【论文精读】门控图神经网络GGNN及SRGNN-程序员宅基地
GGNN

SRGNN是GGNN在推荐系统上的应用,核心网络几乎没有改变。GGNN的核心模型其实非常简单,在计算上和GRU基本没有区别。但为了更好的理解 a v a_v av是如何构造出来的,我们还得从最基本的思想讲起。
信息传播
绝大多数GNN的思想在于消息传播(Message Passing)或者说信念传播(Belief Propagation)。很自然的,我们知道一个节点的信息可以根据其邻居节点信息进行更新。
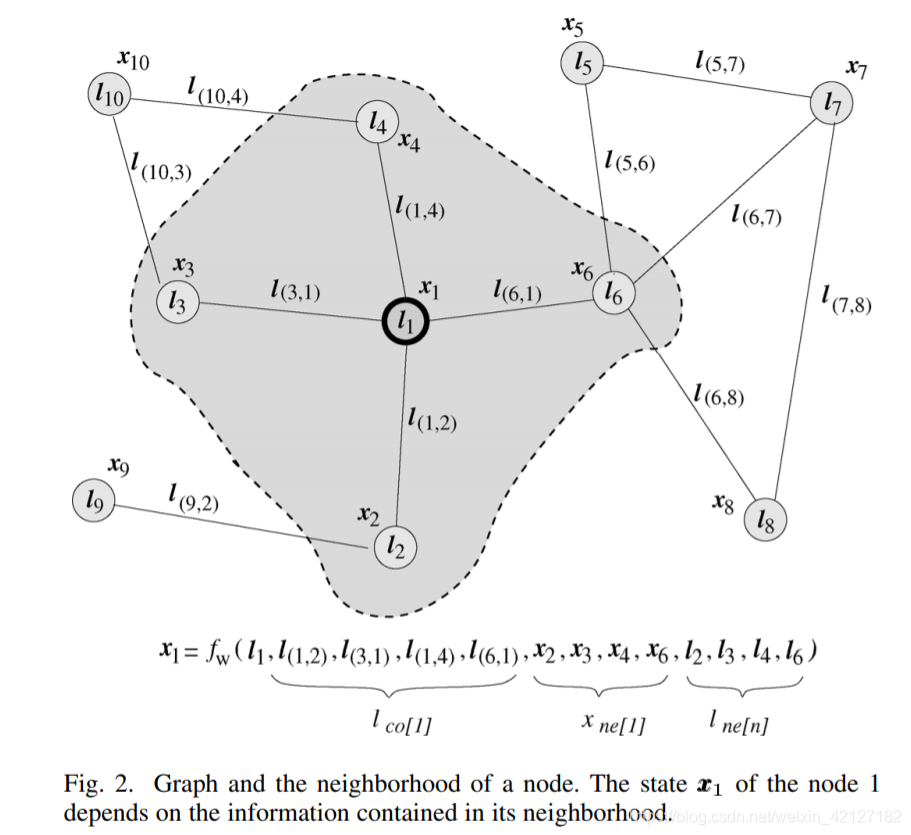
初代GNN
2009年最早的GNN论文1将这个过程抽象为
x n = f w ( l n , l c o [ n ] , x n e [ n ] , l n e [ n ] ) \boldsymbol{x}_{n} =f_{\boldsymbol{w}}\left(\boldsymbol{l}_{n}, \boldsymbol{l}_{\mathrm{co}[n]}, \boldsymbol{x}_{\mathrm{ne}[n]}, \boldsymbol{l}_{\mathrm{ne}[n]}\right) xn=fw(ln,lco[n],xne[n],lne[n])
其中,
x \boldsymbol{x} x为状态向量state,GGNN的记号 h \boldsymbol{h} h更符合现在的习惯
l \boldsymbol{l} l为特征向量feature,或者说embedding
c o [ n ] co[n] co[n]为与节点n相连的边,
n e [ n ] ne[n] ne[n]为节点n邻居节点.
以商品为例,商品的类别、价格、品质等具体属性可以组合为节点的特征向量,用户对商品的点击次数、停留时间等可以组合为边的特征向量。当然,hidden state x n e [ n ] \boldsymbol{x}_{\mathrm{ne}[n]} xne[n]本身也包含了embedding l n e [ n ] \boldsymbol{l}_{\mathrm{ne}[n]} lne[n]的信息,只保留一个,直接把 l \boldsymbol{l} l 作为初始的embeding也是可以的。
根据巴拿赫不动点定理,我们利用 f w f_{\boldsymbol{w}} fw不断压缩,得到稳定状态的hidden state,然后再通过 g w g_{\boldsymbol{w}} gw输出.
