文本分类-程序员宅基地
1. 简述
文本分类的方法属于有监督的学习方法,分类过程包括文本预处理、特征抽取、降维、分类和模型评价。本文首先研究了文本分类的背景,中文分词算法。然后是对各种各样的特征抽取进行研究,包括词项频率-逆文档频率和word2vec,降维方法有主成分分析法和潜在索引分析,最后是对分类算法进行研究,包括朴素贝叶斯的多变量贝努利模型和多项式模型,支持向量机和深度学习方法。深度学习方法包括多层感知机,卷积神经网络和循环神经网络。
2. 背景
目前,人工智能发展迅猛,在多个领域取得了巨大的成就,比如自然语言处理,图像处理,数据挖掘等。文本挖掘是其中的一个研究方向。根据维基百科的定义,文本挖掘也叫文本数据挖掘,或是文本分析,是从文本中获取高质量信息的过程,典型的任务有文本分类、自动问答、情感分析、机器翻译等。文本分类是将数据分成预先定义好的类别,一般流程为:1. 预处理,比如分词,去掉停用词;2. 文本表示及特征选择;3. 分类器构造;4. 分类器根据文本的特征进行分类;5. 分类结果的评价。
由于近年来人工智能的快速发展,文本分类技术已经可以很好的确定一个未知文档的类别,而且准确度也很好。借助文本分类,可以方便进行海量信息处理,节约大量的信息处理费用。广泛应用于过滤信息,组织与管理信息,数字图书馆、垃圾邮件过滤等社会生活的各个领域。
3. 文本分类的过程
文本分类(Text Classification)利用有监督或是无监督的机器学习方法对语料进行训练,获得一个分类模型,这个模型可以对未知类别的文档进行分类,得到预先定义好的一个或多个类别标签,这个标签就是这个文档的类别。

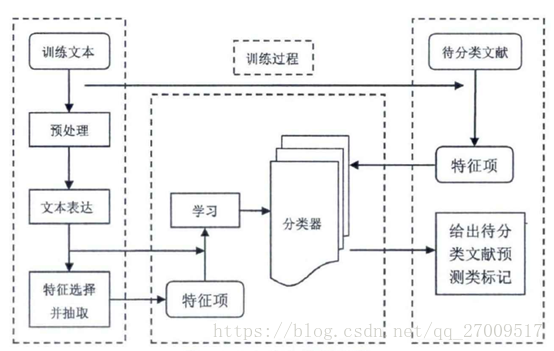
4. 预处理
本文处理的数据是文本,预处理是对文本数据进行处理,大都是非结构化的文本信息。预处理就是去除没用的信息,同时把有用文本信息用数字表示,这样才可以为计算机处理。文本预处理主要包括分词、去除停用词和特殊符号。英文的基本单位是单词,可以根据空格和标点符号进行分词,然后再提取词根和词干。中文的基本单位是字,需要一些算法来进行分词。现在主要的中文分词方法有:
(1)基于字符串匹配的分词方法[2]
该方法是将待分词的字符串从头或尾开始切分出子串,再与存有几乎所有中文词语的词典匹配,若匹配成功,则子串是一个词语。根据匹配位置的起点不同,分为正向最大匹配算法(Forward Maximum Matching method,FMM)、逆向最大匹配算法(Reverse Maximum Matching method,RMM)和双向匹配算法(Bi-direction Matching method,BM)。双向匹配算法利用了前两者的优势,有更好的效果。
(2)基于统计及机器学习的分词方法[3]
主要有隐马尔可夫模型(Hidden Markov Model,HMM)和条件随机场(Conditional Random Field,CRF)。HMM假设任一时刻的状态只依赖前一时刻的状态和任意时刻的观测值只与该时刻的状态值有关。它是关于时序的概率图模型,由一个不可观测的状态随机序列,经过状态转移概率和发射概率生成观测值的过程。如图2.2所示,在分词中,每个字(观测值)都对应一个状态,状态集用B(词开始)、E(词的结束)、M(词的中间)和S(单字成词)表示,转移矩阵(BEMS*BEMS)是状态集里的元素到其他元素的概率值大小,发射矩阵是从状态到观测的概率大小。最后用Viterbi算法获得一句话的最大概率的状态,再根据状态进行分词。
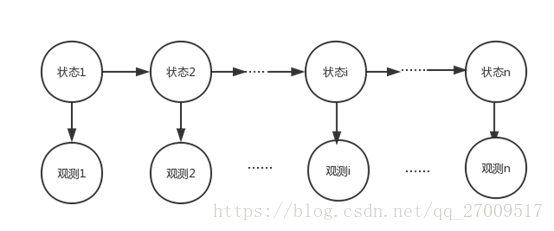
和隐马尔科夫模型一样,条件随机场也是基于学习字的状态来进行状态分析,最后根据状态分词,但条件随机场还利用了上下文的信息,所以准确率高于隐马尔可夫模型。
