在成功完成基金净值爬虫的爬虫后,简单了解爬虫的一些原理以后,心中不免产生一点困惑——为什么我们不能直接通过Request获取网页的源代码,而是通过查找相关的js文件来爬取数据呢?
有时候我们在用requests抓取页面的时候,得到的结果可能和浏览器中看到的不一样:浏览器中可以看到正常显示的页面数据,但是使用requests得到的结果并没有。
这是因为requests获取的都是原始的HTML文档,而浏览器中的页面则是经过JavaScript处理数据后生成的结果,这些数据来源多种,可能是通过Ajax加载的,可能是包含在HTML文档中的,也可能是经过JavaScript和特定算法计算后生成的。而依照目前Web发展的趋势,网页的原始HTML文档不会包含任何数据,都是通过Ajax等方法统一加载后再呈现出来,这样在Web开发上可以做到前后端分离,而且降低服务器直接渲染页面带来的。通常,我们把这种网页称为动态渲染页面。
之前的基金净值数据爬虫就是通过直接向服务器获取数据接口,即找到包含数据的js文件,向服务器发送相关的请求,才获取文件。
那么,有没有什么办法可以直接获取网页的动态渲染数据呢?答案是有的。
我们还可以直接使用模拟浏览器运行的方式来实现动态网页的抓取,这样就可以做到在浏览器中看倒是什么样,抓取的源码就是什么样,即实现——可见即可爬。
Python提供了许多模拟浏览器运行的库,如:Selenium、Splash、PyV8、Ghost等。本文将继续以基金净值爬虫为例,用Selenium对其进行动态页面爬虫。
环境
tools
1、Chrome及其developer tools
2、python3.7
3、PyCharm
python3.7中使用的库
1、Selenium
2、pandas
3、random
4、 time
5、os
系统
Mac OS 10.13.2
Selenium基本功能及使用
准备工作
- Chrome浏览器
- Selenium库
- 可直接通过pip安装,执行如下命令即可:
-
pip install selenium
- ChromDriver配置
- Selenium库是一个自动化测试工具,需要浏览器来配合使用,我们主要介绍Chrome浏览器及ChromeDriver驱动的配置,只有安装了ChromeDriver并配置好对应环境,才能驱动Chrome浏览器完成相应的操作。Windows和Mac下的安装配置方法略有不同,具体可通过网上查阅资料得知,在此暂时不做赘述。
基本使用
首先,我们先来了解Selenium的一些功能,以及它能做些什么:
Selenium是一个自动化测试工具,利用它可以驱动游览器执行特定的动作,如点击、下拉等操作,同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬。对于一些动态渲染的页面来说,此种抓取方式非常有效。它的基本功能实现也十分的方便,下面我们来看一些简单的代码:
1 from selenium import webdriver 2 from selenium.webdriver.common.by import By 3 from selenium.webdriver.common.keys import Keys 4 from selenium.webdriver.support import expected_conditions as EC 5 from selenium.webdriver.support.wait import WebDriverWait 6 7 8 browser = webdriver.Chrome() # 声明浏览器对象 9 try: 10 browser.get('https://www.baidu.com') # 传入链接URL请求网页 11 query = browser.find_element_by_id('kw') # 查找节点 12 query.send_keys('Python') # 输入文字 13 query.send_keys(Keys.ENTER) # 回车跳转页面 14 wait = WebDriverWait(browser, 10) # 设置最长加载等待时间 15 print(browser.current_url) # 获取当前URL 16 print(browser.get_cookies()) # 获取当前Cookies 17 print(browser.page_source) # 获取源代码 18 finally: 19 browser.close() # 关闭浏览器
运行代码后,会自动弹出一个Chrome浏览器。浏览器会跳转到百度,然后在搜索框中输入Python→回车→跳转到搜索结果页,在获取结果后关闭浏览器。这相当于模拟了一个我们上百度搜索Python的全套动作,有木有觉得很神奇!!