o n = g w ( x n , l n ) \boldsymbol{o}_{n} =g_{\boldsymbol{w}}\left(\boldsymbol{x}_{n}, \boldsymbol{l}_{n}\right) on=gw(xn,ln)
GNN将这两个映射函数设计为两个不同的前馈神经网络,
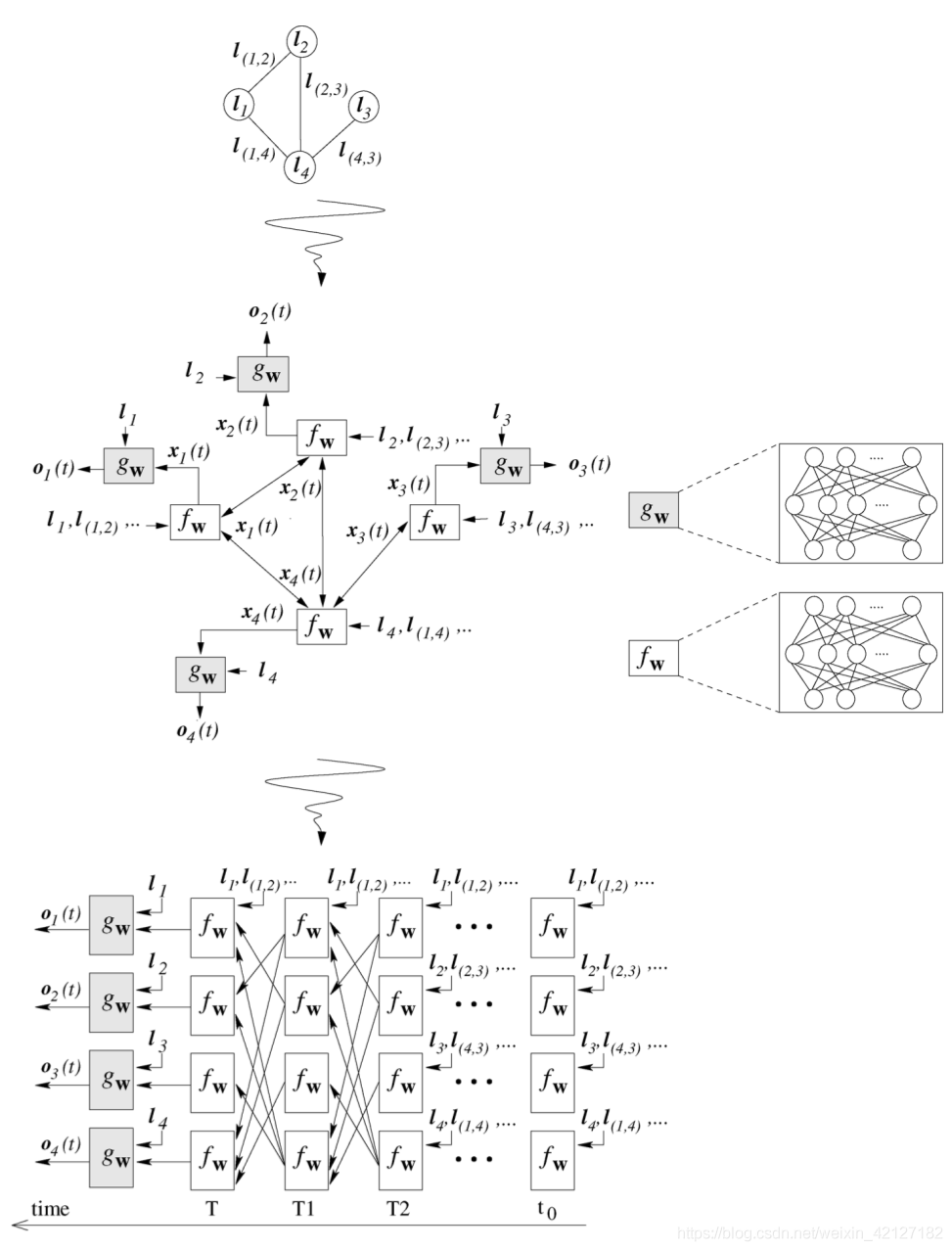
f w f_{\boldsymbol{w}} fw的层数,或者说迭代次数并非固定,当 x n \boldsymbol{x}_{n} xn达到收敛时停止,和RNN decoder输出<EOS>时跳出循环有点类似,当然也有所不同2。
(f和w只要保证压缩映射即可,但笔者总感觉这样的网络结构并不优雅)
之后的GNN大都脱离这篇论文的原理,转向借鉴CNN/RNN的经验。
GGNN
事实上,我们很容易得到一个朴素的思想:节点的信息可以根据邻居节点的信息取平均得到(当然也可以加入自身的信息)。
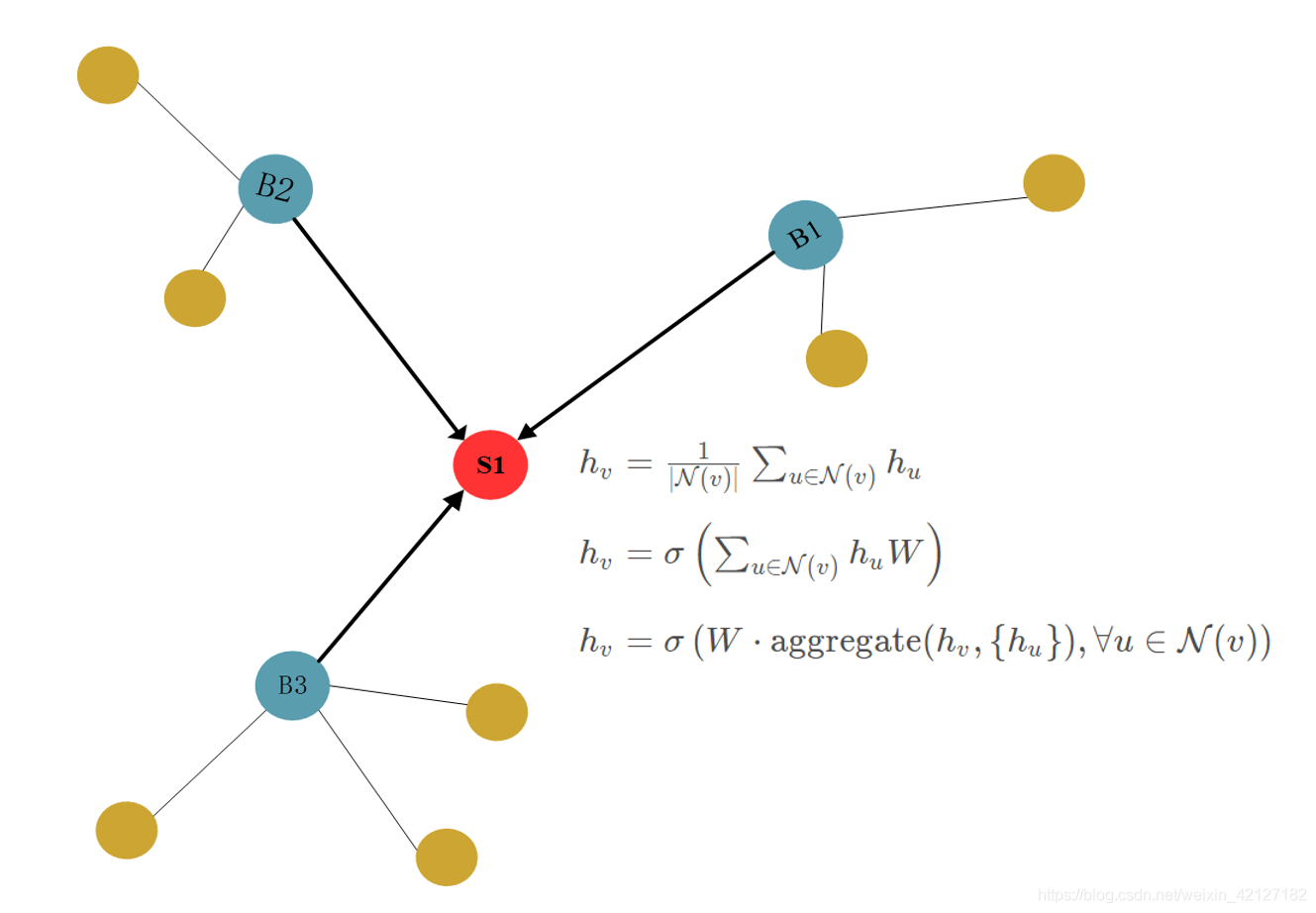
(或者是其他更复杂的手段,但这是之后GCN、GraphSAGE的思路了。)
GGNN的想法就非常简单,对邻居节点求和就是他的信息聚合方式。当邻接矩阵 A \mathbf{A} A有边为1,无边为0时,他有个更紧致的表达形式。
