大数据HDFS凭啥能存下百亿数据?_hdfs文件数量上限-程序员宅基地
前言
大家平时经常用的百度网盘存放电影、照片、文档等,那有想过百度网盘是如何存下那么多文件的呢?难到是用一台计算机器存的吗?那得多大磁盘啊?显然不是的,那本文就带大家揭秘。
分布式存储思想
既然一台机器的存储所需的磁盘有上限瓶颈,那么我们能否利用多台机器形成一个整体用来存储呢?这就是我们所说的分布式存储。
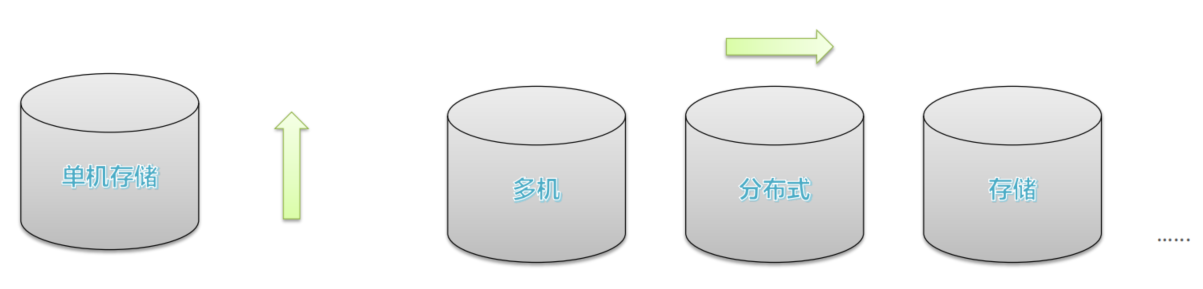
- 单机纵向扩展:磁盘不够加磁盘,有上限瓶颈限制
- 多机横向扩展:机器不够加机器,理论上无限扩展
Hadoop就是采用了这样的一个思想,设计出了分布式存储系统HDFS。
HDFS介绍和使用
HDFS(Hadoop Distributed File System ),意为:Hadoop分布式文件系统。它是Apache Hadoop核心组件之一,作为大数据生态圈最底层的分布式存储服务而存在。也可以说大数据首先要解决的问题就是海量数据的存储问题。
- HDFS主要是解决大数据如何存储问题的。分布式意味着是HDFS是横跨在多台计算机上的存储系统。
- HDFS是一种能够在普通硬件上运行的分布式文件系统,它是高度容错的,适应于具有大数据集的应用程序,它非常适于存储大型数据 (比如 TB 和 PB)。
- HDFS使用多台计算机存储文件, 并且提供统一的访问接口, 像是访问一个普通文件系统一样使用分布式文件系统。
HDFS使用
HDFS安装好了,具体是如何使用呢,如何上传和下载文件呢?一共有两种方式,通过shell命令和web页面。
- shell命令操作HDFS
类似linux命令,可以直接通过在命令行界面操作。Hadoop提供了文件系统的shell命令行客户端: hadoop fs [generic options]
- 创建文件夹
hadoop fs -mkdir [-p] <path> ...
path 为待创建的目录
-p 选项的行为与Unix mkdir -p非常相似,它会沿着路径创建父目录。
- 查看指定目录下内容
hadoop fs -ls [-h] [-R] [<path> ...]
path 指定目录路径
-h 人性化显示文件size
-R 递归查看指定目录及其子目录
- 上传文件到HDFS指定目录下
hadoop fs -put [-f] [-p] <localsrc> ... <dst>
-f 覆盖目标文件(已存在下)
-p 保留访问和修改时间,所有权和权限。
localsrc 本地文件系统(客户端所在机器)
dst 目标文件系统(HDFS)
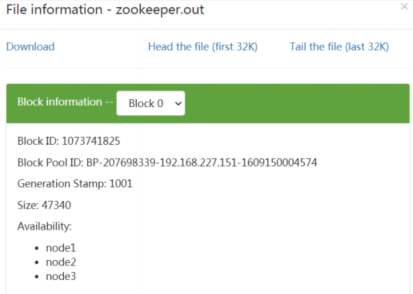
hadoop fs -put zookeeper.out /alvin
hadoop fs -put file:///etc/profile hdfs://node1:8020/alvin
- 查看HDFS文件内容
hadoop fs -cat <src> ...