在过程中,当网页结果加载出来后,控制台会分别输出当前的URL、当前的Cookies和网页源代码:

可以看到,我们得到的内容都是浏览器中真实的内容,由此可以看出,用Selenium来驱动浏览器加载网页可以直接拿到JavaScript渲染的结果。接下来,我们也将主要利用Selenium来进行基金净值的爬取~
注:Selenium更多详细用法和功能可以通过官网查阅(https://selenium-python.readthedocs.io/api.html)
基金净值数据爬虫
通过之前的爬虫,我们会发现数据接口的分析相对来说较为繁琐,需要分析相关的参数,而如果直接用Selenium来模拟浏览器的话,可以不再关注这些接口参数,只要能直接在浏览器页面里看到的内容,都可以爬取,下面我们就来试一试该如何完成我们的目标——基金净值数据爬虫。
页面分析
本次爬虫的目标是单个基金的净值数据,抓取的URL为:http://fundf10.eastmoney.com/jjjz_519961.html(以单个基金519961为例),URL的构造规律很明显,当我们在浏览器中输入访问链接后,呈现的就是最新的基金净值数据的第一页结果:
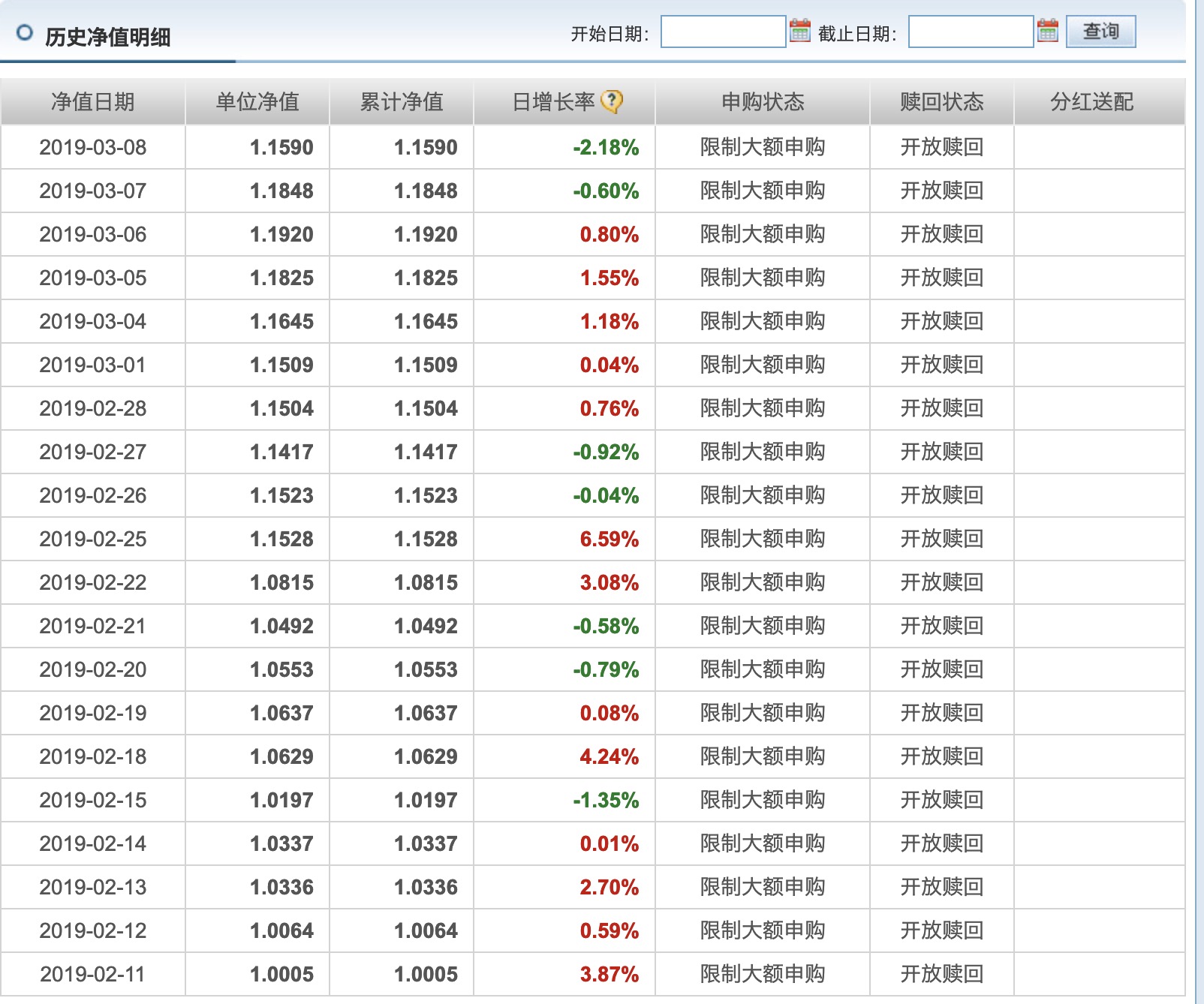
在数据的下方,有一个分页导航,其中既包括前五页的连接,也包括最后一页和下一页的连接,同时还有一个输入任意页码跳转的链接:
![]()
如果我们想获取第二页及以后的数据,则需要跳转到对应页数。因此,如果我们需要获取所有的历史净值数据,只需要将所有页码遍历即可,可以直接在页面跳转文本框中输入要跳转的页码,然后点击“确定”按钮即可跳转到页码对应的页面。
此处不直接点击“下一页”的原因是:一旦爬虫过程中出现异常退出,比如到50页退出了,此时点击“下一页”时,无法快速切换到对应的后续页面。此外,在爬虫过程中也需要记录当前的爬虫进度,能够及时做异常检测,检测问题是出在第几页。整个过程相对较为复杂,用直接跳转的方式来爬取网页较为合理。