h v = 1 ⋅ ∑ u ∈ N ( v ) h u + 0 ⋅ ∑ u ∉ N ( v ) h u = A v : ⊤ H h_v=1 \cdot \sum_{u \in \mathcal{N}(v)} h_u + 0 \cdot \sum_{u \notin \mathcal{N}(v)} h_u = \mathbf{A}_{v:}^{\top}\mathbf{H} hv=1⋅∑u∈N(v)hu+0⋅∑u∈/N(v)hu=Av:⊤H
如果再加上偏置项,我们就得到了论文中描述的公式(2):
a v ( t ) = A v : ⊤ [ h 1 ( t − 1 ) ⊤ … h ∣ V ∣ ( t − 1 ) ⊤ ] ⊤ + b \mathbf{a}_{v}^{(t)}=\mathbf{A}_{v:}^{\top}\left[\mathbf{h}_{1}^{(t-1) \top} \ldots \mathbf{h}_{|\mathcal{V}|}^{(t-1) \top}\right]^{\top}+\mathbf{b} av(t)=Av:⊤[h1(t−1)⊤…h∣V∣(t−1)⊤]⊤+b
GGNN原论文没有提及平均,SRGNN采取了平均的方式,也就是归一化邻接矩阵 A \mathbf{A} A。平均并非必须,但我以为平均或者加权平均是有意义的。
一个可能的解释是:每个邻居传递来的信息都包含一个噪音 ϵ \epsilon ϵ,做了求和后,噪音也会随之增大,平均后可以使得噪音不会因为邻居数增多。
另一个可能的解释来自随机游走的思想,假设不区分邻居节点,一个节点有等分的概率游走到某一个邻居节点。
当然,你会说每个节点传递来的信息重要性不一定一样,或者说边的权重应当不同,应当加权平均,那就是GAT做的工作了。SRGNN也提到了weighted connections,但也只是简单的除以节点的度做平均。
