python 处理json数据_python处理json-程序员宅基地
技术标签: python 地图 学习笔记 json Python
python 处理json数据
1. json数据格式
json的数据格式有2种,分别是:
对象(object):用大括号{}表示;
数组(array):用中括号[]表示。
1.1 对象(object)
在json中对象用“键-值”(key:value)方式配对存储,对象内容以“{”开始,以“}”结束,键与值之间以“:”隔开,每组键值对间以逗号“,”隔开。
- 键(key)必须是字符串类型;
- 值(value)可以是数值(number)、字符串(string)、布尔值(bool)、数组(array)或null值。
- json格式中,字符串需用双引号,json文件内不能使用注释
如:{“Name”: “Tom”, “Age”: 18}
1.2 数组(array)
数组由一些列的值(value)组成,以“[”开始,以“]”结束,各个值之间以逗号“,”隔开。
数组的值可以是数值(number)、字符串(string)、布尔值(bool)、数组(array)或null值。
在Python中,json以字符串(string)方式存在。
2. python数据与json数据互转
2.1 将python数据转成json格式
- python与json数据类型对照:
- dict --> object
- list,tuple --> array
- str,unicode --> string
- int,float,long --> number
- True --> true
- False --> false
- None --> null
-
将列表与元组数据转成json数组
import json # 导入json模块 # 1.将列表与元组数据转成json数组 listNumbers = [1, 3, 5, 7, 9] # 列表数据 tupleNumbers = [2, 4, 6, 8, 10] # 元组数据 jsonData1 = json.dumps(listNumbers) # 将列表数据转成json数据 jsonData2 = json.dumps(tupleNumbers) # 将元组数据转成json数据 print(f'列表转json数组:{ jsonData1}') print(f'元组转json数组:{ jsonData2}') print(type(jsonData1)) print(type(jsonData2)) # 列表转json数组:[1, 3, 5, 7, 9] # 元组转json数组:[2, 4, 6, 8, 10] # <class 'str'> # <class 'str'> -
将字典元素组成的列表转成json对象
import json # 导入json模块 # 2.将字典元素组成的列表转成json对象 dict_list = [ { 'Name': 'Tom', 'Age': 19, 'City': 'New York'}, { 'Name': 'Jack', 'Age': 23, 'City': 'London'}, { 'Name': 'Mike', 'Age': 25, 'City': 'Tokyo'} ] json_data = json.dumps(dict_list) # 将列表数据转成json数据 print(json_data) print(type(json_data)) # [{"Name": "Tom", "Age": 19, "City": "New York"}, {"Name": "Jack", "Age": 23, "City": "London"}, {"Name": "Mike", "Age": 25, "City": "Tokyo"}] # <class 'str'> -
dumps()的sort_keys参数
python的字典是无序的数据,使用dumps()将python数据转成json对象时,可以添加sort_keys=True,将转成json格式的对象排序。
import json # 导入json模块 # 3.dumps()的sort_keys参数 """ python的字典是无序的数据,使用dumps()将python数据转成json对象时,可以添加sort_keys=True,将转成json格式的对象排序 """ dict_data = { 'Name': 'Tom', 'Age': 19, 'City': 'New York'} json_data1 = json.dumps(dict_data) # 将列表数据转成json数据 json_data2 = json.dumps(dict_data, sort_keys=True) # 将列表数据转成json数据并排序 print(json_data1) print(json_data2) print(json_data1 == json_data2) print(type(json_data)) # {"Name": "Tom", "Age": 19, "City": "New York"} # {"Age": 19, "City": "New York", "Name": "Tom"} # False # <class 'str'> -
dumps()的ident参数
