前言
本打算花一篇文章来聊聊JVM内存管理机制,结果发现越扯越多,于是分了四遍文章(文章讲解JVM以Hotspot虚拟机为例,jdk版本为1.8),本文为其中第一篇。from 你必须了解的java内存管理机制-运行时数据区
相关链接(注:文章讲解JVM以Hotspot虚拟机为例,jdk版本为1.8,个人技术博客www.17coding.info)
1、 你必须了解的java内存管理机制-运行时数据区
2、 你必须了解的java内存管理机制-内存分配
3、 你必须了解的java内存管理机制-垃圾标记
4、 你必须了解的java内存管理机制-垃圾回收
正文
C++与java之间有一堵由内存动态分配和垃圾收集技术所围成的“高墙”,墙外的人想进去,墙里的人却想出来……
与C、C++程序员时刻要关注着内存的分配与释放,会不会又有哪里出现了内存泄露不同是,java程序员可以“高枕无忧”。因为这一切都已经有jvm来帮我们管理了,java程序员只需要关注具体的业务逻辑就可以了,至于内存分配与回收,交给jvm去干吧。但这样也带来一个问题,我们不再去关注内存分配了,不再去关注内存回收了。一旦出现内存泄露就束手无策了,在不同的应用场景,怎么样去做性能调优就成了一个问题。所以,对于java程序员来说,这些是必须了解的一部分。
没有对象怎么办?new一个啊。单身狗程序员每次提到new对象都激动不已,可是你的对象是怎么new出来的?new出来又放在哪里?怎么引用的?你的对象被别人动了怎么办?使用完成之后又是如何释放的?何时释放的?等等等等这些问题,如果你不能很轻松的回答出来,那么在本系列文章中你可能会找到一些答案。当然,本人才疏学浅,文笔拙劣,只是抛砖引玉,理解不周到或者有误的地方,欢迎拍砖。
JVM内存区域可以大致划分为“线程隔离区域”和“线程共享区域”。所谓“线程隔离区域”即线程非共享区域,每个线程独享的,执行指令操作机存放私有数据。不管做什么操作,不会影响到其他线程。可以想象成,你个人电脑硬盘中的苍老师,只能你一个人在夜深人静的时候拉上窗帘独自享受,别人无法同你分享,你删除或者新下载也不会对别人造成影响。而“线程共享区域”则是所有的线程共同拥有的,主要存放对象实例数据。如果A线程对这块区域的某个数据进行了修改,而刚好B线程正在使用或者需要使用该数据,则A线程对数据的修改在B线程中也会得到体现。可以想象成你把苍老师传到了某社区,这时候网上其他人都能共享你的苍老师了。当大家看得正兴奋的时候,你突然删掉了你上传的老师,这时候大家都只能去寻找新的素材了………,不知道你是否对“线程隔离区域”和“线程共享区域”的概念有了个大致了解。在jvm中,线程隔离区域包含程序计数器、本地方法栈、虚拟机栈。线程共享区域包含堆区、永久代(jdk1.8中废除永久代)、直接内存(jdk1.8中新增)(看下图)
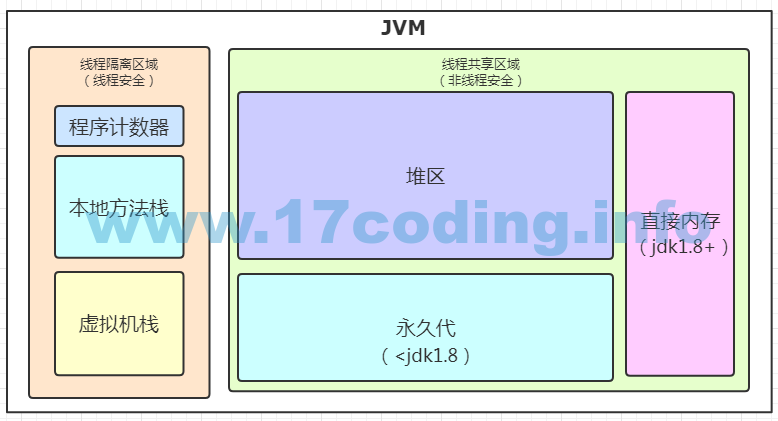
一、这是我的私人住所,我不同意,你们别来!-线程隔离区域
线程隔离区域存放什么数据呢?局部变量、方法调用的压栈操作等。线程隔离区域包含巴拉巴拉……(看下图)
1、睡了一觉,刚刚我做到哪了?-程序计数器