读取指定文件全部内容,显示在标准输出控制台。
注意:对于大文件内容读取,慎重。
- 下载HDFS文件
hadoop fs -get [-f] [-p] <src> ... <localdst>
下载文件到本地文件系统指定目录,localdst必须是目录
-f 覆盖目标文件(已存在下)
-p 保留访问和修改时间,所有权和权限。
更多命令可以查看官方文档
https://hadoop.apache.org/docs/r3.3.0/hadoop-project-dist/hadoop-common/FileSystemShell.html
2.web界面操作HDFS
另外一种更简单直观的方式是通过web界面操作HDFS,默认是50070端口,如下图所示:
HDFS的架构
HFDS采用分布式的架构,可能有成百上千的服务器组成,每一个组件都有可能出现故障。因此故障检测和自动快速恢复是HDFS的核心架构目标,下面是HDFS的官方架构图:
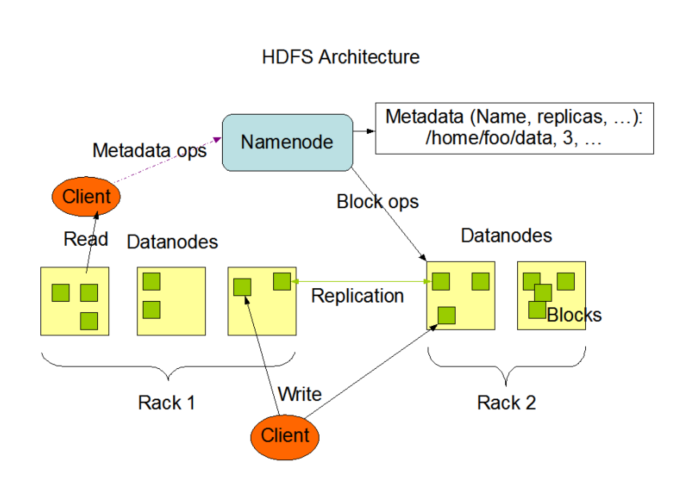
主从架构
HDFS集群是标准的master/slave主从架构集群,一般一个HDFS集群是有一个Namenode和一定数目的DataNode组成。
主角色:NameNode
- NameNode是Hadoop分布式文件系统的核心,架构中的主角色。
- NameNode维护和管理文件系统元数据,包括名称空间目录树结构、文件和块的位置信息、访问权限等信息。
- 基于此,NameNode成为了访问HDFS的唯一入口。
从角色:DataNode
- DataNode是Hadoop HDFS中的从角色,负责具体的数据块存储。
- DataNode的数量决定了HDFS集群的整体数据存储能力,通过和NameNode配合维护着数据块。
主角色辅助角色: SecondaryNameNode
此外,HDFS中还有一个SecondaryNameNode,虽然途中没有画出,那它有什么用呢?
- Secondary NameNode充当NameNode的辅助节点,但不能替代NameNode。
- 主要是帮助主角色进行元数据文件的合并动作。可以通俗的理解为主角色的“秘书”。
分块存储
由于有的文件很大,一台机器也存不下,于是HDFS会对我们的文件做一个物理上的切割,也就是分块存储。
HDFS中的文件在物理上是分块存储(block)的,默认大小是128M(134217728),不足128M则本身就是一块。

副本机制
既然分布式存储海量数据,那么肯定需要成千上百的机器,这样很有可能其中一台机器宕机,出故障了怎么办呢?
当然HDFS也想到了解决方案,文件的所有block都会有副本。副本系数可以在文件创建的时候指定,也可以在之后通过命令改变。副本数由参数dfs.replication控制,默认值是3,也就是会额外再复制2份,连同本身总共3份副本,而且这个副本尽量会分散在不同的机架上,规避风险。

NameNode高可用
既然DataNode有副本,出现数据丢失可能性很小,那NameNode挂了不是照样凉凉?
不用担心,那我在启动一个NameNode备在那里不就行了吗。

存在两个 NameNode,一个是活动的 NameNode,称为 Active,另外一个是备用的 NameNode,称为 Standby。Active节点的数据通过JournalNode节点同步给Standby节点。 当 Active 节点出现问题时,需要将 Standby 节点切换为 Active 节点来为客户端提供服务,这样就保证了高可用。
元数据管理
前面提到NameNode中包含元数据,那么究竟具体是哪些内容呢?