不同类型的边
GGNN认为出边和入边是不同的,需要分别计算。
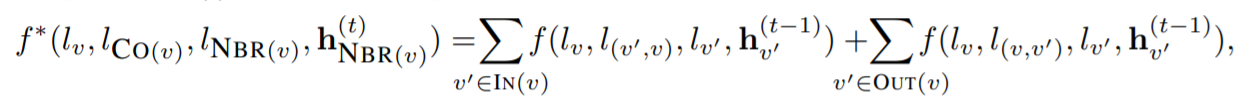
出边、入边分别构成邻接矩阵,两个邻接矩阵拼接在一起(这是形式上的表示,代码实现时可以分开计算,不一定要拼接在一起)。以SRGNN的图示为例:
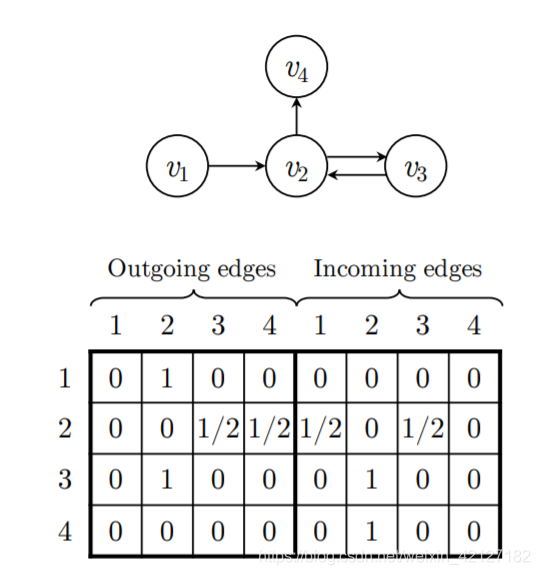
不仅仅是出入边的区分,如果图中有多种边,可以同样拼接在后面,我所见到的一个第三方实现3似乎是这样。这有点类似于多层卷积的层次化特征提取思想,每一种边对应不同的权重。
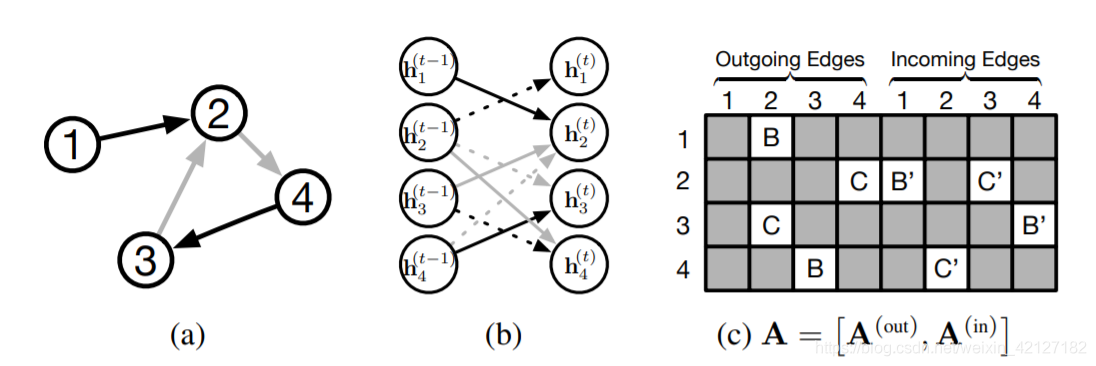
但GGNN提供的概念图没有展示这种不断拼接的做法,只是说参数决定于边的类型和方向。如果不用拼接,简单的情形是为每种边分配一个固定的权重。
每种边代入其embedding应该也是可行的,不过维度变化后需要进行映射。
关于padding的疑惑

GGNN在第一步对 L V L_V LV维的节点特征向量用0填补,扩充至 D D D维,这里实在让人困惑,论文只是说通过这样的方式让hidden state的维度大于特征向量annotation。这确实是一种方式,但私以为state维度未必需要大于feature(annotation),也未必需要区分state和feature,state就是和embedding一个向量空间中也未尝不可。即便一定要有一个维度更大的状态向量,加一个矩阵做线性变换映射不也可以吗。
