NoSQL详细介绍-程序员宅基地
NoSQL入门概述
NoSQL的概念
随着web2.0的快速发展,非关系型、分布式数据存储得到了快速的发展,它们不保证关系数据的ACID特性(原子性、一致性、隔离性、持久性,一个支持事务的数据库,必需要具有这四种特性,否则在事务过程当中无法保证数据的正确性)。NoSQL概念在2009年被提了出来。NoSQL最常见的解释是“non-relational”,“Not Only SQL”也被很多人接受(“NoSQL”一词最早于1998年被用于一个轻量级的关系数据库的名字)。NoSQL被我们用得最多的当数key-value存储,当然还有其他的文档型的、列存储、图型数据库、xml数据库等。
为什么要使用NoSQL数据库
1.对数据库高并发读写的需求
web2.0网站要根据用户个性化信息来实时生成动态页面和提供动态信息,所以基本上无法使用动态页面静态化技术,因此数据库并发负载非常高,往往要达到每秒上万次读写请求。关系数据库应付上万次SQL查询还勉强顶得住,但是应付上万次SQL写数据请求,硬盘IO就已经无法承受了。
2.对海量数据的高效率存储和访问的需求
类似Facebook,twitter,Friendfeed这样的SNS网站,每天用户产生海量的用户动态,以Friendfeed为例,一个月就达到了2.5亿条用户动态,对于关系数据库来说,在一张2.5亿条记录的表里面进行SQL查询,效率是极其低下乃至不可忍受的。再例如大型web网站的用户登录系统,例如腾讯,盛大,动辄数以亿计的帐号,关系数据库也很难应付。
3.对数据库的高可扩展性和高可用性的需求
在基于web的架构当中,数据库是最难进行横向扩展的,当一个应用系统的用户量和访问量与日俱增的时候,你的数据库却没有办法像web server和app server那样简单的通过添加更多的硬件和服务节点来扩展性能和负载能力。对于很多需要提供24小时不间断服务的网站来说,对数据库系统进行升级和扩展是非常痛苦的事情,往往需要停机维护和数据迁移。
NoSQL可以干什么
1.易扩展
NoSQL数据库种类繁多,但是一个共同的特定都是去掉关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展,也在无形之间,在架构层面上带来了可扩展的能力。
2.大数据量高性能
NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。这得益于它的无关系性,数据库的结构简单。一般MySQL使用Query Cache,每次表的更新Cache就失效,是一种大粒度的Cache,在针对web2.0的交互频繁的应用,Cache性能不高。而NoSQL的Cache是记录级的,是一种细粒度的Cache,所以NoSQL在这个层面上来说就要性能高很多了。
3.多样灵活的数据模型
NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个噩梦。
4.传统RDBMS VS NOSQL
RDBMS
- 高度组织化结构化数据
- 结构化查询语言(SQL)
- 数据和关系都存储在单独的表中。
- 数据操纵语言,数据定义语言
- 严格的一致性
- 基础事务
NoSQL
- 代表着不仅仅是SQL
- 没有声明性查询语言
- 没有预定义的模式
- 键 - 值对存储,列存储,文档存储,图形数据库
- 最终一致性,而非ACID属性
- 非结构化和不可预知的数据
- CAP定理
- 高性能,高可用性和可伸缩性
NoSQL数据模型简介
传统数据库模型和NoSQL数据模型对比
以一个电商客户、订单、订购、地址模型来对比下关系型数据库和非关系型数据库
1.传统模型(ER图)
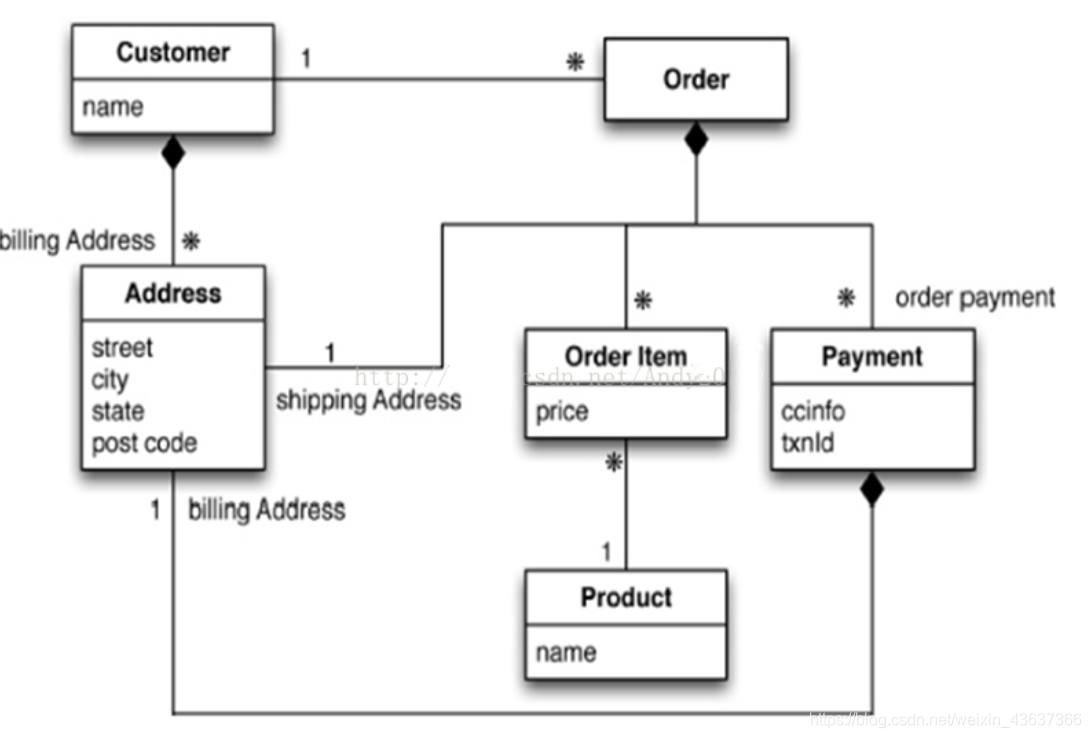
2.NoSQL(聚合模型例如Bson)
{
"customer":{
"id":1136,
"name":"Z3",
"billingAddress":[{"city":"beijing"}],
"orders":[
{
"id":17,
"customerId":1136,
"orderItems":[{"productId":27,"price":77.5,"productName":"thinking in java"}],
"shippingAddress":[{"city":"beijing"}]
"orderPayment":[{"ccinfo":"111-222-333","txnid":"asdfadcd334","billingAddress":{"city":"beijing"}}],
}
]
}
}
3.总结
- 传统关系模型:元组(行)是受限的结构,只能包含一系列的值,不能嵌套另外的元组和列表。所有操作都以元组为目标,而且其返回值必须是元组。适用于多种查询条件获取数据的需求。
- 聚合模型:是NoSQL操作数据时所用的单元,其结构比元组复杂,这种结构可以存放列表或嵌套其他记录。聚合数据模型的特点就是把经常访问的数据放在一起(聚合在一块),这样带来的好处很明显,对于某个查询请求,能够在与数据库一次交互中将所有数据都取出来。
四种聚合模型
1.KV键值
特点:Key-Value模式。在这种数据结构中,数据表中的每一个实际行只具有行键(Key)和数值(Value)两个基本内容。值可以看做一个单独的存储区域,可能是任何类型,甚至是数组。
2.bson
特点:与键值存储模式有相似性,但其值一般是半结构化内容,需要通过某种半结构化标记语言进行描述。和键值模式相比,文档式存储模式强调可以通过关键词查找查询文档内部的结构,而非只通过键来进行检索。文档允许嵌套,因此可以将传统关系型数据库中需要Join查询的字段整合为一个文档,这种做法理论上会增加存储开销,但是会提高查询效率。在分布式系统中,Join查询的开销较大,文档式嵌套存储的优势更加明显。