当我们成功加载出某一页的净值数据时,利用Selenium即可获取页面源代码,定位到特定的节点后进行操作即可获取目标的HTML内容,再对其进行相应的解析即可获取我们的目标数据。下面,我们用代码来实现整个抓取过程。
获取基金净值列表
首先,需要构造目标URL,这里的URL构成规律十分明显,为http://fundf10.eastmoney.com/jjjz_基金代码.html,我们可以通过规律来构造自己想要爬取的基金对象。这里,我们将以基金519961为例进行抓取。
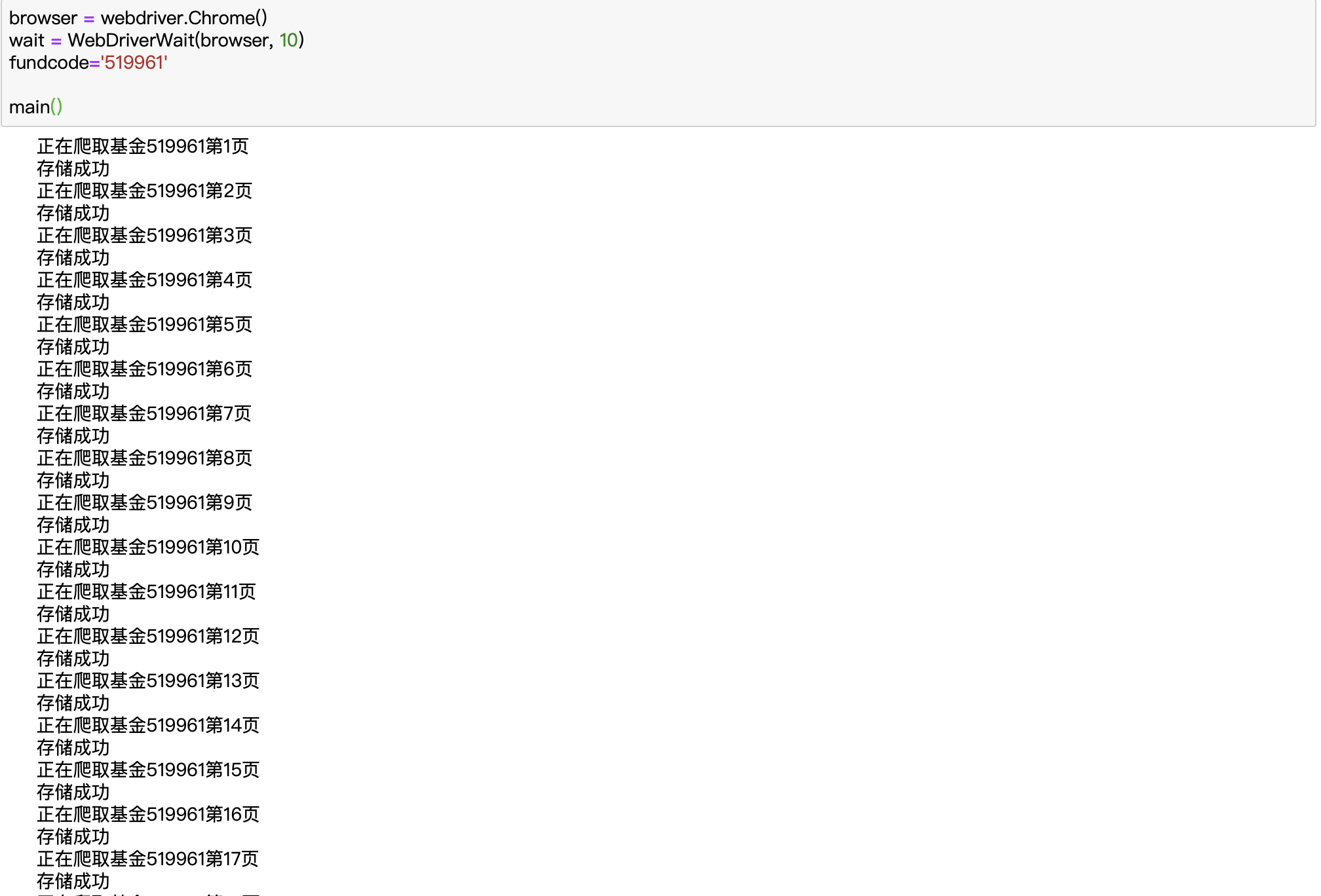
1 browser = webdriver.Chrome() 2 wait = WebDriverWait(browser, 10) 3 fundcode='519961' 4 5 def index_page(page): 6 ''' 7 抓取基金索引页 8 :param page: 页码 9 :param fundcode: 基金代码 10 ''' 11 print('正在爬取基金%s第%d页' % (fundcode, page)) 12 try: 13 url = 'http://fundf10.eastmoney.com/jjjz_%s.html' % fundcode 14 browser.get(url) 15 if page>1: 16 input_page = wait.until( 17 EC.presence_of_element_located((By.CSS_SELECTOR, '#pagebar input.pnum'))) 18 submit = wait.until( 19 EC.element_to_be_clickable((By.CSS_SELECTOR, '#pagebar input.pgo'))) 20 input_page.clear() 