在将Python的字典数据转成json格式的对象时,可以加上indent设置缩排json对象的键-值,让json对象可以更容易显示。
import json # 导入json模块 # 4.dumps()的ident参数 """ 在将Python的字典数据转成json格式的对象时,可以加上indent设置缩排json对象的键-值,让json对象可以更容易显示 """ dict_data = { 'Name': 'Jack', 'Age': 23, 'City': 'London'} json_data = json.dumps(dict_data, sort_keys=True, indent=4) print(json_data) # { # "Age": 23, # "City": "London", # "Name": "Jack" # }
2.2 将json格式数据转成python数据
json模块中的loads()方法可以将json格式数据转成python数据。
json数据类型与python数据类型对照:
- object --> dict
- array --> list
- string --> unicode
- number(int) --> int,long
- Number(real) --> float
- true --> True
- false --> False
- num --> None
import json
# json数据
json_data = '{"Name": "Jack", "Age": 25, "Gender": "Male"}'
dict_data = json.loads(json_data) # 转成python对象
print(dict_data)
print(type(dict_data))
# {'Name': 'Jack', 'Age': 25, 'Gender': 'Male'}
# <class 'dict'>
3. python处理json文件
3.1 将python数据转成json文件
使用json模块中的dump()方法,可以将python数据转成json文件格式。
# author:mlnt
# createdate:2022/8/18
"""
使用json模块中的dump()方法,可以将python数据转成json文件格式
"""
import json
# 字典数据
dict_data = {
'sno': '1001', 'name': 'Jack', 'score': 80}
filename = 'test1.json'
with open(file=filename, mode='w') as f:
# obj:欲存储为json格式的数据,fp:欲存储的文件对象
json.dump(obj=dict_data, fp=f)

3.2 读取json文件
使用json模块中的load()方法,可以读取json文件,读取json文件的数据将被转换成python的数据格式。
"""
使用json模块中的load()方法,可以读取json文件,读取json文件的数据将被转换成python的数据格式
"""
import json
filename = 'test1.json'
with open(file=filename, mode='r') as f:
data = json.load(f)
print(data)
print(type(data))
# {'sno': '1001', 'name': 'Jack', 'score': 80}
# <class 'dict'>
4. 绘制世界人口地图
-
安装pygal.maps.world模块
pip install pygal.maps.world
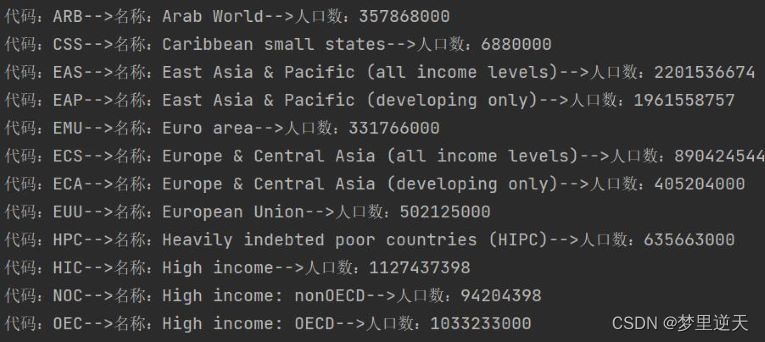
4.1 列出json数据中的人口数据
import json
filename = 'population_data.json'
with open(file=filename) as f:
json_data = json.load(f) # 读取json数据
for data in json_data:
if data['Year'] == '2010': # 筛选2010年的数据
countryName = data['Country Name'] # 国家名称
countryCode = data['Country Code'] # 国家代码
population = int(float(data['Value'])) # 人口数
print(f'代码:{
countryCode}-->名称:{
countryName}-->人口数:{
population}')
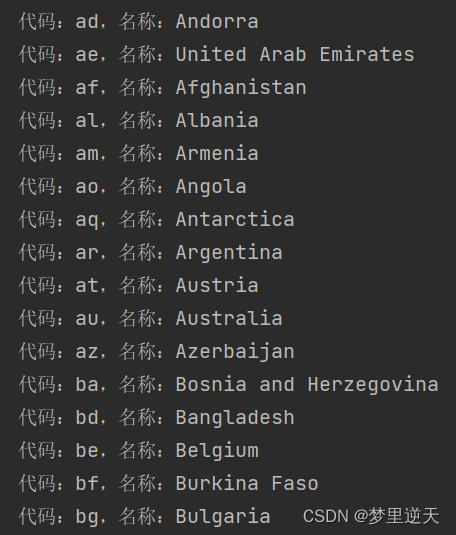
COUNTRIES字典中,国家代码用2个英文字母表示。
from pygal_maps_world.i18n import COUNTRIES
for countryCode in sorted(COUNTRIES.keys()):
# COUNTRIES字典中,国家代码用2个英文字母表示
print(f'代码:{
countryCode},名称:{
COUNTRIES[countryCode]}')
4.2 读取json数据,绘制地图