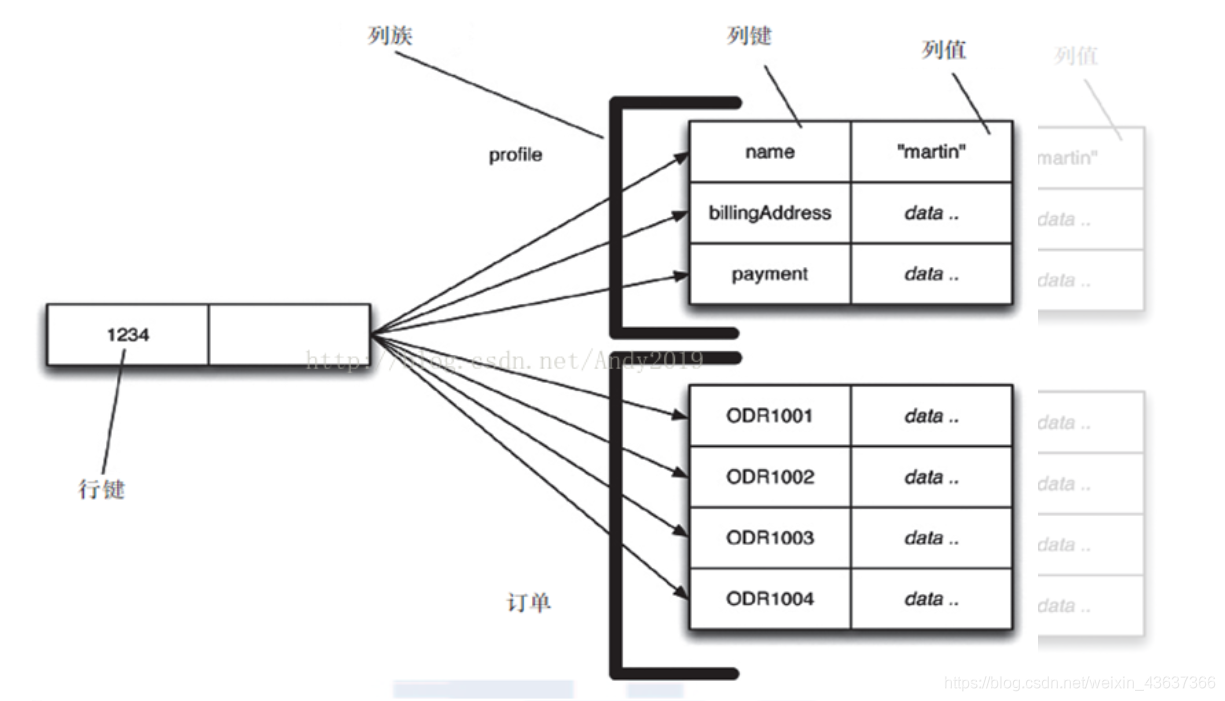
3.列族
特点:可以称为面向列的存储模式,以区别于关系型数据中面向行的存储模式,这种存储模式主要用在OLAP,数据仓库等场合。面向行的存储模式中,数据以行(或记录)的方式整合到一起,数据行中的每一个字段都在一起存储。但在面向列的存储模式中,属于不同列或列族的数据在不同的文件中,这些文件能分布在不同的位置上,甚至是不同的节点上。(简单结构如下图)
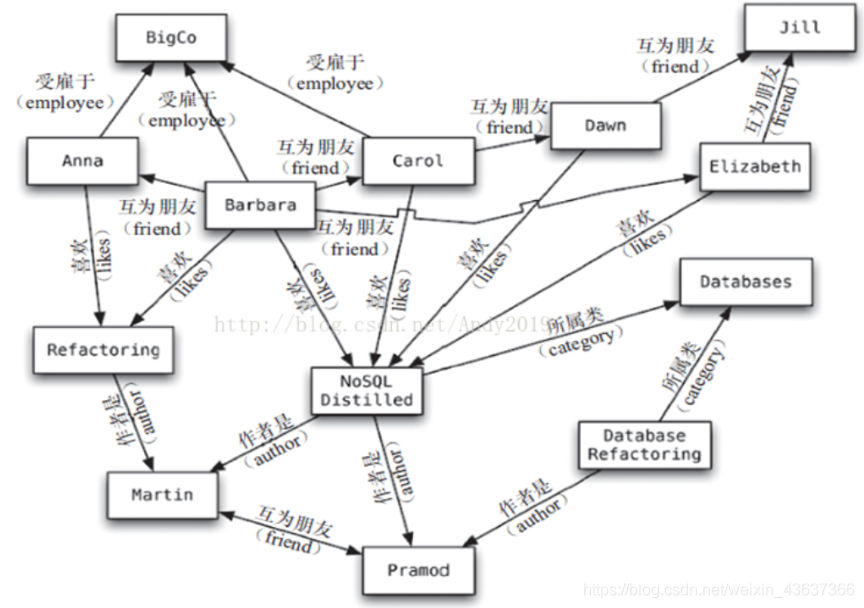
4.图形
特点:图存储模式来源于图论中的拓扑学。图存储模式是一种专门存储 节点和边以及节点之间的连线关系的拓扑存储方法。节点和边都存在描述参数,边是矢量,即有方向的,可能是单向或双向的。拓扑图中般需要记录如下内容: 节点(或称顶点)的ID和属性,节点之间的连线(或称边、关系),边的ID、方向和属性(例如转移函数等)。常见的点线拓扑关系有网页之间的链接关系,社交网络中的关注与转发关系等。如下图为某社交网络关系图模型。
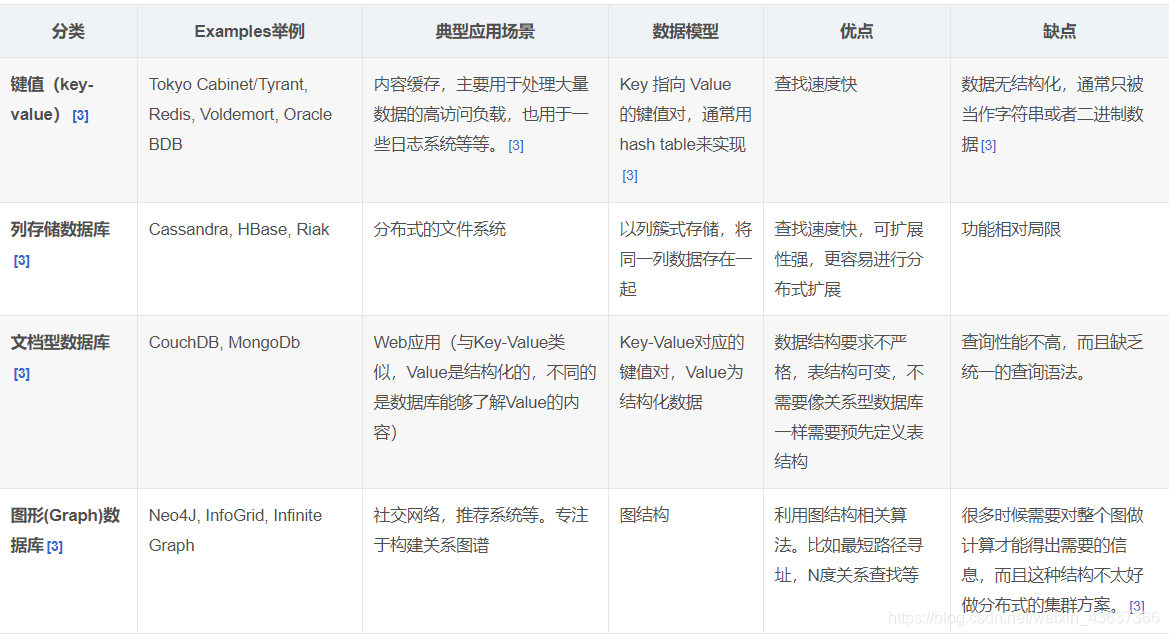
NoSQL数据库四大分类及区别
四大分类
1.KV存储数据库
- 典型代表
BerkeleyDB、MemcacheDB、Redis - 特征
可以通过key快速查询到value。一般来说,存储不需要考虑value的格式。
2.文档存储数据库
- 典型代表
MongoDB、CouchDB - 特征
文档数据库一般用类似json的格式存储,存储的内容是文档型的。这样也就有机会对某些字段建立索引,实现关系数据库的某些功能。
3.列存储数据库
- 典型代表
Hbase、Cassandra、Hypertable - 特征
按列存储数据,最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一列或者某几列的查询有着极大的IO优势。
4.图关系数据库
- 典型代表
Neo4J、FlockDB - 特征
图形关系的最佳存储,使用传统关系数据库来解决的话性能低下,而且设计及其不方便。
区别
NoSQL数据库中CAP+BASE原理
传统关系型数据库ACID原理
1.原子性(Atomicity)
一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有被执行过一样。
2.一致性(Consistency)
在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作
3.独立性(Isolation)
数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交、读已提交、可重复读和串行化。