我们都知道在多线程的场景下,会发生线程切换,如果当前执行的线程让出执行权,则线程会被挂起,当线程再次被唤醒的时候,如果没有程序计数器线程可能就懵逼了,我是谁?我在哪?我要做什么?。但是如果有了程序计数器,线程就能找到上次执行到的字节码的位置继续往下执行。程序计数器可以理解为当前线程正在执行的字节码指令的行号指示器。分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
查阅了一些资料,列出了程序计数器的三个特点,这里也列举一下
1)、如果线程正在执行的是Java 方法,则这个计数器记录的是正在执行的虚拟机字节码指令地址
2)、如果正在执行的是Native 方法,则这个计数器值为空(Undefined)。因为Native方法大多是通过C实现并未编译成需要执行的字节码指令。那native 方法的多线程是如何实现的呢? native 方法是通过调用系统指令来实现的,那系统是如何实现多线程的则 native 就是如何实现的。Java线程总是需要以某种形式映射到OS线程上,映射模型可以是1:1(原生线程模型)、n:1(绿色线程 / 用户态线程模型)、m:n(混合模型)。以HotSpot VM的实现为例,它目前在大多数平台上都使用1:1模型,也就是每个Java线程都直接映射到一个OS线程上执行。此时,native方法就由原生平台直接执行,并不需要理会抽象的JVM层面上的“pc寄存器”概念——原生的CPU上真正的PC寄存器是怎样就是怎样。就像一个用C或C++写的多线程程序,它在线程切换的时候是怎样的,Java的native方法也就是怎样的。
3)、此内存区域是唯一一个在Java虚拟机规范中没有规定任何OutOfMemoryError情况的区域(程序运行过程中计数器中改变的只是值,而不会随着程序的运行需要更大的空间)
2、自己的事情自己做!-虚拟机栈
这个区域就是我们经常所说的栈,是java方法执行的内存模型,也是我们在开发中接触得很多的一块区域。虚拟机栈存放当前正在执行方法的时候所需要的数据、地址、指令。每个线程都会独享一块栈空间,每次方法调用都会创建一个栈帧,栈帧保存了方法的局部局部变量、操作数栈、动态链接、出口等信息。栈帧的深度也是有限制的,超过限制会抛出StackOverflowError异常。
我们结合一个例子来了解一下虚拟机栈和栈帧,我们有如下代码:
public class myProgram { public static void main(String[] args) { String str = "my String"; methodOne(1); } public static void methodOne(int i) { int j = 2; int sum = i + j; // ...... methodTwo(); // ..... } public static void methodTwo() { if (true) { int j = 0; } if (true) { int k = 1; } return; } }