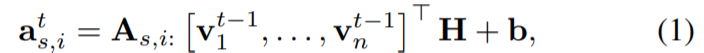
SRGNN是随机初始化的embedding,然后再通过权重矩阵 H \mathbf{H} H映射为hidden state。
我实在没有想到一定要填补0的情形,如果读者有其他的领会,还请麻烦解惑。
传播
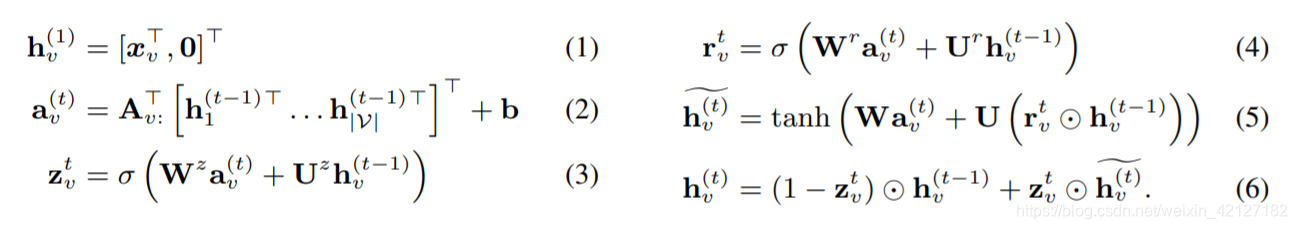
与GRU类比,需要两个输入向量: a v ( t ) a_v^{(t)} av(t)作为当前时间步的输入向量, h v ( t − 1 ) h_v^{(t-1)} hv(t−1)为上一时间步的状态向量。接下来和GRU一样得到遗忘门 z \mathbf{z} z 和重置门 r \mathbf{r} r,最后得到新时刻的状态向量 h v ( t ) h_v^{(t)} hv(t),可以直接作为节点的embedding,但也可以和GNN一样再映射一次;
o n = g w ( x n , l n ) \boldsymbol{o}_{n} =g_{\boldsymbol{w}}\left(\boldsymbol{x}_{n}, \boldsymbol{l}_{n}\right) on=gw(xn,ln)
如果是整张图输出一个向量,采取soft attention的形式加权求和输出:

时间步数是一个自由设置的超参,可以重复实验选择指标最大的超参,设置为1只传播一次也没问题(SRGNN的默认参数)。GGNN不像GRU那样循环次数由输入的序列长度决定,但之所以朝着GRU设计,是因为这样可以得到一个序列性的输出。
输出模型
该拓展模型称为GGSNN.