5. 特征抽取和选择
文档经过分词和去除停用词后,词就表示文本的特征项,所以训练集中的全部特征项构成的向量空间的维度相当高,能够达到几万甚至几十万维,需要选择和抽取重要的特征。
文本经过预处理后,会得到一个一个的词语,而中文的词语的多种多样的,造成维度很高的特征向量,而且每个文档的维度不一定一致,给后面的分类产生影响。所以需要进行特征选择。
目前的特征选择算法有好多,列举以下几种:
(1)词项频率-逆文档频率(Term Frequency-Inverse Document Frequency,TF-IDF)
每个属于文档d 的词项t
的权重用公式2.2计算:
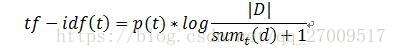
|D| 是文档集D 的文档个数,分母加1防止除数为零。在TF-IDF中词项频率(TF)用逆文档频率(IDF)归一化,这种归一化降低了文档集里词项出现频率大的权重,保证能够区分文档的词项有更大的权重,而这些词项一般有比较低的频率。
(2)互信息(Mutual Information,MI)
互信息测量的是两个变量之间的相关程度,在文本分类中,计算的是特征项t 和类别li
的相关程度,如公式2.3所示:
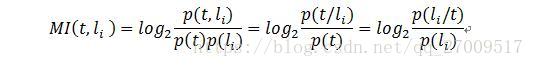
MI的值越大,相关度越高。在进行特征选择时,选择高于某个阈值的k个特征项作为表示这个文档的向量。
(3)CHI统计(CHI-square statistic)
CHI统计计算的是特征项t 和类别
的相关程度,如公式2.4所示:

特征选择与MI一样,他与MI的目的一样,都是计算特征项和类别的相关程度,只是计算公式不一样。
常见的特征提取方法有主成分分析,潜在语义索引,word2vec等。
(1)主成分分析(Principal Component Analysis ,PCA)
主成分分析通过线性变换,通常乘以空间中的一个基,将原始数据变换为一组各维度线性无关的矩阵,用于提取数据的主要特征分量,常用于高维数据的降维。如公式2.5所示:
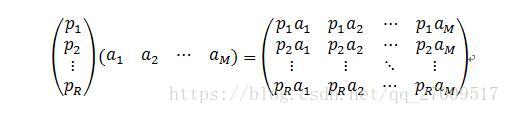

(2)潜在语义分析(Latent Semantic Analysis,LSA)[5]
又称潜在语义索引(Latent Semantic Indexing,LSI),本质上是把高维的词频矩阵进行降维,降维方法是用奇异值分解(Singular Value Decomposition, SVD),假设词-文档矩阵如2.7所示:

(3)word2vec
word2vec的作用是将由one-hot编码获得的高维向量转换为低维的连续值向量,也就是稠密向量,又称分布式表示,可以很好的度量词与词之间的相似性,是一个浅层的神经网络,用的是CBoW模型和skip-gram模型。而奠定word2vec基础的是用神经网络建立统计语言模型的神经网络语言模型[10](Neural Network Language Model, NNLM),整个模型如下图2.3:
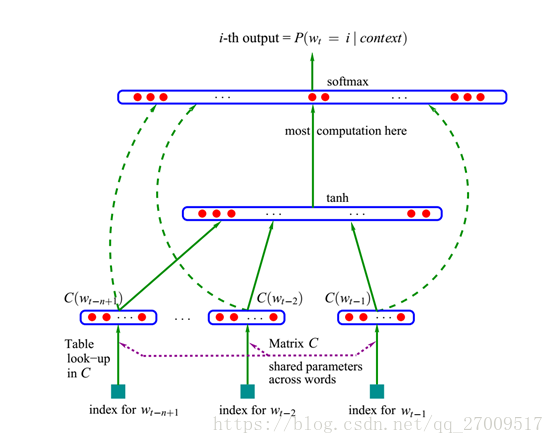
首先是一个线性的嵌入式层,将输入的one-hot词向量通过 D×V 的矩阵 C 映射为 N-1 个词向量, V 是词典的大小, D 是词向量的维度,而 C 矩阵就存储了要学习的词向量。
接下来是一个前向反馈神经网络,由tanh隐藏层和softmax输出层组成,将嵌入层输出的 N-1 个词向量映射为长度为V 的概率分布向量,从而对词典中输入的词Wt 在context下进行预测,公式如下:
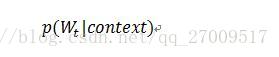