代码很简单,main调用methodOne,methodOne调用methodTwo,如果当前正在执行methodTwo方法,则虚拟机栈中栈帧的情况应该是如下图情况,栈顶为正在执行的方法。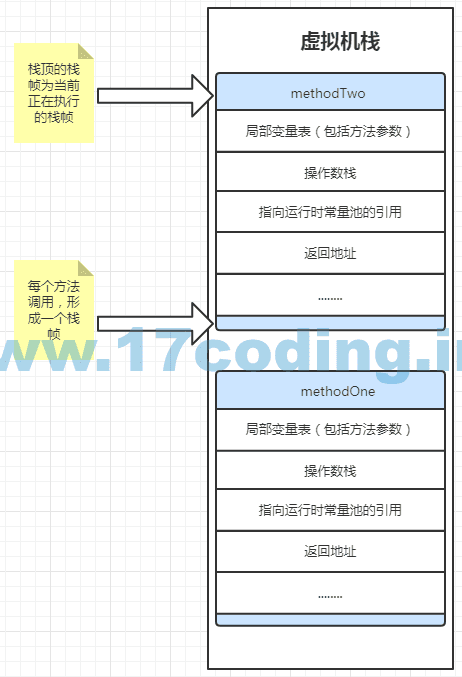
我们能看到,每个栈帧都包含局部变量表,操作数栈、动态链接、返回地址等……
1)、局部变量表
顾名思义,局部变量表就是存放局部变量的表,局部变量包括方法形参、方法内部定义的局部变量。局部变量表由多个变量槽(slot)组成,每个槽位都有个索引号,索引的范围是从0开始至局部变量最大的slot空间,虚拟机就是通过索引定位的方式使用局部变量表。比如在methodOne方法中,形参i就是在0号索引的slot中,局部变量j就放在1号索引的slot中,我们看看结合methodOne方法的字节码进行分析(通过javap -verbose myProgram查看字节码文件)。
public static void methodOne(int); descriptor: (I)V flags: ACC_PUBLIC, ACC_STATIC Code: stack=2, locals=3, args_size=1 0: iconst_2 1: istore_1 2: iload_0 3: iload_1 4: iadd 5: istore_2 6: invokestatic #4 // Method methodTwo:()V 9: return LineNumberTable: line 8: 0 line 9: 2 line 12: 6 line 14: 9
0:加载int类型常量2
1:存储到索引为1的变量中(这里指源程序中的j)
2:加载索引为0的变量(这里指源程序中的i)
3:加载索引为1的变量(这里指源程序中的j)
4:执行add指令
5:将执行结果存储到索引为2的变量中(这里指源程序中的sum)
6:静态调用
需要注意的一点是,为了尽可能节省栈帧的空间,局部变量表中的slot是可以重用的,方法体重定义的变量,其作用域不一定会覆盖整个方法体,我们看看methodTwo的源码,第一个if和第二个if的作用域不一样,所以内部变量可能是用的同一个slot,我们可以通过methodTwo方法的字节码来验证一下
public static void methodTwo(); descriptor: ()V flags: ACC_PUBLIC, ACC_STATIC Code: stack=1, locals=1, args_size=0 0: iconst_0 1: istore_0 2: iconst_1 3: istore_0 4: return LineNumberTable: line 19: 0 line 23: 2 line 26: 4
你看,我没骗你吧,methodTwo方法两个if中的变量j和k,使用的都是索引为0的slot。这样的设计可以节省栈帧的空间,同时也会影响jvm的垃圾回收,因为局部变量表是GC Root的一部分,局部变量表slot中当前存放的变量关联的对象为可达对象(后面讲到垃圾回收时候再详细讲)。
2)、操作数栈