21 input_page.send_keys(str(page)) 22 submit.click() 23 wait.until( 24 EC.text_to_be_present_in_element((By.CSS_SELECTOR, '#pagebar label.cur'), 25 str(page))) 26 wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#jztable'))) 27 get_jjjz() 28 except TimeoutException: 29 index_page(page)
这里,首相构造一个WebDriver对象,即声明浏览器对象,使用的浏览器为Chrome,然后指定一个基金代码(519961),接着定义了index_page()方法,用于抓取基金净值数据列表。
在该方法里,我们首先访问了搜索基金的链接,然后判断了当前的页码,如果大于1,就进行跳页操作,否则等页面加载完成。
在等待加载时,我们使用了WebDriverWait对象,它可以指定等待条件,同时制定一个最长等待时间,这里指定为最长10秒。如果在这个时间内匹配了等待条件,也就是说页面元素成功加载出来,就立即返回相应结果并继续向下执行,否则到了最大等待时间还没有加载出来时,就直接抛出超市异常。
比如,我们最终需要等待历史净值信息加载出来就指定presence_of_element_located这个条件,然后传入了CSS选择器的对应条件#jztable,而这个选择器对应的页面内容就是每一页基金净值数据的信息快,可以到网页里面查看一下:

注:这里讲一个小技巧,如果同学们对CSS选择器的语法不是很了解的话,可以直接在选定的节点点击右键→拷贝→拷贝选择器,可以直接获取对应的选择器:
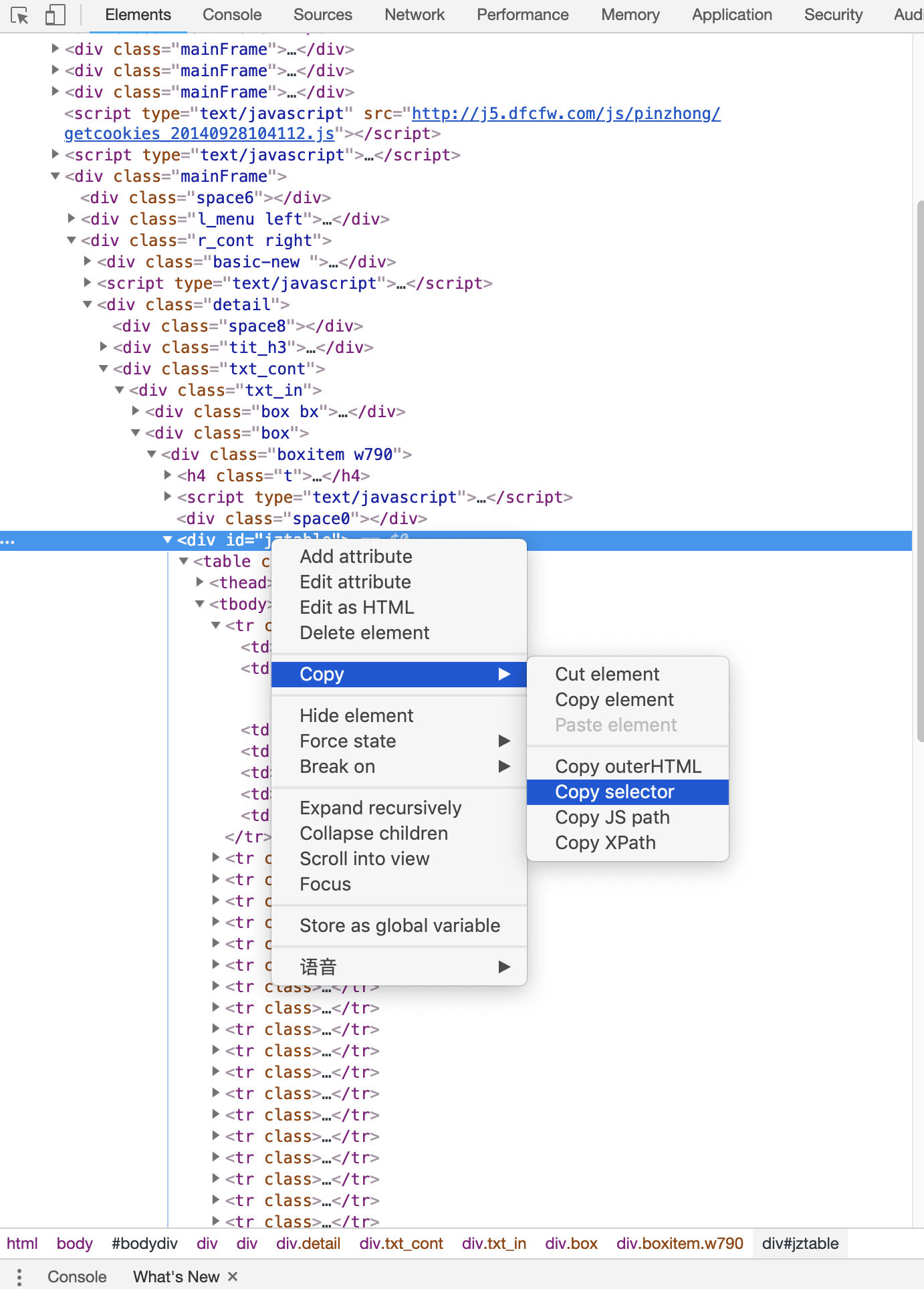