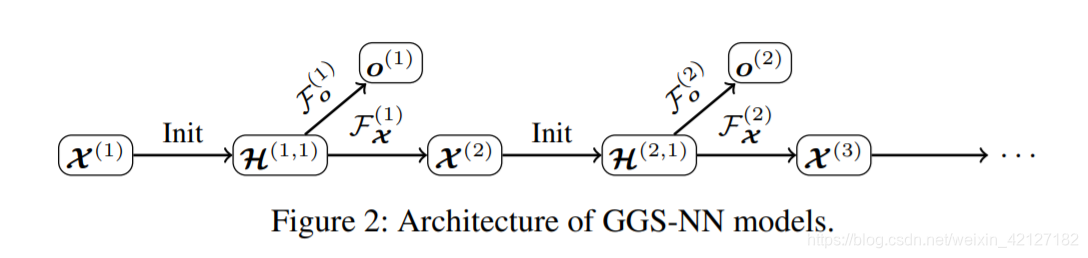
F X ( k ) , F o ( k ) \mathcal{F}_{\mathcal{X}}^{(k)}, \mathcal{F}_{o}^{(k)} FX(k),Fo(k)分别负责更新和输出,可以是两个独立的GGNN,也可以共享GGNN的传播层而由两个不同的输出层输出(虽然减少了训练开销,但要求传播行为不同时效果可能不好)。
SRGNN
Motivation
这篇论文独创性并不多,与其说SRGNN,不如称为GGNN4rec,最大的贡献是首次将GNN应用于会话推荐。
无论是最早的HMM,还是基于RNN的模型,一般都把会话视作马尔科夫链,或者说序列建模。
SRGNN将会话历史视作一张有向图,除了考虑某item与相邻的前item的联系外,还考虑了与其他有交互的item之间的联系(会话图中的节点可能会有多个入点出点,但至少比RNN多考虑了后一个item),也就是考虑了上下文的过渡信息。另外,序列推荐的输出来自最后一个item,SRGNN认为会话(尤其是短时间的会话)中应该更考虑整体的信息。
核心模型
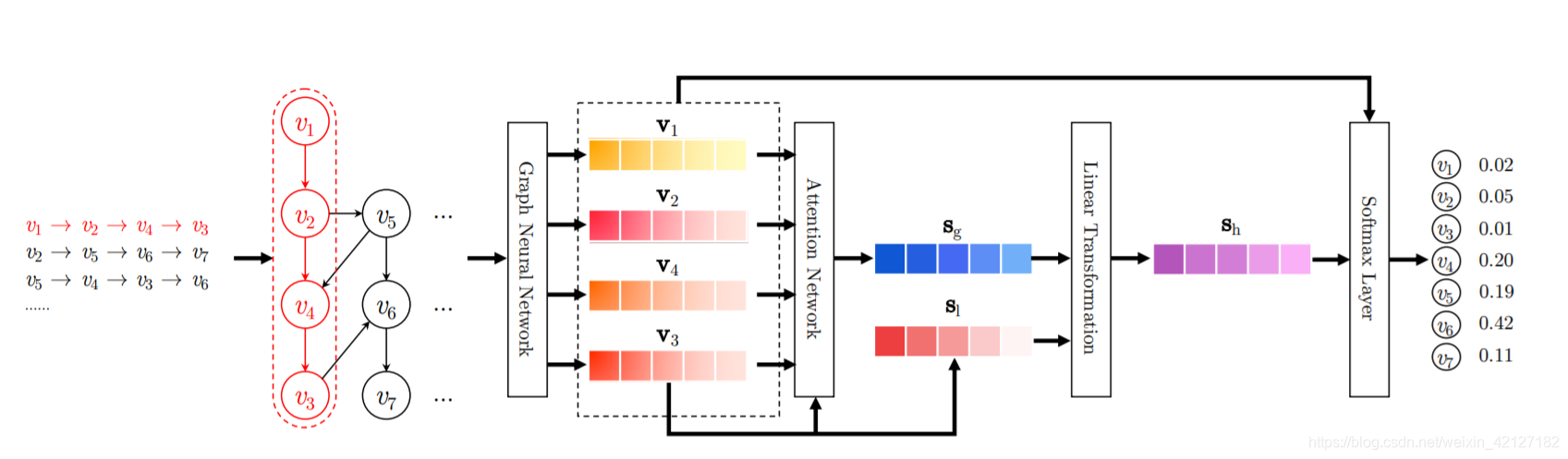
SRGNN利用GGNN进行item embedding的计算。
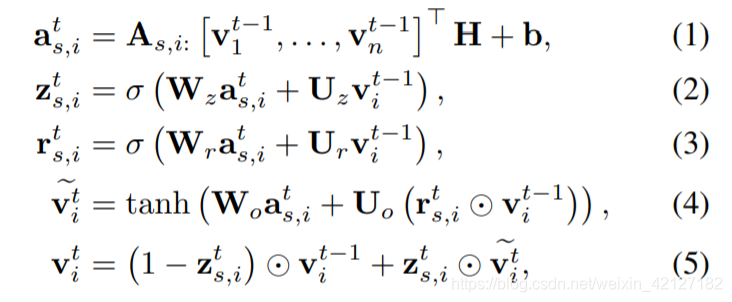
整个数据集item之间的转移构成了一张非常大的图,但SRGNN只考虑一个会话中出现的item构成的子图,在会话不是很长时,就不会有内存溢出的问题。(上面的图示右侧输出了7个item的score,容易引起误会,应该是4个,而非batch中item总数)
SRGNN也是用了data augmentation的方式,将一条session增广为多条,即 [ v 1 , v 2 ] , [ v 1 , v 2 , v 3 ] , . . . , [ v 1 , v 2 , . . . , v n ] [v_1, v_2], [v_1, v_2, v_3], ..., [v_1, v_2, ..., v_n] [v1,v2],[v1,v2,v3],...,[v1,v2,...,vn]
另外,直接根据图计算,会出现原始序列顺序混淆的情况,比如
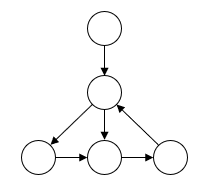
无法明确地指出第二个节点先指向哪个节点,尽管这种情况发生的概率很小。数据增广就可以保证顺序信息的完整。
和GGNN一样,得到的新embedding通过注意力机制计算得到一个global session embedding s g s_g sg
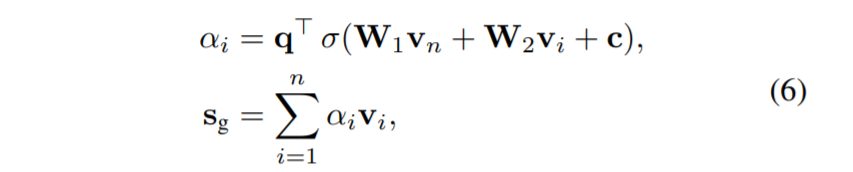
虽然注意力计算中也单独加入了最近item v n v_n vn来强调用户的当前兴趣,但SRGNN借鉴NARM,也同时加入了local session embedding, s l s_l sl可以简单地使用最后一个item的embedding来表示。

然后拼接两个session emb,通过一个Linear层计算出混合的session emb,

最后作为user vector,和item embedding计算score,由交叉熵来控制损失。
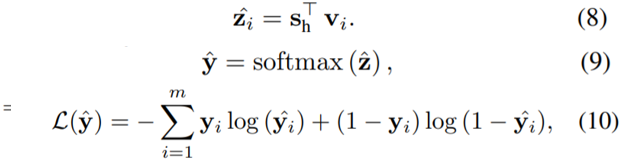
同样地,SRGNN也继承了GGNN的缺点,比如复杂的噪声连接和过平滑问题(各节点互相学习削弱了差异)等。
比较
| GRU4rec | SRGNN |
|---|---|
| 序列模型,只考虑上一节点到当前节点的过渡关系 | 图模型,考虑更复杂的过渡关系,包括若干出点和入点与当前节点的联系 |
| 仅考虑用户的当前兴趣 | 使用Attention机制,考虑用户的当前兴趣和整体兴趣 |