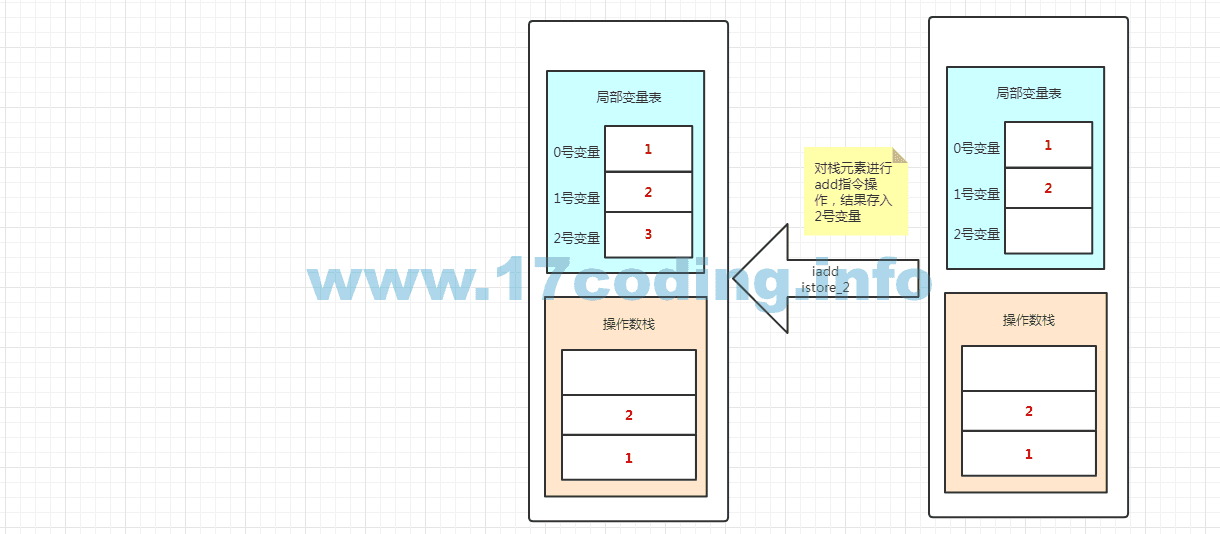
操作数栈也是一个栈,也看可以成为表达式栈。操作数栈和局部变量表在访问方式上有着较大的差异,它不是通过索引来访问,而是通过标准的栈操作—压栈和出栈—来访问的。我们对变量的操作都是在操作数栈中完成的,我们依然拿methodOne方法来举例。再看一下methodOne方法的字节码:
public static void methodOne(int); descriptor: (I)V flags: ACC_PUBLIC, ACC_STATIC Code: stack=2, locals=3, args_size=1 0: iconst_2 1: istore_1 2: iload_0 3: iload_1 4: iadd 5: istore_2 6: invokestatic #4 // Method methodTwo:()V 9: return LineNumberTable: line 8: 0 line 9: 2 line 12: 6 line 14: 9
下图为每一行字节码对应操作数栈和本地变量表之间的关系,具体看图,不用多做描述了。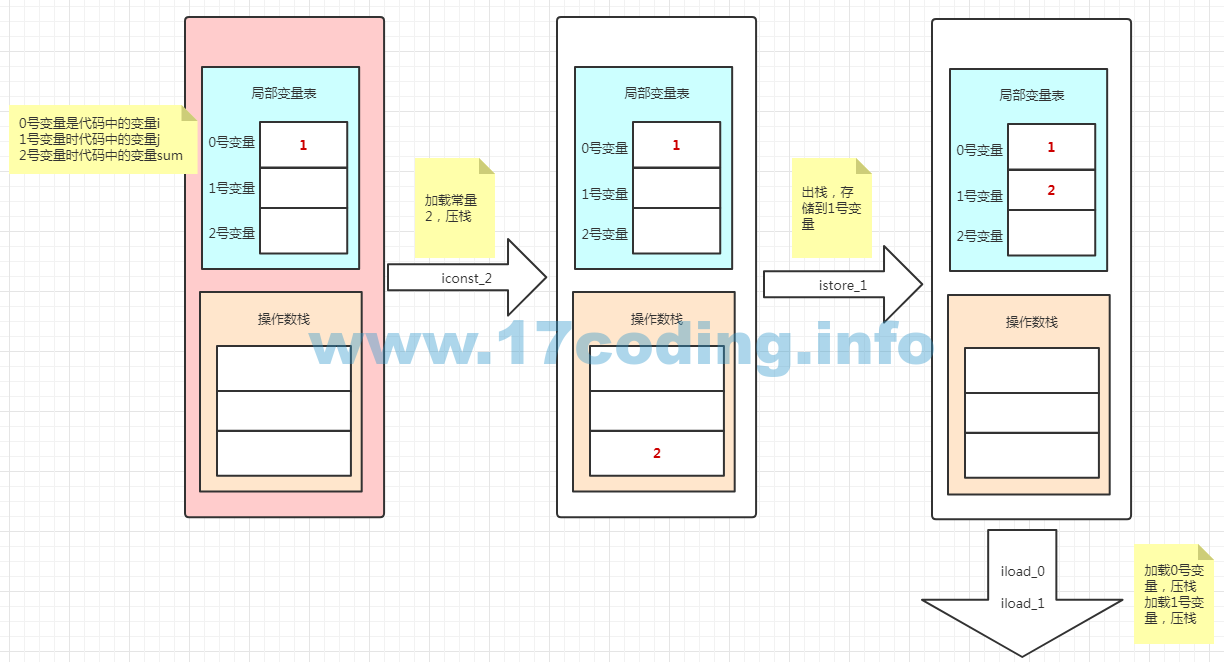
3)、动态链接
每个栈帧都包含一个指向运行时常量池中该栈帧所属方法的引用,持有这个引用是为了支持方法调用过程中的动态连接。刚开始看这一段的时候总是觉得很生涩,比较拗口。我们还是继续看那段代码的字节码文件,其中有一段叫做“Constant pool”,里面存储了该Class文件里的大部分常量的内容(包括类和接口的全限定名、字段的名称和描述符以及方法的名称和描述符)。
不知道你有没有注意我们字节码中是怎么处理menthodOne方法的调用的?在main方法中调用methodone方法的字节码为invokestatic #3,这里的#3就是一个” 符号引用”,我们发现#3还引用着另外的常量池项目,顺着这条线把能传递到的常量池项都找出来(标记为Utf8的常量池项)。由此我们可以看出,invokestatic 指令就是以常量池中指向方法的符号引用作为参数,完成方法的调用。这些符号引用一部分在类的加载阶段(解析)或第一次使用的时候就转化为了直接引用(指向数据所存地址的指针或句柄等),这种转化称为静态链接。而相反的,另一部分在运行期间转化为直接引用,就称为动态链接。我们看一下字节码中的常量池和符号引用,注意main方法中的#2 #3:
Constant pool: #1 = Methodref #6.#18 // java/lang/Object."<init>":()V #2 = String #19 // my String #3 = Methodref #5.#20 // myProgram.methodOne:(I)V #4 = Methodref #5.