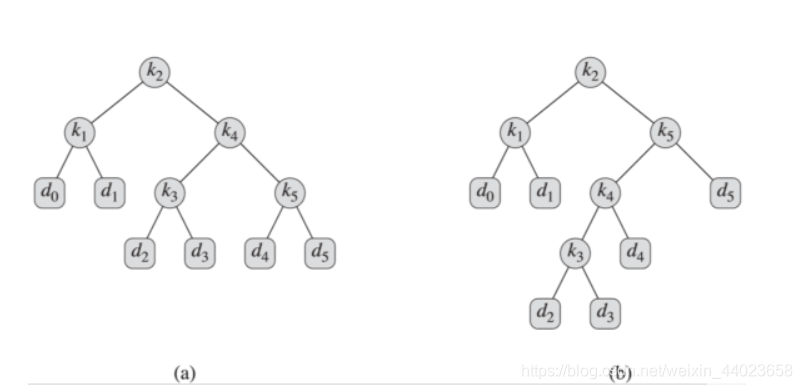 (4)二叉搜索树的期望搜索代价代价等于从根结点开始访问结点的数量。
(4)二叉搜索树的期望搜索代价代价等于从根结点开始访问结点的数量。
从根结点开始访问结点的数量等于结点在T中的深度+1; 二叉搜索树T的期望代价记depth T (i)为结点i在T中的深度,则T搜索代价的期望为:
E [ search cost in T ] = ∑ i = 1 n ( depth T ( k i ) + 1 ) ⋅ p i + ∑ i = 0 n ( depth T ( d i ) + 1 ) ⋅ q i = 1 + ∑ i = 1 n depth T ( k i ) ⋅ p i + ∑ i = 0 n depth T ( d i ) ⋅ q i \begin{aligned} \mathrm{E}[\text { search cost in } T] &=\sum_{i=1}^{n}\left(\operatorname{depth}_{T}\left(k_{i}\right)+1\right) \cdot p_{i}+\sum_{i=0}^{n}\left(\operatorname{depth}_{T}\left(d_{i}\right)+1\right) \cdot q_{i} \\ &=1+\sum_{i=1}^{n} \operatorname{depth}_{T}\left(k_{i}\right) \cdot p_{i}+\sum_{i=0}^{n} \operatorname{depth}_{T}\left(d_{i}\right) \cdot q_{i} \end{aligned} E[ search cost in T]=i=1∑n(depthT(ki)+1)⋅pi+i=0∑n(depthT(di)+1)⋅qi=1+i=1∑ndepthT(ki)⋅pi+i=0∑ndepthT(di)⋅qi
上面图中(a)的期望搜索代价为2.80。(b)的期望搜索代价为2.75。
最优二叉搜索树的定义对给定的概率集合,期望搜索代价最小的二叉搜索树称为最优二叉搜索树
- (1)最优二叉搜索树的最优子结构:如果一棵 最优二叉搜索树T T有一棵包含关键字k i ,…,k j 的子树T’,则T’必然是包含关键字ki ,…,k j 和伪关键字d i-1 ,…,d j 的子问题的最优解。
- (2)构造最优二叉搜索树利用最优二叉搜索树的最优子结构性来构造最优二叉搜索树。分析:
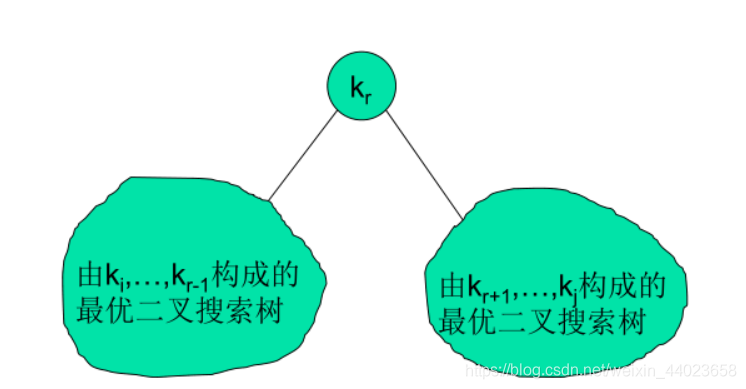
对给定的关键字k i ,…,k j ,若其最优二叉搜索树的根结点是k r(i≤r≤j),则k r 的左子树中包含关键字k i ,…,k r-1 及伪关键字d i-1,…,d r-1 ,右子树中将含关键字k i+1 ,…,k j 及伪关键字d r ,…,d j 。策略:检查所有可能的根结点k r (i≤r≤j),如果事先分别求出包含关键字k i ,…,k r-1 和关键字k r+1 ,…,k j 的最优二叉搜索子树,则可保证找到原问题的最优解。
- (3)计算过程: 求解包含关键字k i ,…,k j 的最优二叉搜索树,其中,i≥1,j≤n 且 j≥i-1。
定义e[i,j]:为包含关键字k i ,…,k j 的最优二叉搜索树的期望搜索代价。e[1,n]为问题的最终解。
当j≥i时,我们需要从k i ,…,k j 中选择一个根结点k r ,其左子树包含关键字k i ,…,k r-1 且是最优二叉搜索子树,其右子树包含关键字k r+1 ,…,k j 且为最优二叉搜索子树。
-
(4)若k r 为包含关键字k i ,…,k j的最优二叉搜索树(树根),则其期望搜索代价与左、右子树的期望搜索代价e[i,r-1]和e[r+1,j]有如下递推关系:
e [ i , j ] = p r + ( e [ i , r − 1 ] + w ( i , r − 1 ) ) + ( e [ r + 1 , j ] + w ( r + 1 , j ) ) e[i, j]=p_{r}+(e[i, r-1]+w(i, r-1))+(e[r+1, j]+w(r+1, j)) e[i,j]=pr+(e[i,r−1]+w(i,r−1))+(e[r+1,j]+w(r+1,j))