| 循环次数由序列长度决定 | 循环次数是个超参,SRGNN默认为1 |
| 有负采样,pairwise loss(BPR、TOP1) | 没有负采样,pointwise loss(NLL) |
| minibatch,代码比较复杂 | data augmentation,实现比较简单(但序列长度较长时不适用于RNN) |
前三行也是GRU和GGNN的区别
智能推荐
干货丨初学者学Java应该安装什么软件?-程序员宅基地
文章浏览阅读4.9k次。初学者刚刚入门学习需要用到一些开发工具,初学Java一般从控制台应用程序开发开始的,在cmd下调试,为你的电脑搭建好开发环境,需要在网站上下载JDK,安装完成后调试成功就可以开始写你的J..._新手学java用什么软件
PG数据库AUTOVACUUM的优化小技巧_autovacuum_max_workers work_mem-程序员宅基地
文章浏览阅读1k次,点赞8次,收藏18次。该阈值的计算是基于一些参数的设置的,这个设置可以是全局性的,也可以是针对某张表的(比如上面的storage参数),如autovacuum_vacuum_threshold,autovacuum_analyze_threshold,autovacuum_vacuum_scale_factor,和autovacuum_analyze_scale_factor。基于上面的原理,为某些大表设置合理的阈值,从而确保autovacuum在一种对业务系统影响尽可能小的平衡状态下运行,就可以确保业务系统长期稳定的运行。_autovacuum_max_workers work_mem
pycharm对django代码objects无代码提示问题的解决方案_department.objects.create无提示-程序员宅基地
文章浏览阅读4.2k次。pycharm对django代码objects无代码提示问题的解决方案最近新建的一个项目,使用的django,编辑器pycharm,很诡异的是,别的旧项目,也是django写的,代码提示都是好用的,就这个,模型类.objects.filter()这样的语句都没有代码提示。最近新建的一个项目,使用的django,编辑器pycharm,很诡异的是,别的旧项目,也是django写的,代码提示都是好用的..._department.objects.create无提示
VMware和Ubuntu安装-程序员宅基地
文章浏览阅读754次。一、VMware安装过程首先选择创建新的虚拟机 选择“自定义(高级)”点击“下一步” 在“选择虚拟机硬件兼容性”对话框中不更改任何设置,点击“下一步” 在下图中点击“稍后安装操作系统” 在“选择客户机操作系统”对话框中选择Linux 版本是:Ubuntu,点击“下一步” 在“命名虚拟机”选项卡中,虚拟机名称改为“master”,位置处是指该虚拟操作系统的安装路径,根据个人选择决定。..._vmware和ubuntu安装
计算机系学python吗_非计算机专业想自学python学成的可能性大吗?-程序员宅基地
文章浏览阅读1k次。我在知乎上也多次回答Python学习相关的话题了,总结出核心三点:学不会就别学了;短时间自学突击;写个实例。学不会就别学了:在现代比较常见的编程语言里,Python几乎是最简单的了。论简单性与Python同级别的也就剩下JavaScript和Basic了,而Basic在现代用处也很小,JavaScript则主要用于浏览器上的前端编程。所以通用性和简单性都不错的就剩下个Python。所以呢,简单如P..._计算机应用技术学python吗
【SpringBoot】排除不需要的自动配置类DataSourceAutoConfiguration_springboot排除configuration-程序员宅基地