#21 // myProgram.methodTwo:()V #5 = Class #22 // myProgram #6 = Class #23 // java/lang/Object #7 = Utf8 <init> #8 = Utf8 ()V #9 = Utf8 Code #10 = Utf8 LineNumberTable #11 = Utf8 main #12 = Utf8 ([Ljava/lang/String;)V #13 = Utf8 methodOne #14 = Utf8 (I)V #15 = Utf8 methodTwo #16 = Utf8 SourceFile #17 = Utf8 myProgram.java #18 = NameAndType #7:#8 // "<init>":()V #19 = Utf8 my String #20 = NameAndType #13:#14 // methodOne:(I)V #21 = NameAndType #15:#8 // methodTwo:()V #22 = Utf8 myProgram #23 = Utf8 java/lang/Object public static void main(java.lang.String[]); descriptor: ([Ljava/lang/String;)V flags: ACC_PUBLIC, ACC_STATIC Code: stack=1, locals=2, args_size=1 0: ldc #2 // String my String 2: astore_1 3: iconst_1 4: invokestatic #3 // Method methodOne:(I)V 7: return LineNumberTable: line 3: 0 line 4: 3 line 5: 7
4)、返回地址
我们的经常使用return x;来使方法返回一个值给方法调用者,如果没有返回值的方法也可以在方法的方法需要返回的地方加上return;当然,这不是必须的,因为源码在转化为字节码的时候,总是会在方法的最后加上return指令,不信你看上面methodTwo方法的字节码那张图片。
正常情况下,方法遇到返回指令退出,这种退出方法的方式称为正常完成出口。如果方法正常返回,则当前栈帧从java栈中弹出,恢复发起调用者的方法的栈帧,如果方法有返回值,jvm会把返回值压入到发起调用方法的操作数栈。但是在异常情况下,方法执行遇到了异常,且这个异常在方法体内未得到处理,方法则会异常退出,这种退出方式称为异常完成出口。当异常抛出且没有被捕捉时,则方法立即终止,然后JVM恢复发起调用的方法的栈帧,如果在调用者中也未对异常进行捕捉,则调用者也会立即终止,层层向上,直到最外层抛出异常。
3、楼上做不了的事情,来我这做!-本地方法栈
本地方法是什么?本地方法就是在jdk中(也可以自定义)那些被Native关键字修饰的方法(下图)。这类方法有点类似java中的接口,没有实现体,但实际上是由jvm在加载时调用底层实现的,实现体是由非java语言(如C、C++)实现的,所以本地方法可以理解为连接java代码和其他语言实现的代码的入口。而本地方法栈的功能就类似于虚拟机栈,只是一个服务于java方法执行,一个服务于执行本地方法执行。
二、来啊,快活啊!反正有大把空间!-线程共享区域