4.持久性(Durability)
事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
CAP原理
1.强一致性(Consistency)
在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
2.可用性(Availability)
每次请求都能获取到非错的响应——但是不保证获取的数据为最新数据。在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。
3.分区容错性(Partition tolerance)
分区容错性其实是约束了分布式系统需要具有如下的特性:分布式在遇到任何网络分区故障的时候,仍然需要保证对外提供满足一致性和可用性的服务,除非整个网络均已瘫痪。也就是说,它容忍错误的出现,在发生错误的情况下可以继续进行操作。
CAP的三进二原则
1.CAP理论的核心
一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三大类
- CA:单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
- CP:满足一致性,分区容忍性的系统,通常性能不是特别高。
- AP:满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
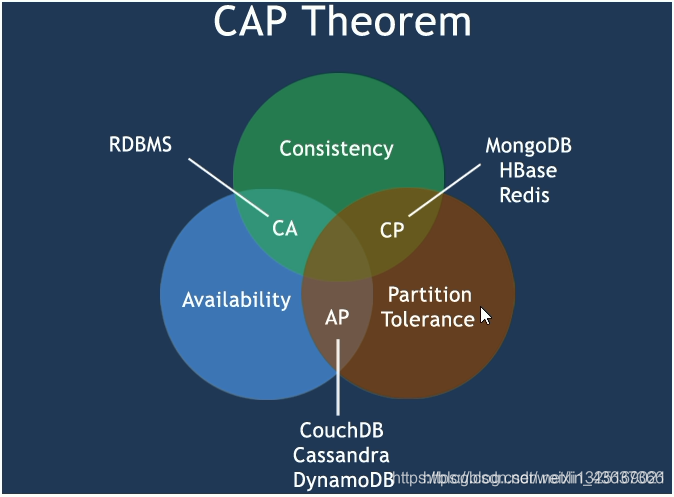
2.如何选择
CAP理论就是说在分布式存储系统中,最多只能实现上面的两点。而由于当前的网络硬件肯定会出现延迟丢包等问题,所以分区容忍性是我们必须需要实现的。一致性和可用性的抉择可以参考思路
- 数据库事务一致性需求
很多web实时系统并不要求雅阁的数据库事务,对读一致性的要求很低,有些场合对写一致性要求并不高 。允许实现最终一致性。 - 数据库的写实时性和读实时性的需求
对系统数据库来说,插入一条数据之后立刻查询,是肯定可以独处这条数据。但是对于大多数web应用来说,并不要求这么高的实时性,当我们发布一条消息后,过上几秒或是几十秒后被接受看到都是被允许的(如发微博/直播等,都是具有延迟的) - 对复杂的SQL查询,特别是多表关联查询的需求
任何大数据量的web系统,都非常忌讳多个大表的关联查询,以及复杂的数据分析类型的报表查询。我们把这些数据进行整合以k-v键值对的形式放到缓存里面,避免了数据库查询,这样子记得到我们所要的内容,又不给数据库增加负担,这样增强了数据的高可用。
BASE原理
BASE就是为了解决关系数据库强一致性引起的问题而引起的可用性降低而提出的解决方案。他的思想就是通过让系统在某一时刻牺牲数据一致性的要求来换取系统整体的伸缩性和性能上的改观。(也就是说牺牲C 来实现AP,以BASE的理论来达成最终一致性)。