其中, w ( i , j ) = w ( i , r − 1 ) + p r + w ( r + 1 , j ) w(i, j)=w(i, r-1)+p_{r}+w(r+1, j) w(i,j)=w(i,r−1)+pr+w(r+1,j)
所以得出 e [ i , j ] = e [ i , r − 1 ] + e [ r + 1 , j ] + w ( i , j ) e[i, j]=e[i, r-1]+e[r+1, j]+w(i, j) e[i,j]=e[i,r−1]+e[r+1,j]+w(i,j) -
(5)有上面的分析,可以得到kr的递推公式
e [ i , j ] = { q i − 1 if j = i − 1 min i ≤ r ≤ j { e [ i , r − 1 ] + e [ r + 1 , j ] + w ( i , j ) } if i ≤ j e[i, j]=\left\{\begin{array}{ll}q_{i-1} & \text { if } j=i-1 \\ \min _{i \leq r \leq j}\{e[i, r-1]+e[r+1, j]+w(i, j)\} & \text { if } i \leq j\end{array}\right. e[i,j]={ qi−1mini≤r≤j{ e[i,r−1]+e[r+1,j]+w(i,j)} if j=i−1 if i≤j
边界条件:j=i-1,存在e[i, i-1]和e[j+1, j]的边界情况。此时,子树不包含实际的关键字,而只包含伪关键字d i-1 ,其期望搜索代价为: e [ i , i − 1 ] = q i − 1 e[i, i-1]=q_{i-1} e[i,i−1]=qi−1
- (6)构造最优二叉搜索树
定义root[i,j],保存计算e[i, j]时使e[i, j]取得最小值的r。在求出e[1,n]后,利用root的记录构造出整棵最优二叉搜索树。
- (7)计算最优二叉搜索树的期望搜索代价
e[1..n+1,0..n]:用于记录所有e[i,j]的值。注:e[n+1,n]对应伪关键字d n 的子树;e[1,0]对应伪关键字d 0 的子树。
root[1..n]:用于记录所有最优二叉搜索子树的根结点,包括整棵最优二叉搜索树的根。
w[1..n+1,0..n]:用于子树保存增加的期望搜索代价,
且有 w [ i , j ] = w [ i , j − 1 ] + p j + q j w[i, j]=w[i, j-1]+p_{j}+q_{j} w[i,j]=w[i,j−1]+pj+qj
这样,对于Θ(n 2 )个w[i,j],每个的计算时间仅为Θ(1)。

上面算法是构造root表的算法
举例说明
(1)给出一组数据
i 0 1 2 3 4 5 p i 0.15 0.10 0.05 0.10 0.20 q i 0.05 0.10 0.05 0.05 0.05 0.10 \begin{array}{c|cccccc} i & 0 & 1 & 2 & 3 & 4 & 5 \\ \hline p_{i} & & 0.15 & 0.10 & 0.05 & 0.10 & 0.20 \\ q_{i} & 0.05 & 0.10 & 0.05 & 0.05 & 0.05 & 0.10 \end{array} ipiqi00.0510.150.1020.100.0530.050.0540.100.0550.200.10
(2)根据 w [ i , j ] = w [ i , j − 1 ] + p j + q j w[i, j]=w[i, j-1]+p_{j}+q_{j} w[i,j]=w[i,j−1]+pj+qj求出w表的内容
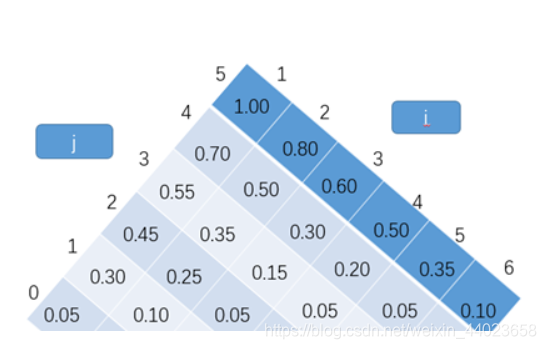
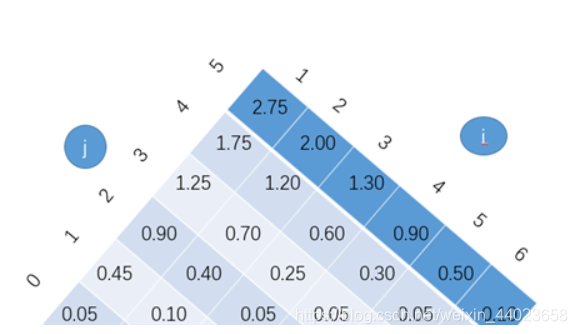
(3)根据