由于NNLM只能处理定长序列,而且训练速度太慢,所以需要改进,移除tanh层,忽略上下文的序列信息,得到的模型称为CBoW[11](Continuous Bag-of-Words Model),作用是将词袋模型的向量乘以嵌入式矩阵,得到连续的嵌入向量,它是在上下文学习以得到词向量的表达。而Skip-gram模型则是对上下文里的词进行采样[11],即从词的上下文获得词向量,如图2.4所示。
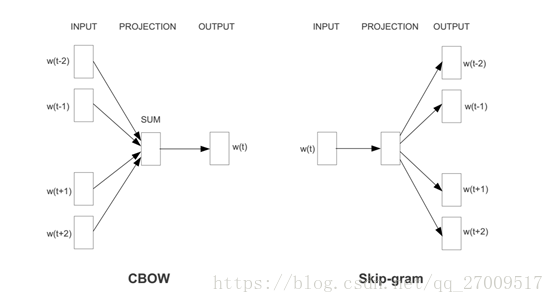
改进后的神经网络仅三层,其中隐藏层的权重即是要训练的词向量。
6. 对语料进行分类后,要对分类结果进行评价
(1)准确率(precision)和召回率(recall)
准确率,是分类结果中的某类别判断正确的文档中有多少是真正的正样本的比例,是针对预测结果而言的,衡量的是分类系统的查准率。计算公式如下:
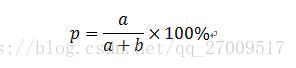
召回率,是原来某个类别的文本的分类结果中有多少被预测为正确的比例,是针对原来样本而言的,衡量的是分类系统的查全率。计算公式如下:
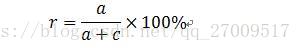
但是,准确率和召回率不总是正相关,有时是负相关,需要F测度来平衡。
(2)F测度(F-measure)
是正确率和召回率的的加权调和平均,公式如下:

当 时,就是F1,即
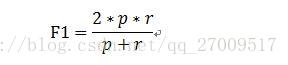
智能推荐
在移动硬盘中安装win10和macos双系统-程序员宅基地
文章浏览阅读1.1k次,点赞22次,收藏23次。本文通过在SSD移动硬盘中安装win10和macos双系统,实现操作系统随身携带小慢哥的原创文章,欢迎转载目录 目标 准备工作 Step1. 清空分区,转换为GPT Step2. 安装win10 Step3. 压缩win10分区容量 Step4. 创建2个分区 Step5. 将bootcamp驱动放置到exFAT分区中 Step6. 将macos分区..._mac移动硬盘装双机系统
TransmittableThreadLocal解决线程池本地变量问题,原来我一直理解错了-程序员宅基地
文章浏览阅读14次。theme: cyanosishighlight: a11y-dark前言自从上次TransmittableThreadLocal框架作者评论我之后,我重新去看了下源码,终于在这个周天,我才把TransmittableThreadLocal解决线程池变量丢失的问题搞明白,而且发现我之前的认识有问题,久久孩子我之前是觉得,InheritableThreadLocal解决父子线...
Exchange 2016部署实施案例篇-03.Exchange部署篇(上)-程序员宅基地
文章浏览阅读366次。 距离上一篇《Exchange 2016部署实施案例篇-02.活动目录部署篇》博文更新已经过去快一周了,最近一直在忙项目上的事情和软考,整的真心有点身心俱疲啊,最近看了下上一篇博文不知道为什么访问量一直上不去,真心有点心寒啊。希望大家能多多提出宝贵意见,看看如何能让访问量上去。 废话就不多说了,开始今天的话题,Exchange的部署篇,我原定计划是把部署篇分上、下2个篇幅来写的,但最近发现好..._解决exchange2016部署先决条件
[译]使用MVI打造响应式APP(四):独立性UI组件-程序员宅基地
文章浏览阅读130次。原文:REACTIVE APPS WITH MODEL-VIEW-INTENT - PART4 - INDEPENDENT UI COMPONENTS作者:Hannes Dorfmann译者:却把清梅嗅这篇博客中,我们将针对如何 如何构建独立组件 进行探讨,我将阐述为什么在我看来 父子关系会导致坏味道的代码,以及为何这种关系是没有意义的。有这样一个问题时不时涌现在我的脑海中—— MVI...