1.基本可用(Basically Available)
这里是指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心功能或者当前最重要功能可用。对于用户来说,他们当前最关注的功能或者最常用的功能的可用性将会获得保证,但是其他功能会被削弱。
2.软状态(Soft state)
允许系统数据存在中间状态,但不会影响到系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步时存在延时。
3.最终一致(Eventually consistent)
要求系统数据副本最终能够一致,而不需要实时保证数据副本一致。最终一致性是弱一致性的一种特殊情况。最终一致性有5个变种:因果一致性,读己之所写(例如发微博的时候,自己可以马上看到,但是粉丝要过几秒钟),会话一致性,单调读一致性,单调写一致性。
本篇博客就讲解到这里,如果发现任何问题或产生疑问请直接指出
参考教程:[尚硅谷]
智能推荐
计算机就业方向-程序员宅基地
文章浏览阅读6.8k次,点赞5次,收藏12次。希望看到这篇文章的学计算机、软件的同学可以互相转载,让大家都知道我们以后的道路是怎样的。有了方向,干什么都有动力,不是吗?(有点长,希望大家先分享,以后慢慢看,有用没用,我说了不算,你看看就知道了!)计算机专业就业方向一、 关于企业计算方向企业计算(Enterprise Computing)是稍时髦较好听的名词,主要是 指企业信息系统,如ERP软件(企业资源规划)、CRM软件(客户关系_计算机就业
基于Java在线电影票购买系统设计实现(源码+lw+部署文档+讲解等)-程序员宅基地
文章浏览阅读4.1k次,点赞2次,收藏4次。社会和科技的不断进步带来更便利的生活,计算机技术也越来越平民化。二十一世纪是数据时代,各种信息经过统计分析都可以得到想要的结果,所以也可以更好的为人们工作、生活服务。电影是生活娱乐的一部分,特别对喜欢看电影的用户来说是非常重要的事情。把计算机技术和影院售票相结合可以更符合现代、用户的要求,实现更为方便的购买电影票的方式。本基于Java Web的在线电影票购买系统采用Java语言和Vue技术,框架采用SSM,搭配MySQL数据库,运行在Idea里。
集合的addAll方法--list.addAll(null)会报错--java.lang.NullPointerException-程序员宅基地
文章浏览阅读1.8k次。Exception in thread "main" java.lang.NullPointerException at java.util.ArrayList.addAll(ArrayList.java:559) at com.iflytek.epdcloud.recruit.utils.quartz.Acool.main(Acool.java:16)import java.u..._addall(null)