e [ i , j ] = { q i − 1 if j = i − 1 min i ≤ r ≤ j { e [ i , r − 1 ] + e [ r + 1 , j ] + w ( i , j ) } if i ≤ j e[i, j]=\left\{\begin{array}{ll}q_{i-1} & \text { if } j=i-1 \\ \min _{i \leq r \leq j}\{e[i, r-1]+e[r+1, j]+w(i, j)\} & \text { if } i \leq j\end{array}\right. e[i,j]={
qi−1mini≤r≤j{
e[i,r−1]+e[r+1,j]+w(i,j)} if j=i−1 if i≤j
求出e表的内容
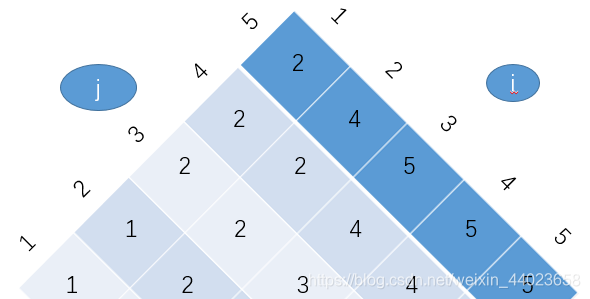
(4)最后根据上面的算法得出root表的内容
(5)下面给出C++的最优二叉搜索树的代码实现
1 #include <iostream>
2
3 using namespace std;
4
5 const int MaxVal = 9999;
6
7 const int n = 5;
8 //搜索到根节点和虚拟键的概率
9 double p[n + 1] = {
-1,0.15,0.1,0.05,0.1,0.2};
10 double q[n + 1] = {
0.05,0.1,0.05,0.05,0.05,0.1};
11
12 int root[n + 1][n + 1];//记录根节点
13 double w[n + 2][n + 2];//子树概率总和
14 double e[n + 2][n + 2];//子树期望代价
15
16 void optimalBST(double *p,double *q,int n)
17 {
18 //初始化只包括虚拟键的子树
19 for (int i = 1;i <= n + 1;++i)
20 {
21 w[i][i - 1] = q[i - 1];
22 e[i][i - 1] = q[i - 1];
23 }
24
25 //由下到上,由左到右逐步计算
26 for (int len = 1;len <= n;++len)
27 {
28 for (int i = 1;i <= n - len + 1;++i)
29 {
30 int j = i + len - 1;
31 e[i][j] = MaxVal;
32 w[i][j] = w[i][j - 1] + p[j] + q[j];
33 //求取最小代价的子树的根
34 for (int k = i;k <= j;++k)
35 {
36 double temp = e[i][k - 1] + e[k + 1][j] + w[i][j];
37 if (temp < e[i][j])
38 {
39 e[i][j] = temp;
40 root[i][j] = k;
41 }
42 }
43 }
44 }
45 }
46
47 //输出最优二叉查找树所有子树的根
48 void printRoot()
49 {
50 cout << "各子树的根:" << endl;
51 for (int i = 1;i <= n;++i)
52 {
53 for (int j = 1;j <= n;++j)
54 {
55 cout << root[i][j] << " ";
56 }
57 cout << endl;
58 }
59 cout << endl;
60 }
61
62 //打印最优二叉查找树的结构
63 //打印出[i,j]子树,它是根r的左子树和右子树
64 void printOptimalBST(int i,int j,int r)
65 {
66 int rootChild = root[i][j];//子树根节点
67 if (rootChild == root[1][n])
68 {
69 //输出整棵树的根
70 cout << "k" << rootChild << "是根" << endl;
71 printOptimalBST(i,rootChild - 1,rootChild);
72 printOptimalBST(rootChild + 1,j,rootChild);
73 return;
74 }
75
76 if (j < i - 1)
77 {
78 return;
79 }
80 else if (j == i - 1)//遇到虚拟键