在HDFS中,Namenode管理的元数据具有两种类型:
- 文件自身属性信息
文件名称、权限,修改时间,文件大小,复制因子,数据块大小。
- 文件块位置映射信息
记录文件块和DataNode之间的映射信息,即哪个块位于哪个节点上。
总结
现在你终于知道为什么百度网盘可以存下海量的数据了吧,主要采用的是分布式的存储,将数据分块多副本的方式存储到多个数据节点DataNode, 然后由唯一的NameNode节点去管理这个文件的信息,比如说它是在那些DataNode节点上,大小是多少等等,注意这里是DataNode主动告诉NameNode它这里有哪些文件块。
如果本文对你有帮助的话,请留下一个赞吧
欢迎关注个人公众号——JAVA旭阳
更多学习资料请移步:程序员成神之路
智能推荐
[常用办公软件] wps怎么自动生成目录?wps自动生成目录的设置教程_wps目录自动生成-程序员宅基地
文章浏览阅读1.1w次,点赞3次,收藏5次。转载请说明来源于"厦门SEO"本文地址:http://www.96096.cc/Article/160880.html常用办公软件 WPS Office是由金山软件股份有限公司开发的一款针对个人永久免费的办公软件,在我们的日常生活和工作中,WPS Office比起微软Microsoft Office来说在文字上的处理会更深入国人用户的人心,熟悉操作WPS的办公小技巧,能够更高效的提高我们的工作效率,今天小编要为大家分享的是WPS怎么自动生成目录?快来一起看看WPS自动生成目录的设置教程吧。_wps目录自动生成
web项目-程序员宅基地
文章浏览阅读7.4k次,点赞2次,收藏19次。web项目是指服务端部署在服务器上,客户端使用浏览器通过网络传输进行访问获取数据的项目。通常我们看见的应用页面网站等等都可以称之为web项目。 在web项目的开发中可分为web前端开发和web后端开发 web前端:即是客户端能看得见碰得着得东西。包括Web页面结构、页面样式外观以及Web层面得交互展现。 前端特点:页面视觉效果良好(客户第一)、Web页面交互流畅(..._web项目
关于java操作excel导入导出三种方式_java导出excel的三种方法-程序员宅基地
文章浏览阅读5.6k次,点赞8次,收藏67次。java操作关于导入导出Excel的多种方式_java导出excel的三种方法
Windows系统环境变量path详解_windows path-程序员宅基地
文章浏览阅读1.1w次,点赞10次,收藏21次。Windows path系统变量编辑_windows path
Hadoop基础教程-第13章 源码编译(13.2 Hadoop2.7.3源码编译)_hadoop2.7.3-src源码下载-程序员宅基地
文章浏览阅读512次。第13章 源码编译13.2 Hadoop2.7.3源码编译13.2.1下载Hadoop源码包(1)到官网http://hadoop.apache.org/releases.html下载2.7.3的source源码包(2)解压缩tar -zxvf hadoop-2.7.3-src.tar.gz -C /opt1(3)打开解压目录下的BUILDING.txt,编译过程和需要的软件其实就是根据这个文档里..._hadoop2.7.3-src源码下载
Latex 语法_\latex-程序员宅基地
文章浏览阅读1k次。Latex 语法_\latex
随便推点
【智能排班系统】基于AOP和自定义注解实现接口幂等性-程序员宅基地
文章浏览阅读884次。使用多种方式实现接口幂等性,通过定义注解方便对方法进行幂等性控制
SpringBoot整合Swagger2 详解_springboot swagger2 开关-程序员宅基地
文章浏览阅读324次。SpringBoot、Swagger2 整合详解_springboot swagger2 开关
spring boot 项目报错 java.sql.SQLException: The server time zone value '�й���ʱ��' is unrecognized_springboot项目里面报错 the server time zone value ' й-程序员宅基地
文章浏览阅读2.8w次,点赞96次,收藏115次。报错说是时区不对因为mysql-connection-java版本导致时区的问题。pom.xml:控制台报错信息:java.sql.SQLException: The server time zone value ‘�й���ʱ��’ is unrecognized or represents more than one time zone. You must configure ei..._springboot项目里面报错 the server time zone value ' й
最全Android Kotlin 学习路线(Kotlin 从入门、进阶到实战)_kotlin学习-程序员宅基地
文章浏览阅读4.2k次。Kotlin 是由 jetBrains 开发的一门现代多平台应用的静态编程语言,Kotlin 代码即可以编译成 Java 字节码,又可以编译成 JavaScript,Kotlin 是开源的,源码在这。Kotlin 包含了大量的语法糖,在编码的时候,会大大的简化我们的代码量及工作效率。且相比传统的 Java 语言,Kotlin 种大量的简写,可以减少很多用Java 必须要写的样板代码,减少大量的 if…else 等嵌套,减少大量接口的实现,代码结构也会更加清晰。_kotlin学习
【前端素材】推荐优质新鲜绿色蔬菜商城网站设计Harmic平台模板(附源码)-程序员宅基地
文章浏览阅读753次,点赞30次,收藏21次。在线绿色新鲜果蔬商店网站是指一个专门销售新鲜、绿色、有机水果和蔬菜的电子商务平台。这类网站旨在为消费者提供方便、快捷的购买渠道,同时确保他们能够购买到高质量、新鲜的产品。
elementui表格添加fixed之后样式异常_element table fixed 样式异常-程序员宅基地
文章浏览阅读1k次。最近写项目碰到一个bug 大概就是一个表格组件两个页面都会使用 组件中表格的某些列就用v-if控制了 表格的首尾列都用了fixed 然后就发生了bug 如下图 具体原因不明看过很多网上的办法 有在fixed的列绑定key的 也有使用doLayout()的 测了都没用 最后在一个前端交流群里一位大佬给出的办法 实测有效.el-table__header, .el-table__body, .el-table__footer { width: 100%; tab_element table fixed 样式异常