java获取当天0点到24点的时间戳,获得当前分钟开始结束时间戳_java 获取某分钟的起止时间戳-程序员宅基地
文章浏览阅读4.5k次。public static void main(String[] args) { Calendar todayStart = Calendar.getInstance(); todayStart.set(Calendar.HOUR_OF_DAY, 0); todayStart.set(Calendar.MINUTE, 0); toda..._java 获取某分钟的起止时间戳
北京内推 | 京东AI研究院计算机视觉实验室招聘三维视觉算法研究型实习生-程序员宅基地
文章浏览阅读1.1k次。合适的工作难找?最新的招聘信息也不知道?AI 求职为大家精选人工智能领域最新鲜的招聘信息,助你先人一步投递,快人一步入职!京东 AI 研究院京东 AI 研究院(https://air.jd..._京东计算机视觉实验室
Ubuntu18.04安装配置Qt5.15_ubuntu安装qt5.15-程序员宅基地
文章浏览阅读2.1k次。Ubuntu18.04安装配置Qt5.15 Ubuntu18.04安装配置Qt5.15 Qt选择下载Qt安装Qt5.15.0配置后记 Qt选择 在官方的声明中,Qt5.15是Qt5.x的最后一个LTS版本,增加了即将在2020年底推出的Qt6的部分新特性,为了之后的新_ubuntu安装qt5.15
随便推点
探索 Toolbox-Weex:一款强大的 Weex 工具集合-程序员宅基地
文章浏览阅读241次,点赞3次,收藏6次。探索 Toolbox-Weex:一款强大的 Weex 工具集合项目地址:https://gitcode.com/hugojing/toolbox-weexToolbox-Weex 是一个开源项目,专门为 Weex 开发者提供了一整套便捷的工具和组件,旨在提升 Weex 应用开发的效率和质量。如果你是 Weex 的爱好者或正在寻找优化你的移动应用开发流程的方法,那么 Toolbox-Weex 绝..._wsatoolbox
卷积神经网络模型可视化生成热力图_卷积热力图-程序员宅基地
文章浏览阅读2.3k次。使用Grad-CAM++[51]方法对训练好的卷积神经网络模型进行可视化操作生成热力图以查看响应区域。可视化结果如图3.8所示。其中baseline和 ATN可视化需要的权重来自于分类结果对最后一层卷积层提取的特征进行求导。图3.8中共有4组图像,每组图像从左往右依次为原图,根据baseline权重生成的热力图和根据本章提出的ATN网络权重生成的热力图。热力图的红色越深,则表示该部分的权重越高。从生成的热力图可以看到,baseline 生成的热力图中,虽然在人体区域都有响应,但是背景噪声部分的响应权重也_卷积热力图