81 {
82 if (j < r)
83 {
84 cout << "d" << j << "是" << "k" << r << "的左孩子" << endl;
85 }
86 else
87 cout << "d" << j << "是" << "k" << r << "的右孩子" << endl;
88 return;
89 }
90 else//遇到内部结点
91 {
92 if (rootChild < r)
93 {
94 cout << "k" << rootChild << "是" << "k" << r << "的左孩子" << endl;
95 }
96 else
97 cout << "k" << rootChild << "是" << "k" << r << "的右孩子" << endl;
98 }
99
100 printOptimalBST(i,rootChild - 1,rootChild);
101 printOptimalBST(rootChild + 1,j,rootChild);
102 }
103
104 int main()
105 {
106 optimalBST(p,q,n);
107 printRoot();
108 cout << "最优二叉树结构:" << endl;
109 printOptimalBST(1,n,-1);
110 }
DP实现最优二叉搜索树并打印出树结构
参考自
风沙迷了眼
智能推荐
数字频率计的功能及工作原理-程序员宅基地
文章浏览阅读2.4w次,点赞8次,收藏82次。2.1数字频率计功能概述 数字频率计数器的基本功能是测量一个频率稳定度高的频率源的频率。通常情况下计算每秒内待测信号的脉冲个数,此时我们称闸门时间为1秒。闸门时间也可以大于或小于一秒。闸门时间越长,得到的频率值就越准确,但闸门时间越长则没测一次频率的间隔就越长。闸门时间越短,测的频率值刷新就越快,但测得的频率精度就受影响。本数字频率计是用数字显示被测信号频率的仪器,被测信号可以是正弦波,方波或其它周期性变化的信号。2.2 基本工作原理及设计思路根据频率计设计的设计要求,我们可将整个电路系统划分._数字频率计
SparkSQL的Shuffle分区设定及异常数据处理API(去重、缺失值处理)_spark dropduplicates 不同分区怎么解决-程序员宅基地
文章浏览阅读441次。在Spark SQL中,当Job中产生Shuffle时,默认的分区数(spark.sql.shuffle.partions)为200,在实际项目中要合理的设置。在允许spark程序时,查看WEB UI监控页面发现,某个Stage中有200个Task任务,也就是说RDD有200分区Partion。功能:如果数据中包含null通过dropna来进行判断,符合条件就删除这一行数据。功能:对DF的数据进行去重,如果重复数据有多条,取第一条。功能:根据参数的规则,来进行null的替换。_spark dropduplicates 不同分区怎么解决
序列模型(RNN-GRU-LSTM-BRNN-Deep RNN)_brnn 向量 序列-程序员宅基地
文章浏览阅读5.4k次,点赞2次,收藏16次。LSTM原理,应用。从循环神经网络(Recurrent Neural Network,RNN)可以通过许多不同的方式建立,但就像几乎所有函数都可以被认为是前馈网络,基本上任何涉及循环的函数可以被认为是一个循环神经网络。它的基本结构以及其展开的理解如下图所示: 同一网络被视为展开的计算图,其中每个节点现在与一个特定的时间实例相关联................_brnn 向量 序列
什么是深度学习,深度学习和机器学习有什么关系?_深度学习,是机器学习的一种特定技术,称其为深度,是因为他有()结构。-程序员宅基地
文章浏览阅读3.2k次。深度学习的概念源于人工神经网络的研究。含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。晦涩难懂的概念,略微有些难以理解,但是在其高冷的背后,却有深远的应用场景和未来。深度学习是实现机器学习的一种方式或一条路径。其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据。比如其按特定的物理距离连接;..._深度学习,是机器学习的一种特定技术,称其为深度,是因为他有()结构。