import json
import pygal_maps_world.maps
from pygal_maps_world.i18n import COUNTRIES
import pygal_maps_world.maps
from pygal.style import RotateStyle
from pygal.style import LightColorizedStyle
def getCountryCode(countryName):
"""根据国家名称获取国家代码"""
for code, name in COUNTRIES.items():
if name == countryName:
return code
return None
filename = 'population_data.json'
with open(file=filename) as f:
# 读取json数据
json_data = json.load(fp=f)
populations = {
} # 创建字典
for data in json_data:
if data['Year'] == '2010':
countryName = data['Country Name']
population = int(float(data['Value']))
code = getCountryCode(countryName)
if code:
populations[code] = population
# 根据人口数量将国家分3组
cc_pop_1, cc_pop_2, cc_pop_3, cc_pop_4, cc_pop_5, cc_pop_6 = {
}, {
}, {
}, {
}, {
}, {
}
for cc, pop in populations.items():
if pop < 10000000:
cc_pop_1[cc] = pop
elif pop < 50000000:
cc_pop_2[cc] = pop
elif pop < 100000000:
cc_pop_3[cc] = pop
elif pop < 300000000:
cc_pop_4[cc] = pop
elif pop < 500000000:
cc_pop_5[cc] = pop
else:
cc_pop_6[cc] = pop
# 加亮颜色主题
word_map_style = RotateStyle('#336699', base_style=LightColorizedStyle)
word_map = pygal_maps_world.maps.World(style=word_map_style)
word_map.title = 'world population in 2010, by country'
# wm.add('2010', populations)
word_map.add('0-10m', cc_pop_1)
word_map.add('10m-50m', cc_pop_2)
word_map.add('50m-100m', cc_pop_3)
word_map.add('100m-300m', cc_pop_4)
word_map.add('300m-500m', cc_pop_5)
word_map.add('>500m', cc_pop_6)
# word_map.render_to_file('world_population.svg')
word_map.render_to_file('world_population.html')
用浏览器打开生成的html文件。

参考:
智能推荐
settext 下划线_Android TextView 添加下划线的几种方式-程序员宅基地
文章浏览阅读748次。总结起来大概有5种做法:将要处理的文字写到一个资源文件,如string.xml(使用html用法格式化)当文字中出现URL、E-mail、电话号码等的时候,可以将TextView的android:autoLink属性设置为相应的的值,如果是所有的类型都出来就是**android:autoLink="all",当然也可以在java代码里 做,textView01.setAutoLinkMask(Li..._qaction::settext 无法添加下划线
TableStore时序数据存储 - 架构篇_tablestore 时间类型处理-程序员宅基地
文章浏览阅读6.3k次,点赞2次,收藏10次。摘要: 背景 随着近几年物联网的发展,时序数据迎来了一个不小的爆发。从DB-Engines上近两年的数据库类型增长趋势来看,时序数据库的增长是非常迅猛的。在去年我花了比较长的时间去了解了一些开源时序数据库,写了一个系列的文章(综述、HBase系、Cassandra系、InfluxDB、Prometheus),感兴趣的可以浏览。背景随着近几年物联网的发展,时序数据迎来了一个不小的爆发。从DB..._tablestore 时间类型处理
Ubuntu20.04下成功运行VINS-mono_uabntu20.04安装vins-mono-程序员宅基地