tensorflow经过卷积及池化层后特征图的大小计算_池化层后特征图尺寸-程序员宅基地
文章浏览阅读662次。https://blog.csdn.net/qq_32466233/article/details/81075288_池化层后特征图尺寸
使用vue-echarts异步数据加载,不能重新渲染页面问题。_vue echart初始化渲染过后无法重新渲染-程序员宅基地
文章浏览阅读3.3k次。一、问题说明我是用的是官方示例中的这个饼状图。结果在应用到项目中后发现利用axios请求到的数据无法渲染到页面中去。并且其中value值已经改变。二、解决办法用$set改变value的值,并且重新绘制一遍表格。$set是全局 Vue.set 的别名。$set用法:向响应式对象中添加一个属性,并确保这个新属性同样是响应式的,且触发视图更新。它必须用于向响应式对象上添加新属性,因为..._vue echart初始化渲染过后无法重新渲染
随便推点
Dev-C++ “to_string is not a member of std” error- 已解决_devc++ [error] 'to_string' is not a member of 'std-程序员宅基地
文章浏览阅读3.7k次。今天在用Dev-C++ 的时候遇到一个错误“to_string is not a member of std” error解决方法:设置编译语言为ISO C++11 在菜单栏的Tool -> Compiler Option_devc++ [error] 'to_string' is not a member of 'std
python的10款最好的IDE_pydea兼容的-程序员宅基地
文章浏览阅读1.1k次。Python 非常易学,强大的编程语言。Python 包括高效高级的数据结构,提供简单且高效的面向对象编程。Python 的学习过程少不了 IDE 或者代码编辑器,或者集成的开发编辑器(IDE)。这些 Python 开发工具帮助开发者加快使用 Python 开发的速度,提高效率。高效的代码编辑器或者 IDE 应该会提供插件,工具等能帮助开发者高效开发的特性。这篇文章收集了一些对开发者非常有_pydea兼容的
python translate函数_Python:内置函数makestrans()、translate()-程序员宅基地
文章浏览阅读287次。一、makestrans()格式: str.maketrans(intab,outtab);功能:用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。注:两个字符串的长度必须相同,为一一对应的关系。注:Python3.6中已经没有string.maketrans()了,取而代之的是内建函数:bytearray...._python maketrance
Set集合详解-程序员宅基地
文章浏览阅读5.7k次,点赞9次,收藏14次。set集合的简介,它的特点和遍历方式。介绍了HashSet重复元素存储底层原理,LinkedHashSet,TreeSet排序方法,SortedSet获取集合值的方法_set集合
详解智慧城市排水管理系统整体方案_污水处理智慧管理系统案列-程序员宅基地
文章浏览阅读3.6k次,点赞3次,收藏29次。随着城市规模的不断扩大和现代化程度的日益提高,城市排水管网越来越复杂,一些城市相继发生大雨内涝、管线泄漏爆炸、路面塌陷等事件,严重影响了人民群众生命财产安全和城市运行秩序。因此,摸清排水管网设施资产家底、建立排水管网地理信息系统,用现代化的技术手段对排水系统进行科学管理显得迫在眉睫。以时空信息为基础,充分利用感知监测网、物联网、云计算、移动互联网、工业控制和水力模型等新一代信息技术,全方位感..._污水处理智慧管理系统案列
详解NTFS文件系统_ntfs文件系统中,磁盘上的所有数据包括源文件都是以什么的形式存储-程序员宅基地
文章浏览阅读5.7k次,点赞4次,收藏13次。上篇在详解FAT32文件系统中介绍了FAT32文件系统存储数据的原理,这篇就来介绍下NTFS文件系统。NTFS、用过Windows系统的人都知道,它是一个很强大的文件系统,支持的功能很多,存储的原理也很复杂。目前绝大多数Windows用户都是使用NTFS文件系统,它主要以安全性和稳定性而闻名,下面是它的一些主要特点。安全性高:NTFS支持基于文件或目录的ACL,并且支持加密文件系统(E_ntfs文件系统中,磁盘上的所有数据包括源文件都是以什么的形式存储