关于CSS选择器的语法可以参考CSS选择器参考手册(http://www.w3school.com.cn/cssref/css_selectors.asp)。
当加载成功后,机会秩序后续的get_jjjz()方法,提取历史净值信息。
关于翻页操作,这里首先获取页码输入框,赋值为input_page,然后获取“确定”按钮,赋值为submit:
首先,我们情况输入框(无论输入框是否有页码数据),此时调用clear()方法即可。随后,调用send_keys()方法将页码填充到输入框中,然后点击“确定”按钮即可,听起来似乎和我们常规操作的方法一样。
那么,怎样知道有没有跳转到对应的页码呢?我们可以注意到,跳转到当前页的时候,页码都会高亮显示:

我们只需要判断当前高亮的页码数是当前的页码数即可,左移这里使用了另一个等待条件text_to_be_present_in_element,它会等待指定的文本出现在某一个节点里时即返回成功,这里我们将高亮的页码对应的CSS选择器和当前要跳转到 页码通过参数传递给这个等待条件,这样它就会检测当前高亮的页码节点是不是我们传过来的页码数,如果是,就证明页面成功跳转到了这一页,页面跳转成功。
这样,刚从实现的index_page()方法就可以传入对应的页码,待加载出对应页码的商品列表后,再去调用get_jjjz()方法进行页面解析。
解析历史净值数据列表
接下来,我们就可以实现get_jjjz()方法来解析历史净值数据列表了。这里,我们通过查找所有历史净值数据节点来获取对应的HTML内容
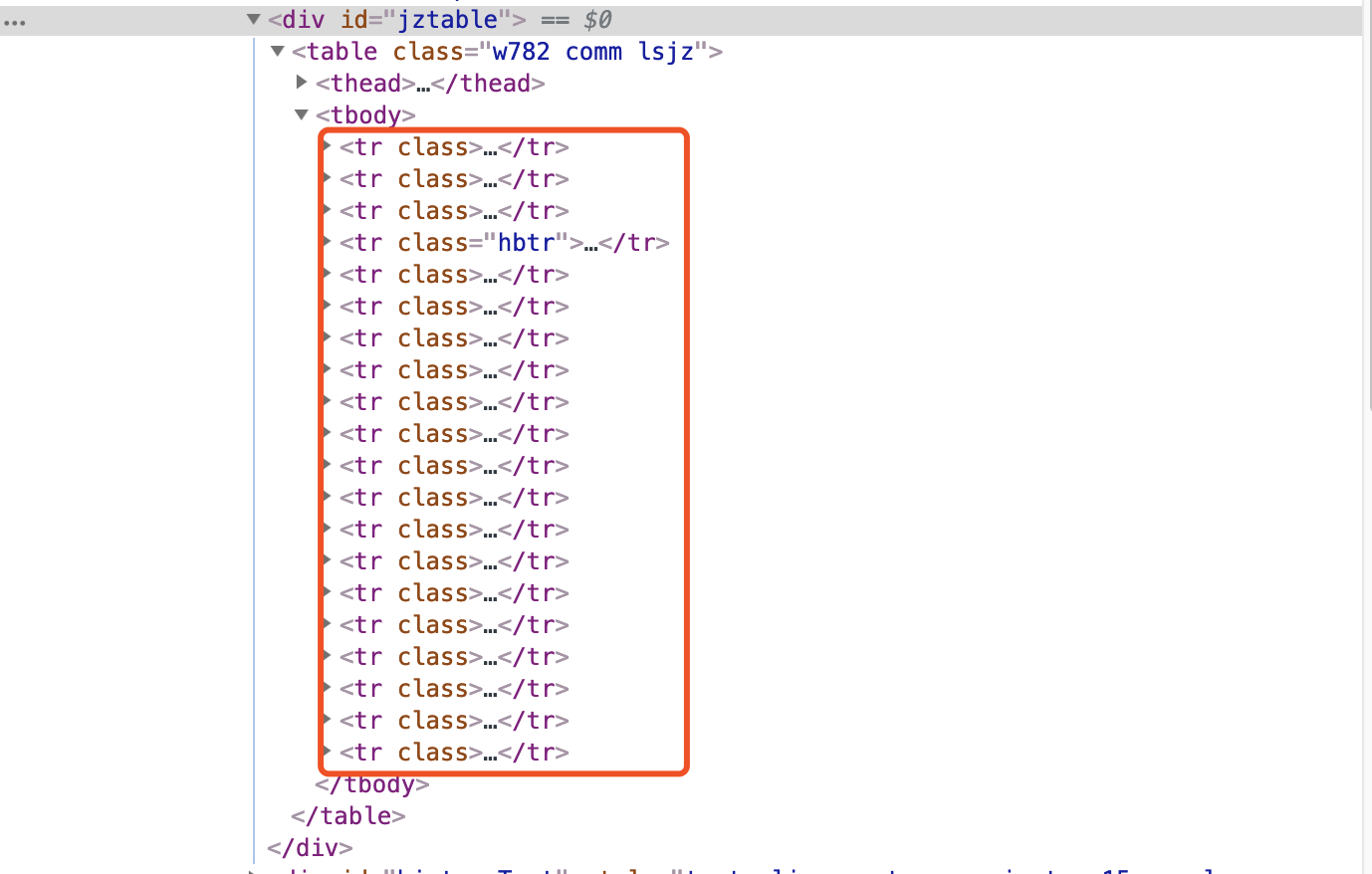
并进行对应解析,实现如下:
1 def get_jjjz(): 2 ''' 3 提取基金净值数据 4 ''' 5 lsjz = pd.DataFrame() 6 html_list = browser.find_elements_by_css_selector('#jztable tbody