文章浏览阅读5.7k次,点赞8次,收藏49次。可以编译成功但是运行时段错误查找原因应该是ROS noetic版本中自带的OpenCV4和VINS-mono中需要使用的OpenCV3冲突的问题。为了便于查找问题,我只先编译feature_tracker包。解决思路历程:o想着把OpenCV4相关的库移除掉,但是发现编译feature_tracker的时候仍然会关联到Opencv4的库,查找原因是因为cv_bridge是依赖opencv4的,这样导致同时使用了opencv3和opencv4,因此运行出现段错误。oo进一步想着(1)把vins-mon_uabntu20.04安装vins-mono
TMS320C6748_EMIF时钟配置_tms 6748-程序员宅基地
文章浏览阅读3.6k次,点赞3次,收藏12次。创龙TL6748开发板中,EMIFA模块使用默认的PLL0_SYSCLK3时钟,使用AISgen for D800K008工具加载C6748配置文件C6748AISgen_456M_config(Configuration files,在TL_TMS6748/images文件夹下),由图可以看到DIV3等于4,注意这里的DIV3就是实际的分频值(x),而不是写入相应PLL寄存器的值(x-1)。_tms 6748
eigen稀疏矩阵拼接(基于块操作的二维拼接)的思考-程序员宅基地
文章浏览阅读5.9k次,点赞4次,收藏13次。转载请说明出处:eigen稀疏矩阵拼接(块操作)eigen稀疏矩阵拼接(块操作)关于稀疏矩阵的块操作:参考官方链接 However, for performance reasons, writing to a sub-sparse-matrix is much more limited, and currently only contiguous sets of columns..._稀疏矩阵拼接
基于Capon和信号子空间的变形算法实现波束形成附matlab代码-程序员宅基地
文章浏览阅读946次,点赞19次,收藏19次。波束形成是天线阵列信号处理中的一项关键技术,它通过对来自不同方向的信号进行加权求和,来增强特定方向的信号并抑制其他方向的干扰。本文介绍了两种基于 Capon 和信号子空间的变形算法,即最小方差无失真响应 (MVDR) 算法和最小范数算法,用于实现波束形成。这些算法通过优化波束形成权重向量,来最小化波束形成输出的方差或范数,从而提高波束形成性能。引言波束形成在雷达、声纳、通信和医学成像等众多应用中至关重要。它可以增强目标信号,抑制干扰和噪声,提高系统性能。
随便推点
Ubuntu好用的软件推荐_ubuntu开发推荐软件-程序员宅基地
文章浏览阅读3.4w次。转自:http://www.linuxidc.com/Linux/2017-07/145335.htm使用Ubuntu开发已经有些时间了。写下这篇文章,希望记录下这一年的小小总结。使用Linux开发有很多坑,同时也有很多有趣的东西,可以编写一些自动化脚本,添加定时器,例如下班定时关机等自动化脚本,同时对于服务器不太了解的朋友,建议也可以拿台Linux来实践下,同时Ubuntu在Androi_ubuntu开发推荐软件
Nginx反向代理获取客户端真实IP_nginx获取到的是交换机的ip-程序员宅基地
文章浏览阅读2.2k次。一,问题 nginx反向代理后,在应用中取得的ip都是反向代理服务器的ip,取得的域名也是反向代理配置的url的域名,解决该问题,需要在nginx反向代理配置中添加一些配置信息,目的将客户端的真实ip和域名传递到应用程序中。二,解决 Nginx服务器增加转发配置 proxy_set_header Host $host;_nginx获取到的是交换机的ip
Wireshark TCP数据包跟踪 还原图片 WinHex应用_wireshark抓包还原图片-程序员宅基地
文章浏览阅读1.4k次。Wireshark TCP数据包跟踪 还原图片 WinHex简单应用 _wireshark抓包还原图片
Win8蓝屏(WHEA_UNCORRECTABLE_ERROR)-程序员宅基地
文章浏览阅读1.5k次。Win8下安装VS2012时,蓝屏,报错WHEA_UNCORRECTABLE_ERROR(P.S.新的BSOD挺有创意":("),Google之,发现[via]需要BIOS中禁用Intel C-State,有严重Bug的嫌疑哦原因有空再看看..._win8.1 whea_uncorrectable_error蓝屏代码
案例课1——科大讯飞_科大讯飞培训案例-程序员宅基地
文章浏览阅读919次,点赞21次,收藏22次。科大讯飞是一家专业从事智能语音及语音技术研究、软件及芯片产品开发、语音信息服务的软件企业,语音技术实现了人机语音交互,使人与机器之间沟通变得像人与人沟通一样简单。语音技术主要包括语音合成和语音识别两项关键技术。此外,语音技术还包括语音编码、音色转换、口语评测、语音消噪和增强等技术,有着广阔的应用。_科大讯飞培训案例
perl下载与安装教程【工具使用】-程序员宅基地
文章浏览阅读4.7k次。Perl是一个高阶程式语言,由 Larry Wall和其他许多人所写,融合了许多语言的特性。它主要是由无所不在的 C语言,其次由 sed、awk,UNIX shell 和至少十数种其他的工具和语言所演化而来。Perl对 process、档案,和文字有很强的处理、变换能力,ActivePerl是一个perl脚本解释器。其包含了包括有 Perl for Win32、Perl for ISAPI、PerlScript、Perl。_perl下载