网络安全实验---防火墙实验-程序员宅基地
文章浏览阅读2w次,点赞13次,收藏82次。文章目录一、实验目的:二、实验环境:三、实验内容:1. 安装天网防火墙2. 使用天网防火墙进行实验3.在上端的菜单栏最左边点击应用程序规则,点击下方需要修改应用的选项可以对其进行流量控制4.调节ip规则配置,将“允许自己ping探测其他机器”改为禁止,查看能否再次收到reply5.添加一条禁止邻居同学主机的FTP连接规则四、心得体会:五.软件共享一、实验目的:通过实验深入理解防火墙的功能和工作原理熟悉天网防火墙个人版的配置和使用二、实验环境:一台xp虚拟机和一台windows10虚拟机在xp上安_防火墙实验
vue项目运行报错:94% asset optimization ERROR Failed to compile with 2 errors13:03:01 error in ./src/ba-程序员宅基地
文章浏览阅读6.7k次。使用vue编写的前端项目运行报错:88% hashing 89% module assets processing 90% chunk assets processing 94% asset optimization ERROR Failed to compile with 2 errors13:03:01 error in ./src/base/components/head..._94% asset optimization
适用于 Linux 的 Windows 子系统安装指南 (Windows 10) (微软官方文档)_hyper-v-vmms 虚拟硬盘文件必须是未压缩和未加密的文件,并且不能是稀疏文件。-程序员宅基地
文章浏览阅读2.2k次,点赞2次,收藏3次。官方原文档微软官方教程地址:传送门安装适用于 Linux 的 Windows 子系统必须先启用“适用于 Linux 的 Windows 子系统”可选功能,然后才能在 Windows 上安装 Linux 分发版。以管理员身份打开 PowerShell 并运行:dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart安装所选的 Linux 分发版打开 Micro_hyper-v-vmms 虚拟硬盘文件必须是未压缩和未加密的文件,并且不能是稀疏文件。
rufus 一款好用的linux u盘,光盘刻录工具_rufus可以刻录光盘吗-程序员宅基地
文章浏览阅读2.2k次。rufus 一款好用的linux u盘,光盘刻录工具:下载(点击普通下载中的“立即下载”): http://share.cnop.net/file/1806028-401886318_rufus可以刻录光盘吗