tr') 7 for html in html_list: 8 data = html.text.split(' ') 9 datas = { 10 '净值日期': data[0], 11 '单位净值': data[1], 12 '累计净值': data[2], 13 '日增长率': data[3], 14 '申购状态': data[4], 15 '赎回状态': data[5], 16 } 17 lsjz = lsjz.append(datas, ignore_index=True) 18 save_to_csv(lsjz)
首先,调用find_elements_by_css_selector来获取所有存储历史净值数据的节点,此时使用的CSS选择器是#jztable tbody tr,它会匹配所有基金净值节点,输出的是一个封装为list的HTML。利用for循环对list进行遍历,用text方法提取每个html里面的文本内容,获得的输出是用空格隔开的字符串数据,为了方便后续处理,我们可以用split方法将数据切割,以一个新的list形式存储,再将其转化为dict形式。
最后,为了方便处理,我们将遍历的数据存储为一个DataFrame再用save_to_csv()方法进行存储为csv文件。
保存为本地csv文件
接下来,我们将获取的基金历史净值数据保存为本地的csv文件中,实现代码如下:
1 def save_to_csv(lsjz): 2 ''' 3 保存为csv文件 4 : param result: 历史净值 5 ''' 6 file_path = 'lsjz_%s.csv' % fundcode 7 try: 8 if not os.path.isfile(file_path): # 判断当前目录下是否已存在该csv文件,若不存在,则直接存储 9 lsjz.to_csv(file_path, index=False) 10 else: # 