文章浏览阅读7.4k次,点赞10次,收藏14次。一、排除自动配置类的三种方式以下三种方式可以用来排除任意的自动配置类1.1使用@SpringBootApplication注解排除使用exclude属性(value是Class对象数组)@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)public class DemoApplication { public static void main(String[] args) { S..._springboot排除configuration
随便推点
Pycharm2018的激活方法或破解方法_jetbrains pycharm 2018.1.6 x64 激活-程序员宅基地
文章浏览阅读725次。本教程对jetbrains全系列可用例:IDEA、WebStorm、phpstorm、clion等。因公司的需求,需要做一个爬取最近上映的电影、列车号、航班号、机场、车站等信息,所以需要我做一个爬虫项目,当然java也可以做爬虫,但是还是没有python这样方便,所以也开始学习Python啦!!!欲善其事,必先利其器。这里我为大家提供了三种激活方式: 授权服务器激活:适合小白,一步..._jetbrains pycharm 2018.1.6 x64 激活
程序员职业发展与规划:我要做一辈子的程序员吗?-程序员宅基地
文章浏览阅读2.4w次,点赞35次,收藏92次。经常听一些同学说:不知道下一份工作该去哪类公司做些什么,我的职场人际一团糟老板不重视我,我现在成长的非常慢所以又想跳槽了,我看不到公司的发展前景好迷茫,其实这一切的困惑都来源于没有做好职业规划或者你根本就没有职业规划过。那今天我就从以下几个话题和大家分享下我所理解的职业规划 Tips ,也欢迎大家踊跃提问。为什么要做职业规划?我们先聊聊第一个话题,为什么要做职业规划?首先,我们要知道职业规划是什么...
西门子PCS7常见报警及故障说明_西门pcs7 梯度报警-程序员宅基地
文章浏览阅读7.3k次。西门子PCS7过程控制系统,运行时常见的故障及报警说明。_西门pcs7 梯度报警
主流技术Java、Python怎么学?如何提升你的编程基本功?(MySQL、Linux、算法的核心知识讲解,瓶颈期的你如何做提升?)_会java,python,mysql,html怎么说-程序员宅基地
文章浏览阅读1.3k次,点赞2次,收藏18次。前言关于Java、Python这两个目前“斗”的最狠的编程语言,我相信很多人都并不陌生,每一个拿出来将都是长篇大论,所以我就长话短说,希望帮助你在未来的编程生涯中,对于主语言的选择有一些帮助。注意:此部分内容我不会对任何一种编程语言进行褒贬,只做客观的事实陈述。至于MySQL、Linux、算法,结合的经验来看,无论你未来从事什么开发,我建议你都去学一学,无论是求职还是整体编程技能的提升,都有莫大的帮助。在本文的后半段,我也会为你讲解这些技术栈。1、以下内容主要来自我的编程经验体会,部分来源于_会java,python,mysql,html怎么说
消息队列接口API(posix 接口和 system v接口)-程序员宅基地
文章浏览阅读4次。消息队列 posix API消息队列(也叫做报文队列)能够克服早期unix通信机制的一些缺点。信号这种通信方式更像\"即时\"的通信方式,它要求接受信号的进程在某个时间范围内对信号做出反应,因此该信号最多在接受信号进程的生命周期内才有意义,信号所传递的信息是接近于随进程持续的概念(process-persistent);管道及有名管道则是典型的随进程持续IPC,并且,只能传送无格式的字节流无疑...
【Python】可视化:常见统计图的汇总(含源代码示例)_python统计图-程序员宅基地
文章浏览阅读6k次,点赞12次,收藏68次。【Python】可视化:常见统计图的汇总(含源代码示例)_python统计图