1、 喂,你的对象都在这里!-堆
堆区域在jvm中是非常重要的一块区域,因为我们平常创建的对象的实例就存在在这个区域,这个区域的几乎是被所有线程共享。同时也是java虚拟机管理的内存中最大的一块。由于目前主流的垃圾收集器都采用分代收集算法,所以通常将堆细分为新生代、老年代,新生代又分为两块Eden区、From Survivor区、To Survivor区(这里主要针对通常使用的分代收集器,G1收集器采用不同的划分策略,后面有机会再讲)。不过不管怎么划分,目的都是为了更合理的利用内存,提高内存空间使用率,提高垃圾回收的效率和回收质量。下图展示了堆区域的划分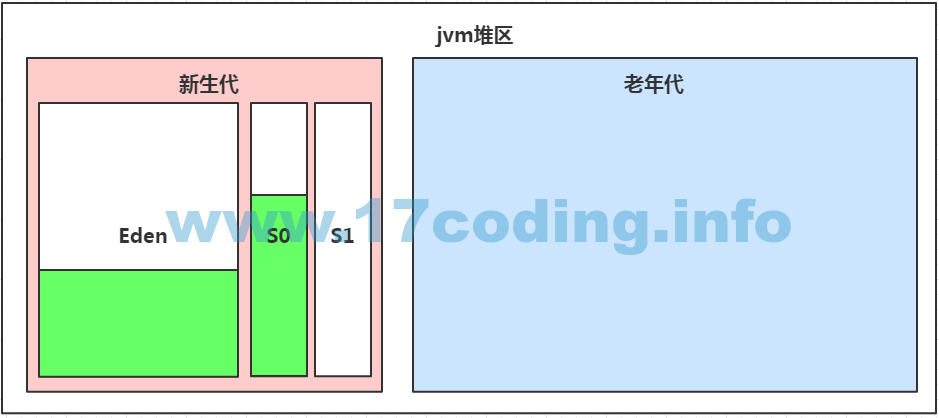
我们在这篇文章里只谈堆区内存的划分,关于内存分配、内存回收等会在下篇文章细讲,因为涉及的内容太多了……不过我们可以先思考几个问题1、为什么需要区分新生代、老年代?2、为什么将新生代分为Eden、Survivor区?各区大小怎么分配?有什么分配依据?
2、 治不了你?那我就废了你!-方法区
看标题可能会有些误解,其实这里废除的是永久代的概念,而不是方法区。刚开始总是搞不清这两者的关系,后来就去查阅了一些资料总算是搞清楚了一些,书上是这么说的:“JVM的虚拟机规范只是规定了有方法区这么个概念和它的作用,并没有规定如何去实现它。不同JVM的方法区的实现会不一样,比如在HotSpot中使用永久代实现方法区,其他JVM并没有永久代的概念。方法区是一种规范,永久代是一种实现。”
所以,我们常说的新生代、老年代、永久代中的永久代就是方法区的一种实现,且只存在于HotSpot虚拟机中有这种概念。用过jdk1.8之前的版本(HotSpot虚拟机)的同学应该经常能碰到永久代溢出的异常“java.lang.OutOfMemoryError: PermGen space”,这里的PermGen space指的是永久代。在jdk6中,永久代包含方法区和常量池,但是在jdk1.7的版本中规划去除永久代,于是在1.7中将常量池移到了老年代中。在jdk1.8中彻底废除了永久代,取而代之的是元空间。
3、 会有天使替我去爱你!-直接内存
永久代设置太大吧,浪费资源!永久代设置太小吧,溢出了!于是让人恼火的永久代溢出的异常时常发生,并且永久代的GC效率低下,于是,在jdk1.8中彻底废除了永久区,放到了直接内存的元空间中!元空间的本质和永久代类似,都是对JVM规范中方法区的实现。元空间相比永久代有什特性呢?永久代在物理上是堆的一部分,与新生代老年代的地址是连续的,而元空间属于本地内存,不受JVM控制,也不会发生永久代溢出的异常。
直接内存也可以称为堆外内存,为什么要将方法区放入到直接内存呢?
1、 永久代会为 GC 带来不必要的复杂度,并且回收效率偏低。
2、 类及方法的信息等比较难确定其大小,因此永久代调优较为困难,容易发生内存溢出。
3、 加快了复制的速度。因为堆内在flush到远程时,会先复制到直接内存(非堆内存),然后再发送,而堆外内存相当于省略掉了这个工作。
4、 Oracle 可能会将HotSpot 与 JRockit 合二为一