若已存在,则追加存储,并设置header参数为False,防止列名重复存储 11 lsjz.to_csv(file_path, mode='a', index=False, header=False) 12 print('存储成功') 13 except Exception as e: 14 print('存储失败')
此处,result变量就是get_jjjz()方法里传来的历史净值数据。
遍历每一页
我们之前定义的get_index()方法需要接受参数page,page代表页码。这里,由于不同基金的数据页数并不相同,而为了遍历所有页我们需要获取最大页数,当然,我们也可以用一些巧办法来解决这个问题,页码遍历代码如下:
1 def main(): 2 ''' 3 遍历每一页 4 ''' 5 flag = True 6 page = 1 7 while flag: 8 try: 9 index_page(page) 10 time.sleep(random.randint(1, 5)) 11 page += 1 12 except: 13 flag = False 14 print('似乎是最后一页了呢')
其实现方法结合了try...except和while方法,逐个遍历下一页内容,当页码超过,即不存在时,index_page()的运行就会出现报错,此时可以将flag变为False,则下一次while循环不会继续,这样,我们便可遍历所有的页码了。
由此,我们的基金净值数据爬虫已经基本完成,最后直接调用main()方法即可运行。
总结
在本文中,我们用Selenium演示了基金净值页面的抓取,有兴趣的同学可以尝试利用其它的条件来爬取基金数据,如设置数据的起始和结束日期:

利用日期来爬取内容可以方便日后的数据更新,此外,如果觉得浏览器的弹出较为恼人,可以尝试Chrome Headless模式或者利用PhantomJS来抓取。
至此,基金净值爬虫的分析正式完结,撒花~