bootstrap tab切换后,刷新 页面 回到被选中的tab页签_bootstrap刷新页面-程序员宅基地
文章浏览阅读686次。描述:当使用bootstrap 的tab 进行页面切换后,一刷新页面,又回到了第一个初始页,从而又得重新切换,实现目标:例如当前切换到第三个页面后,刷新页面自动定位到第三个tab页面中。_bootstrap刷新页面
uniapp视频播放器(h5+app)
这是关于一篇在uniapp使用video视频播放器,支持自定义播放器样式,支持手势操作,选集、倍数和清晰度切换,支持SRT字幕格式。
随便推点
别光看世界杯 7月还有一场音视频技术盛宴等着你-程序员宅基地
文章浏览阅读226次。在全世界球迷的瞩目下,2018世界杯在上周激情上演,相信接下来的一个月时间里无数球迷又将守在电视前为自己喜欢的球队摇旗呐喊。当然,在移动互联网发达的今天,即使不在电视前,..._移动咪咕 张云天
PyQt5 —— 控件_pyqt5上传控件-程序员宅基地
文章浏览阅读257次。由于最近在学习pyqt5的相关知识,在网上找了几篇教程看,于是就写了这篇学习笔记。本文只是一些案例的代码以及演示,详细的讲解请看原文。原文链接:https://zetcode.com/gui/pyqt5/中文翻译:http://www.360doc.com/content/19/1022/14/12906439_868371487.shtml文章目录1、QCheckBox2、切换按钮3、滑块4、进度条5、日历6、图片7、行编辑8、QSplitter9、下拉选框1、QCheckBoxQCheck._pyqt5上传控件
全国首届“公安实战声纹和语音应用技术研讨会”成功举办_马鲁朋 菏泽-程序员宅基地
文章浏览阅读1.2k次。11月24日-25日,由中国人民公安大学网络空间安全与法治协同创新中心主办、厦门快商通科技股份有限公司承办的全国首届“公安实战声纹和语音应用技术研讨会”在厦门成功召开。会上,与会嘉宾联合宣布成立“公安实战声纹语音案件技术交流联盟”,共同搭建高质量、高水平的系列化交流平台,持续为智慧警务建设注入新动能。厦门市公安局刑事侦查支队技术处处长任松、中国人民公安大学网络空间安全与法治协同创新中心秘书长..._马鲁朋 菏泽
MATLAB中通讯常用的fread和fscanf的使用心得_matlabfread和fscanf区别-程序员宅基地
文章浏览阅读5.8k次,点赞2次,收藏11次。相信大家都都时不时的会遇到有关MATLAB中的串口或者网口的通讯,其中都会涉及到fread或者fscanf 的使用,接下,作者将首先参考matlab给出的对fread和fscanf的文档,并且做出相关的理解。1、freadstep 1 文档内容fileID = fopen('nine.bin','w');fwrite(fileID,[1:9],'uint16'); %其中unit16,是指传入的..._matlabfread和fscanf区别
逆向_base64_rc4_----笔记_mdawmdawmdawmdawmdawmdawmdawmdawmdawmdawmdawmdawmd-程序员宅基地
文章浏览阅读1k次。新人…学校比赛,没什么经验,上去见见世面某公司的月赛题 资源就不放了,只是当笔记Ida打开 有点小陷阱 巧妙的堆栈运用导致载入ida分析不了 得不到函数的边界比较幸运win32的程序od打开走一遍流程感受下00AD12E7 . 52 push edx00AD12E8 . 68 C821AD00 push 5ba358a4.00AD21C8 ..._mdawmdawmdawmdawmdawmdawmdawmdawmdawmdawmdawmdawmdawmdawmdawmdawmdawmdawmdaw
致 Tapdata 开源贡献者:聊聊 2022 年的进展和新一年的共建计划-程序员宅基地
文章浏览阅读781次。在内、外部开发者的合力之下,过去一年 Tapdata 新增数据源近20个,实现了60+数据源的接入能力。一个人可以走得很快,一群人可以走得更远,2023年期待与您共创更受欢迎的开源项目。_tapdata